
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ShadowMap
- SGPR
- texture
- Graphics
- DirectX12
- scattering
- UE5
- Nanite
- deferred
- Shadow
- vulkan
- atmospheric
- scalar
- Wavefront
- Study
- optimization
- ue4
- VGPR
- RayTracing
- shader
- rendering
- GPU
- GPU Driven Rendering
- unrealengine
- forward
- SIMD
- wave
- DX12
- hzb
- 번역
- Today
- Total
RenderLog
[번역] Bindless Texturing for Deferred Rendering and Decals 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 :https://therealmjp.github.io/posts/bindless-texturing-for-deferred-rendering-and-decals/

https://github.com/TheRealMJP/DeferredTexturing
https://github.com/TheRealMJP/DeferredTexturing/releases (Precompiled Binaries)
To Bind, or Not To Bind
지난 1년간 코마상태에 빠진 게 아니면, PC와 모바일에서 사용가능한 새로운 그래픽스 API에 대한 소문과 흥분되는 일들이 있는 것을 알았을 것입니다. D3D12 그리고 Vulkan 이 가져온 큰 변화중 하나는 지금까지 계속해서 사용해 오던 리소스 바인딩을 위한 오래된 슬롯 기반 시스템을 버린 것입니다. 오래된 시스템 대신에, 이 두 API 는 GPU 접근 가능한 연속된 메모리에 opaque resource descriptors 를 배치하는 것을 기반으로 한 새로운 모델[1] 을 채택했습니다. 새 모델은 더 효율적일 수 있는 잠재력을 갖고 있습니다, 왜냐하면 수많은 하드웨어 (특히 AMD 의 GCN 기반 GPU)는 그들의 descriptor 를 물리 레지스터에 보관하는 것 대신에 메모리에서 바로 읽을 수 있습니다. 그래서 드라이버가 슬롯 기반 모델을 채택하고 적절한 descriptors 를 쉐이더가 사용할 수 있는 테이블에 두기 위해서 뒤에서 기계적인 작업을 수행하는 대신에 , 그 앱은 그냥 descriptors 를 처음부터 바로 작동하는 레이아웃에 둘 수 있습니다.
GPU 에 리소스를 제공하는 새로운 스타일은 종종 “bindless” 로 불립니다, 왜냐하면 더 이상 명시적으로 텍스쳐나 버퍼를 dedicated API 함수를 통해 바인딩해야 한다는 제약이 없기 때문입니다. “bindless” 라는 용어는 원래 Nvidia 에서 나왔습니다, 이것은 NV_bindless_texture[3] 라는 OpenGL 확장을 통해서 처음 소개된 개념[2]입니다. 그들의 자료는 표준 리소스 바인딩을 건너뛰게 하여 CPU 오버헤드 크게 줄이는 것을 보여줍니다, 그리고 대신에 그 앱이 64-bit descriptor 핸들(대부분 실제로는 descriptor 의 포인터일 수 있음)을 Uniformbuffer 의 내부에 두도록 합니다. Nvidia bindless 와 D3D/Vulkan bindless 사이의 한 가지 주요 차이점은 새로운 API 는 descriptor 핸들을 단순히 const/uniform buffer 내부에 두도록 허용하지 않는다는 것입니다. 대신에, 그들은 쉐이더를 위해 어떻게 당신의 descriptor 테이블을 구성할 것인지를 수동으로 명세(root signature 로)하기를 요구합니다. 그것은 Nvidia extension 보다 더 복잡하게 보일 수 있습니다, 그러나 이렇게 하는 것은 큰 장점이 있습니다: D3D12 가 메모리로 부터 descriptor 를 가져오는 것을 지원하지 않는(또는 제한적으로 지원하는) 하드웨어를 여전히 지원하게 해 줍니다. 또한 HLSL 에서 unbounded texture arrays 를 통해서 Nvidia 스타일의 bindless 를 완전히 제공합니다. Unbounded arrays 를 사용하면 잠재적으로 하나의 거대한 테이블에 당신의 모든 descriptor 를 둘 수 있습니다. 그러고 나서 root constants/constant buffers/structured buffers/etc 로부터 그 배열을 인덱싱 합니다. 이것은 기본적으로 Nvidia 접근에서 “handle” 을 integer 와 같은 것으로 다룰 수 있게 해 줍니다, 추가 이점으로는 실제로 전체 64 bit integer 를 저장할 필요는 없다는 것입니다. 이것이 정말 효율적일 수 있다는 것뿐 아니라 GPU 에서 생성된 값을 사용하여 fetch 할 텍스쳐를 결정하는 새로운 렌더링 기술로의 문이 열어줍니다.
Deferred Texturing
Bindless texture 에 대한 한 가지 사용예는 deferred texturing 입니다. 개념은 꽤 단순합니다: 쉐이딩에 필요한 모든 머터리얼 파라메터를 포함하는 G-Buffer 기록하는 것 대신에, 당신은 보간 된 UV 와 Material ID 를 기록합니다. 그런 뒤 deferred pass 동안 당신의 Material ID 를 어떤 텍스쳐를 샘플해야 되는지 찾는 데 사용합니다, 그리고 G-Buffer 에서 얻은 UV로 샘플링합니다. 주요 이점은 당신의 텍스쳐가 샘플링되는 것은 오버드로우나 quad packing 걱정 없이 오직 보이는 픽셀에 대해서만 수행된다는 것을 보장합니다. 당신의 접근법에 따라서, 모든 머터리얼 파라메터를 밀어 넣지 않아도 되기 때문에 당신은 G-Buffer 공간을 아낄 수도 있을 것입니다. 실제로 당신은 UV 와 Material ID 보다 더 많은 것이 필요할 수 있습니다. Normal mapping 에서는 전체 tangent frame 이 필요합니다, 이것은 최소한 한 개의 쿼터니언을 필요로 합니다. Mipmap 과 anisotropic 필터링에 대해서, 스크린 스페이스 UV 의 derivatives(역주 : ddx, ddy) 가 필요합니다. 이것은 픽셀 쉐이더에서 계산할 수 있고 G-Buffer 에 명시적으로 기록됩니다, 또는 당신이 가끔 발생하는 artifact 가 괜찮다면, G-Buffer로 부터 계산할 수 있습니다. Nathan Reed 는 G-Buffer 레이아웃에 대한 다양한 가능성에 대한 멋진 글[4]을 그의 블로그에 썻습니다, 그래서 몇 가지 세부사항을 위해서 그의 글을 읽어보는 것을 추천합니다.
Bindless 가 도움을 주는 곳은 디퍼드 라이팅 단계를 하는 동안 머터리얼 텍스쳐를 실제로 샘플링하는 곳입니다. 당신의 모든 텍스쳐 descriptors 를 한 개의 큰 배열에 두어서, 라이팅 패스는 임의의 주어진 머터리얼을 위해 텍스쳐를 샘플링하기 위해서 그 배열을 인덱싱할 수 있습니다. 당신이 필요한 것은 머터리얼 ID → 텍스쳐 인덱스 간의 간단한 매핑이 전부입니다, 이것으로 당신은 structured buffer 로의 인덱싱을 수행할 수 있습니다. 물론 이 작업을 시작하기 위해 반드시 bindless 가 필요한 것은 아닙니다. 만약 당신이 모든 텍스쳐를 큰 텍스쳐 배열에 채우고 싶다면, D3D10-level 하드웨어에서 같은 것을 얻을 수 있을 것입니다. 또는 만약 당신이 virtual mapping 을 사용한다면, 이미 모든 것을 큰 텍스쳐 아틀라스로 부터 가져오기 때문에 구현하는 것은 꽤 간단할 것입니다. 사실, virtual mapping 접근법은 이미 출시된 게임에서 사용되어 왔습니다, 그리고 작년 SIGGRAPH[5][6]에서 설명되었습니다. 거기서, bindless 접근법은 아마도 가장 실행하기 쉽고 기존 파이프라인과 에셋의 제약 또한 최소화합니다.
Go Go Gadget D3D12!
내 샘플 framework 의 새로운 D3D12 버젼을 테스트하는 방법으로, deferred texturing renderer 를 간단히 구현해보기로 결정했습니다. 이것은 D3D12 가 제공하는 새 피쳐에 익숙해지는 좋은 방법처럼 보입니다, 또한 내 샘플 프레임워크의 새로운 버젼이 prime-time 에 준비되어 있는 것을 확인할 수 있을 것으로 보입니다. 더 나은 deferred texturing 구현에 관련된 몇 가지 실제 이슈에 대한 이해도 얻을 수 있을 거라 생각하며, 그 경험을 미래의 프로젝트를 위해서 매력적인 선택이 될지 말지를 평가하기 위해 사용할 수 있길 바랍니다.
여기에 최종적으로 내가 어떻게 내 렌더러를 설정하는지에 대한 간단한 설명이 있습니다.
- lights 와 decals 를 클러스터로 묶기
- 스크린 스페이스에 정렬된 16x16 타일, 선형적으로 분할된 depth 16 타일
- 태양과 Spotlight shadow 렌더링
- 태양에 대해 4개의 2048x2048 cascaded shadow map
- 각 spot light 에 대해서 1024x1024 standard shadow map
- G-Buffer 에 장면 렌더링
- Depth (32bpp)
- Texture coordinates (32bpp)
- Depth gradients (32bpp)
- (Optional) UV gradients (64bpp)
- Material ID (8bpp)
- 7-bit Material index
- 1-bit for tangent frame handedness
- MSAA 가 비활성화 상태면:
- 모든 픽셀에 대해 디퍼드 쉐이딩을 수행하는 deferred compute shader 를 실행함
- G-Buffer 로부터 attribute 를 읽음
- Texture indices 를 얻기 위해서 Material ID 를 사용하고 Descriptor 테이블로 인덱싱을 하기 위해서 인덱스들을 사용함.
- 데칼을 material properties 에 혼합(blend)
- 하늘(sky)을 출력 텍스쳐에 렌더링 하고, depth buffer 를 오클루젼에 사용
- 모든 픽셀에 대해 디퍼드 쉐이딩을 수행하는 deferred compute shader 를 실행함
- MSAA 가 활성화되어 있다면:
- Material ID 를 사용하여 샘플당 쉐이딩이 필요한 “edge” 픽셀을 검출함
- 8x8 타일을 edge 가 있다 or 없다로 분류
- 하늘을 MSAA 렌더타겟 텍스쳐에 렌더링 하고, depth buffer 를 오클루젼에 사용
- Non-edge tiles 을 위한 Deferred compute shader 를 실행하며, 픽셀당 1 서브샘플만 쉐이딩 함.
- Edge tiles 를 위한 Deferred compute shader 를 실행하며, non-edge 픽셀에는 1 서브샘플 쉐이딩 그리고 edge 픽셀에는 모든 서브샘플에 대해 쉐이딩 함
- MSAA 서브 샘플들을 non-MSAA texture 로 Resolve 합니다.
- Post-processing
- Present
품질과 성능을 평가하기 위한 다른 기준점을 갖기 위해서, 나는 deferred renderer 와 함께 clustered forward[8] 을 구하기로 결정했습니다:
- 라이트를 클러스터로 묶음 (화면 공간에 정렬된 16x16 타일, 선형적으로 분리된 depth 16 타일)
- 태양과 spotlight shadow 렌더링
- Full shading 으로 장면을 렌더링
- 머터리얼 텍스쳐에서 읽음
- 데칼을 material properties 에 혼합(blend)
- Sunlight 그리고 spotlight 적용
- MSAA 가 켜져 있으면
- MSAA 서브샘플을 non-MSAA 텍스쳐로 Resolve
- Post-processing
- Present
Light Clustering/Binning
이미 눈치채셨겠지만, 나는 deferred 와 forward 패스에 대해 동일한 라이트를 묶기 위해서 클러스터 접근법을 사용합니다. 라이트 선택을 위한 두 가지 다른 접근법을 가지는 것보다 간단하고 성능을 비교할 때 이런 방정식을 빼는 것이 더 공정하게 보였습니다. 그러나 당신은 deferred texturing 을 사용할 때, 라이트를 묶기 위해 사용하는 어떠한 접근법이라도 사용할 수 있습니다. 예로 다음과 같은 것이 있습니다, classic light bounds rasterization/blending or tile-based subfrustum culling[9].
실제 비닝(묶기) 작업을 구현하기 위해, SIGGRAPH 2013 에서 Emil Persson’s excellent presentation[8] 이 설명한 것과 유사한 설정을 사용했습니다. 만약 당신이 익숙하지 않다면, 기본 아이디어는 뷰 프러스텀을 스크린공간 XY와 Z axis 기준으로 서브 프러스텀 를 자릅니다. 이것은 perspective projection 모양의 프러스텀의 내부에 딱 맞게 둘러싸여 있는 것을 제외하면, 결국 voxel grid 와 같이 보일 것입니다. 이것은 실제로 서브 프러스텀 을 depth buffer 에 맞추는 대신 Z 를 따라 버킷(bucket)을 만드는 것을 제외하면, tiled deferred or Forward+[10] 렌더링과 꽤 유사합니다. 이것은 forward rendering 을 위해 정말 좋을 수 있습니다, 왜냐하면 넓은 depth 범위를 가진 타일에 대해 과도하게 라이트를 포함하는 것을 피하게 해 주기 때문입니다.
Avalanche engine 은 라이트 비닝을 CPU 에서 하는 것으로 결정했습니다, 이것은 비닝이 depth buffer 에 의존하지 않기 때문에 가능합니다. CPU 에서의 비닝은 많은 의미를 가지게 됩니다, 왜냐하면 일반적인 컬링을 위한 GPU 접근법은 thread 와 thread group 에 걸쳐 수많은 추가 연산을 가지기 때문입니다. Intel’s Clustered Forward Shading sample[11] 에서 보여준 것처럼, CPU 병렬화를 통하여 꽤 빠르게도 할 수 있습니다.
나 자신의 구현에서는 GPU 로 하기로 결정했고, 다른 접근법을 사용하기로 했습니다. Forward+ 스타일 렌더러를 사용하여 발매해 오면서, 나는 컴퓨트 쉐이더에서 평면(plane) 기반 컬링 정책을 사용한 일반적인 서브 프러스텀 을 사용한 결과에 꽤 실망했습니다. 프러스텀 컬링을 위한 평면/볼륨 테스트의 dirty secret[12]은 그들이 실제로 오탐지(false positive) 를 꽤 취약하다는 것입니다. “표준” 테스트는 당신의 바운딩 볼륨이 하나 또는 그 이상의 프러스텀의 평면들에 대해서 완전히 잘못된 쪽에 있는 경우에 제외시킬 수 있습니다. 불행히도 이것은 바운딩 볼륨이 프러스텀의 바깥 지점에서 있는 여러 평면과 교차하는 경우 실패한다는 의미입니다. 더 안타까운 것은 이 특별한 경우는 당신의 바운딩 볼륨이 프러스텀에 비해서 더 커지는 경우 가능성이 높아집니다. 일반적으로 이런 경우는 라이트를 서브 프러스텀에 테스트하는 경우입니다. Spotlights 는 이런 경우 특히 좋지 않습니다, 왜냐하면 넓은 부분이 실제로 좁은 꼭지점 바깥에 서브 프러스텀의 평면에 자주 교차하기 때문입니다:
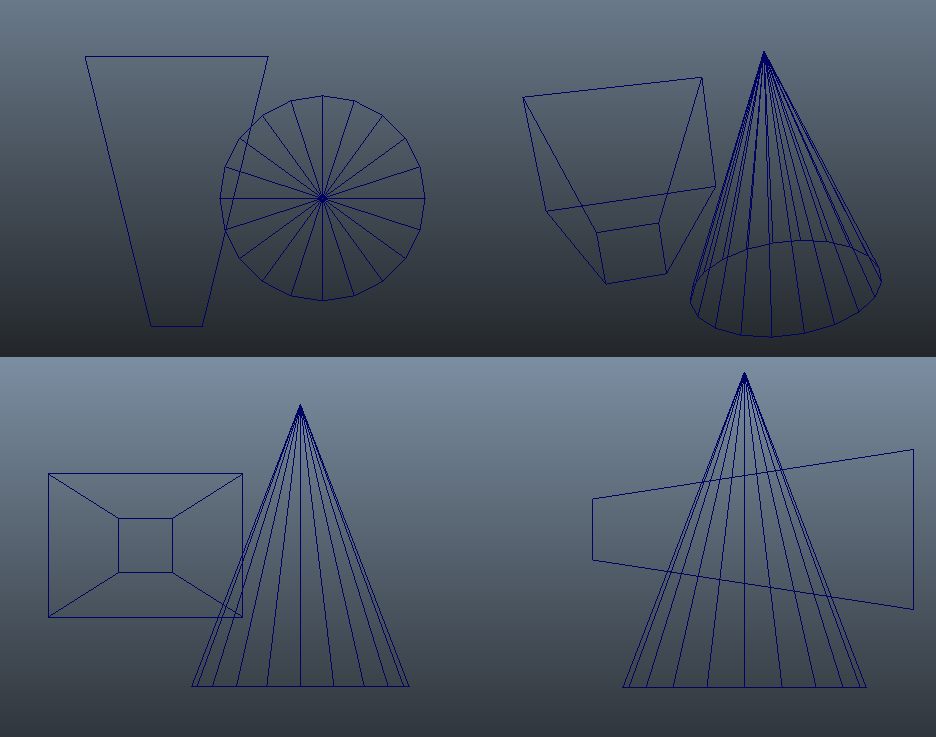
우상단 이미지는 3D perspective view 를 보여줍니다, 여기서 당신은 cone 이 실제로 프러스텀과 교차하지 않은 것을 명백히 볼 수 있습니다. 그러나 만약 당신이 orthographic view 로 본다면, cone 은 프러스텀의 오른쪽 평면의 양쪽에 있는 것을 볼 수 있습니다. 실제로, 다음과 같은 결과를 얻을 것입니다 (초록색으로 컬러링 된 타일은 spotlight 와 “교차” 한 곳입니다.):

당신이 보는 것처럼, 결국 상당한 수의 오탐지(false positive)를 할 수 있습니다. 사실 우리는 오른쪽을 향해 cone 를 감싸고 있는 스크린에 정렬된 AABB 를 채우고 있습니다, 그것은 픽셀들에 대한 많은 작업의 낭비로 변합니다.
The Order 에서 이것이 나를 미치게 만들었습니다, 왜냐하면 우리의 라이팅 아티스트는 대형 그림자를 캐스팅 하는 Spotlight 로 가득찬 레벨을 만드는 것을 좋아했기 때문입니다. CPU 측에서, 나는 쉐도우를 케스팅하는 Spotlight 에 대해서 값비싼 프러스텀-프러스텀 테스트에 의존해야 할 것입니다, 이것은 당신이 전체 쉐도우맵을 컬링 하여 CPU와 GPU 의 많이 시간을 절약할 수 있을 때 말이 됩니다.
불행히도 프러스텀/프러스텀 은 GPU 에서 수행되는 tiled subfrustum culling 을 위한 현실적인 옵션이 아닙니다, 그래서 “중요한” 라이트를 위해 나는 바운딩 cone 의 레스터라이제이션을 통해 생성된 2D 마스크로 교차 테스트를 강화하였습니다. 결과는 꽤 나아졌습니다:

이 데모를 위해서, 나는 The Order 에서 했던 것을 Z 버킷으로 비닝 하여 3D 로 옮기기로 결정했습니다. Z 에서 비닝은 약간 까다롭습니다, 당신은 궁극적으로 당신의 프러스텀의 projected space 를 제외하고 solid voxelization과 동일한 것을 원하기 때문입니다. projected space 에서의 작업은 몇 가지 공통 voxelization 트릭을 제외합니다, 그리고 나는 간단한 2 패스 접근법을 하기로 했습니다. 첫 번째 패스는 라이트 지오메트리의 후면을 렌더링 합니다, 그리고 주어진 XY 버킷의 현재 삼각형과 교차하는 가장 먼 Z 버킷에 삼각형 라이트의 비트를 마킹합니다(각 클러스터는 활성 라이트의 비트필드를 저장합니다), 나는 depth gradient 를 얻기 위해서 픽셀 쉐이더의 derviatives 를 사용합니다, 그런 뒤 픽셀의 코너에서 최대 depth 를 계산합니다. 이것은 보통 잘 작동합니다, 그러나 depth gradient 가 커지면, 삼각형에서 떨어지는 것을 추정하는 것이 가능합니다.(This generally works OK, but when the depth gradient is large it’s possible to extrapolate off the triangle.) 이 경우의 데미지를 최소화 하기 위해서, 나는 CPU에서 라이트의 view-space AABB 계산합니다, 그리고 추정된 깊이를 이 AABB 로 클램프 합니다. 후면 패스 후에, 전면을 렌더링합니다. 이번에는, 픽셀 쉐이더가 최소 depth 버킷을 계산합니다, 그런뒤 후면 패스로 마크된 버킷을 만날 때까지 view ray 를 따라 앞으로 이동합니다. 여기에 내 데모의 단일 라이트에 대한 비닝 시각화가 있습니다:

붉은색으로 마킹된 픽셀은 활성화된 라이트가 있는 클러스터에 속하는 곳입니다. 우하단의 삼각형 모양의 UI 는 시각화입니다. 그것은 y=0 에 위치하면 XZ 평면에 대해 활성 클러스터를 보여줍니다. 이것이 Z 에서 클러스터링이 얼마나 잘 작동하는지 보여줍니다, Z 에서 클러스터링 하는 부분이 내 구현에서 에러가 가장 많이 발생하는 곳입니다. 여기 모든 (20개) 라이트가 활성화된 장면을 보여주는 또 다른 이미지입니다:

이 부분을 견고하게 하기 위해, 당신은 conservative rasterization[13]를 사용해야 합니다. 내 데모에 이 옵션이 있지만, 불행하게도 그 피쳐를 지원하는 AMD GPU 는 여전히 없습니다. 대체수단으로, 나는 픽셀 쉐이더가 covered tile 에 대해 실행되지 않을 기회를 줄이기 위해 4x or 8x MSAA 모드를 지원합니다. The Order 에서 나는 8x MSAA 를 사용했습니다, 그리고 실제로 전혀 문제가 되지 않았습니다. 이것은 라이트가 스크린에서 너무 작은 경우가 아니면 문제가 되지 않습니다, 이 경우 바운딩 박스를 대신 레스터라이즈 할 수 있습니다. 나는 내 구현의 depth buffer 가 비닝 프로세스를 가속하기 위해서 or 더 최적화된 분포의 Z 버킷을 생성하기 위해서 사용되지 않는 것을 지적해야만 합니다. 나는 forward rendering 패스에서 Z prepass 활성화 여부에 따라 추가 성능 차이가 발생하지 않는 방식으로 구현했습니다.
The G-Buffer
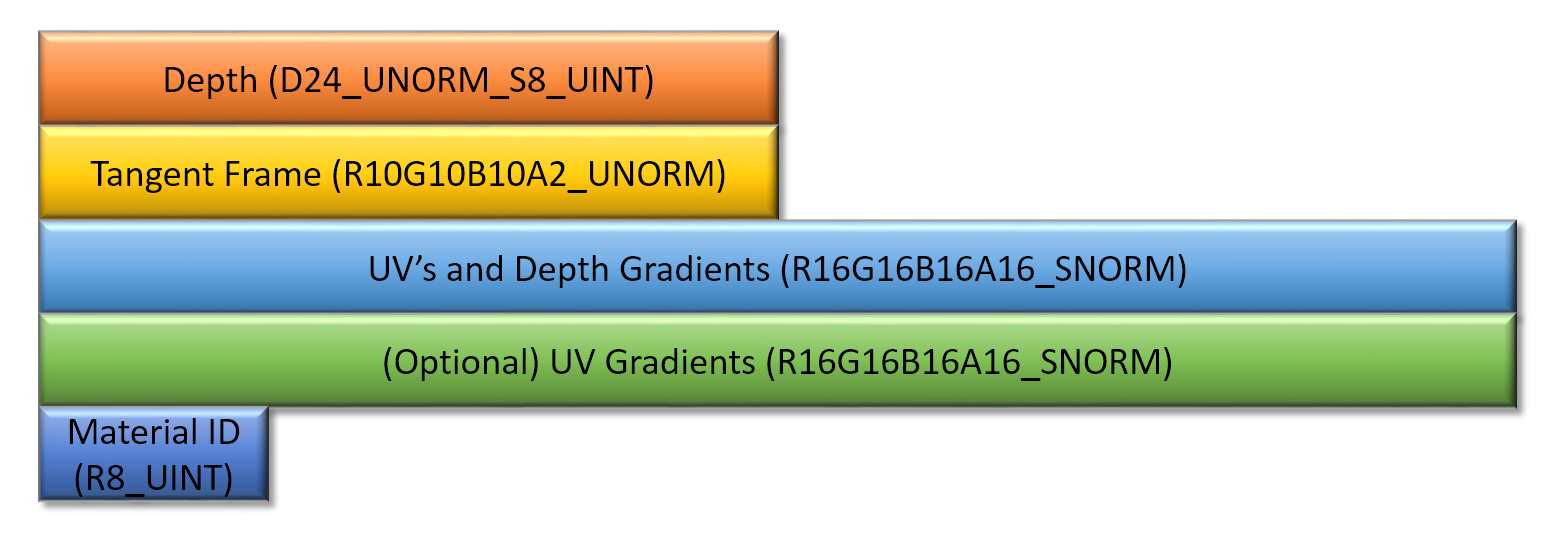
렌더링을 위해서, 디퍼드 패스에서 적절한 텍스쳐를 찾기 위해 사용하는 Material ID 뿐 아니라 버택스 데이터로 부터 오는 정보들을 G-Buffer 에 저장해야 합니다. 버택스 정보 관점에서, 텍스쳐 샘플링과 노멀매핑을 수행하기 위해서 trangent frame 과 UV 가 필요합니다. 만약 우리의 trangent frame 이 orthonormal 기반이면, 우리는 쿼터니언을 사용하여 꽤 압축할 수 있습니다. R16G16B16A16_SNORM 는 이런 경우에 딱 맞습니다, 왜냐하면 그것은 예상하는 범위를 다루며 좋은 정밀도를 제공합니다. 그러나 만약 더 작게 하고 싶다면(그리고 우리는 원합니다!), 우리는 그것을 텍셀당 4 bytes 로줄일 수[7] 있습니다. UV 는 16-bit UNORM 포맷에 저장됩니다, 이 타입은 ract(UV) 가 0과 1 사이로 유지되는 한 충분한 정밀도를 제공합니다. UV 와 동일한 텍스쳐에 스크린스페이스 depth gradient 를 Z 와 W 에 저장합니다. 이후에 스크린스페이스 UV gradient 를 저장하기 위해서 64bpp 텍스쳐 옵션이 있습니다. 그것에 대해서는 다음 섹션에서 논의할 것입니다. 최종적으로, G-Buffer 는 Material ID 를 위해서 8-bit 텍스쳐를 가집니다. 각 텍셀의 MSB 는 trangent frame 의 handedness bit 입니다, 이것은 쿼터니언으로 부터 그것을 복원할 때, bitangent 를 뒤집는데 사용합니다. 이를 통해 UV gradient 를 저장할 때 샘플당 총 25 bytes, 대신에 그들을 계산할 때는 17 bytes 입니다.
디퍼드 텍스쳐링의 한 가지 이슈는 머터리얼 텍스쳐를 샘플링할 때, 스크린스페이스 UV gradient 를 통해서 자동으로 mip 선택하는 것을 할 수 없는 것입니다. 픽셀 쉐이더에서 계산된 gradient 는 여러개의 삼각형으로 이뤄진 quad 에 대해서 잘작동하지 않을 것입니다, 그리고 컴퓨트 쉐이더에서 그들은 전혀 사용할 수 없습니다. 가장 간단한 해결법은 장면을 G-Buffer 에 렌더링 할 때 픽셀 쉐이더에서 (ddx/ddy 를 사용하여) gradient 를 얻는 것입니다, 그런 뒤 텍스쳐에 이 gradient 를 저장합니다. 불행히도 이것은 4개의 분리된 값을 저장한다는 의미입니다, 16-bit 정밀도를 사용할 때 픽셀당 8 byte 추가 데이터를 요구합니다. 만약 당신이 positional gradient 를 디퍼드 패스 하는동안 필요로 한다면, 그것은 전혀 도움이 안됩니다. positional gradient 는 gobos, decals, filterable shadows or receiver plane shadow bias factor 과 같은 것에 유용할 수 있습니다. World 의 full gradient 이나 뷰스페이스 full position을 저장하는 것은 바보 같을 것입니다, 그러나 다행히도 우리는 depth gradient 를 저장하고 그것을 position gradient 로 복원하기 위해서 사용할 수 있습니다. Depth gradients 는 6개 대신에 2개의 값만 필요로 합니다, 그리고 우리는 floating-point 대신에 16-bit fixed-point 포맷을 사용합니다. 그들은 또한 평면의 표면에 걸쳐 일정하다는 좋은 특성을 가지고 있습니다. 이 속성은 삼각형의 에지를 탐지하는데 유용합니다.
UV 그리고 depth gradient 둘 다 이웃 픽셀로 부터 샘플링된 값을 사용하여 디퍼드 패스에서 계산될 수 있습니다, 그러나 실제로는 그것이 잘 작동하게 하는 것이 다소 까다롭다는 것을 알고 있습니다. “삼각형에서 벗어나지” 않도록 조심해야 합니다, 그렇지 않으면 완전히 관련 없는 메시로부터 UV 를 읽을 수도 있습니다. 물론 당신의 삼각형이 너무 작아서 같은 삼각형의 이웃이 전혀 없다면, 이경우 삼각형을 벗어나는 것 말고는 아무것도 할 수 없을 것입니다. 당신은 fract() 를 사용하여 만들어지는 UV 에 생기는 꿰매진 것 같은 흔적(역주 : 바느질한 것처럼 줄이 생기는 이슈)도 고려해야 합니다.
내 구현에서, 나는 depth gradient (여기서 “depth” 는 depth buffer 에 있는 post-projection z/w 값입니다)를 항상 저장하면서, UV gradient 를 저장하거나 계산하는 옵션을 지원합니다. 이 방식으로 하는 것은 UV gradient 계산을 위해서 알맞는 이웃 픽셀을 찾으려 할 때 depth gradient 를 활용하게 해줍니다, 그리고 또한 내가 고품질의 positional gradient 를 가질 수 있게 보장해 줍니다, 나는 이웃이 같은 삼각형 또는 동일평면 삼각형(coplanar triangle) 이라는 것을 비교적 확신할 수 있었습니다. 만약 관심 있다면, 이 단계를 위한 쉐이더 코드는 여기에서 찾을 수 있습니다.
품질을 평하기 위해서, 포워드 렌더링 동안 ddx/ddy 를 사용할 때 UV gradient 가 어떻게 보이는지 보여주는 비주얼라이제이션을 봅시다:

그리고 여기의 이미지는 계산된 UV gradient 가 어떻게 보이는지를 보여주고 있습니다:

보시다시피 내 알고리즘이 이웃을 찾는데 실패하는 위치(이런 픽셀은 검은색입니다), 그리고 이웃 픽셀을 전혀 사용해서는 안 되는 위치(이런 픽셀은 밝습니다)가 꽤 있습니다. 나는 더 많은 시간과 영리함으로 결과를 개선할 수 있다고 확신합니다만 완료된 작업양이 처음에 gradient 를 작성하는 비용을 상쇄하기 충분하다는 점을 주의해야만 합니다. 내 GTX 970 에서 MSAA 가 비활성화되었을 때, gradient 를 계산하는 것보다 저장하는 것이 실제로 더 빠릅니다, 그러나 MSAA 를 켜면 반대로 전환됩니다.
Sebastian 의 발표[5] 에서 언급한 내용에서는 구현 시(페이지 45를 보세요)에서 UV gradient 를 복원했다는 점은 주목할 가치가 있습니다, 비록 당신은 비교 이미지에서 삼각형 에지 주위에서 몇몇 artifact 를 볼 수 있지만요. 그들은 이웃을 찾기 위해서 “UV distance” 를 사용합니다고 언급했습니다. 이것은 virtual texturing 을 위한 유니크 UV 를 가진다는 것을 고려하면 말이 됩니다.
Non-MSAA Shading
non-MSAA 렌더링에서, 디퍼드 패스는 꽤 단순합니다. 먼저, G-Buffer 속성들을 텍스쳐로부터 읽어 들이고 원본 픽셀 포지션과 gradient 를 계산에 사용됩니다. UV gradient 가 있으면 G-Buffer 로 부터 읽어들이고 그렇지 않으면 이웃 픽셀에서 계산합니다. G-Buffer 로 부터의 Material ID 는 structured buffer 로의 인덱싱에 사용됩니다. 이 structured buffer 는 머터리얼 당 한 개의 요소를 포함합니다, 여기서 각각의 요소들은 머터리얼 텍스쳐들(albedo, normal, roughness, and metallic)을 위한 descriptor 인덱스들을 포함합니다. 이런 인덱스들은 큰 descriptor 테이블로 인덱싱 하는 데 사용됩니다. 그 테이블은 장면의 모든 텍스쳐에 대한 descriptor 를 포함하여 픽셀의 UV 좌표와 derivatives 를 사용하여 적절한 텍스쳐가 샘플링될 수 있게 합니다.
모든 표면과 머터리얼 파라메터를 읽었다면, 실제로 쉐이딩을 수행하는 함수로 전달됩니다. 이 함수는 픽셀의 XYZ 클러스터에 묶인 모든 라이트에 대해 반복해서 작업할 것입니다, 그리고 각 라이트 소스의 반사율을 계산합니다. 이것은 표면 BRDF 평가를 요구합니다, 그리고 가시성 텀을 적용합니다. 이 가시성 텀은 라이트의 1024x1024 shadow map 로 부터 옵니다. Shadow map 은 GatherCmp 명령을 사용하는 최적화된 unrolled loop로 구현된 7x7 PCF 커널로 샘플링됩니다. 이것은 ALU 작업에 너무 편향되지 않고, 당신이 실제 게임에서 보게 될 작업부하를 어느 정도 대표할 수 있습니다. 나의 장면의 태양은 디렉셔널 라이트가 됩니다, 이것은 가시성을 위해서 4 개의 2048x2048 cascaded shadow map 을 사용합니다. 최종적으로, ambient 텀은 skydome 으로 부터의 radiance 를 나타내는 SH 계수의 세트의 평균으로 적용됩니다.
MSAA Edge Detection and Tile Classification
다른 종류의 디퍼드 렌더링과 마찬가지로, MSAA 는 특별한 주의가 필요합니다. 특히 디퍼드 패스 동안 각 서브샘플을 쉐이딩 할 수 있도록, 어떤 픽셀이 여러 개의 유니크 서브샘플을 포함하는지를 결정해야 합니다. 핵심 이슈는 스케쥴링입니다: 서브샘플 쉐이딩을 요구하는 “에지” 픽셀은 일반적으로 스크린스페이스에서 꽤 듬성듬성 할것입니다, 이런 점이 다이나믹 브랜칭이 잘 맞지 않게 만듭니다. “old-school” 스케쥴링 방식은 에지 픽셀로 부터 stencil mask 를 생성하는 것입니다, 그런뒤 두개의 픽셀 쉐이더 패스를 렌더링합니다: 한 패스는 픽셀당 쉐이딩을 위한 패스, 다른 패스는 샘플당 빈도수(per-sample frequency)로 수행하는 쉐이더를 실행하는 샘플당 쉐이딩을 위한 패스입니다. 이것은 브랜치 보다 더 나을 수 있습니만 에지 픽셀의 희소성 때문에 여전히 하드웨어는 특별하게 잘 스케쥴링 할 수 없을 것입니다. 쉐이더가 2x2 quad 로 실행되는지 확인해야 합니다, 이것은 수많은 불필요한 helper executions 을 할 수 있습니다.
에지 픽셀을 스케쥴 하는 “새로운” 방법(”새로운’ 이라는 것은 6 년 전을 의미)은 컴퓨트 쉐이더를 사용하는 것입니다. 그것은 스레드 그룹 내에서 스레드를 다시 스케쥴링합니다. 기본적으로 에지 픽셀을 탐지합니다, 그들의 위치를 스레드 그룹의 shared memory 의 리스트에 추가합니다, 그런 뒤 첫 번째 서브샘플의 쉐이딩이 완료되면 전체 그룹이 리스트를 순회하도록 합니다. 이것은 타일 범위 내에서 에지 픽셀의 희소 리스트를 효과적으로 압축해 주며, coherent looping 과 branching 하게 해 줍니다. 단점은 shared memory 를 사용해야 합니다, 너무 많이 사용하는 경우 당신의 최대 occupancy 를 감소시킬 수 있습니다.
내 샘플에서, 나는 컴퓨트 쉐이더 접근법을 사용합니다만 새로운 변형이 있습니다. 디퍼드 패스에서 에지 탐지를 하는 대신에, 에지 체크 패스를 먼저 실행하고 mask 를 만듭니다. 이 패스는 8x8 리스트를 만들기 위해서 추가버퍼를 사용하며, 에지 픽셀을 포함합니다, 뿐만 아니라 에지가 전혀 없는 타일을 포함하는 분리된 리스트도 포함합니다. 추가된 개수는 ExecuteIndirect 를 위한 indirect 아규먼트로 사용될 수 있습니다, 이것으로 에지와 논에지 타일은 두 개의 다른 쉐이더 퍼뮤테이션을 사용하여 2개의 분리된 dispatch 로 처리될 수 있습니다. 이것은 shared_memory 사용량으로 부터 오는 오버헤드를 최소화하는데 도움을 줍니다, 왜냐하면 컴퓨트 쉐이더의 논에지 버전은 shared_memory 를 전혀 건드리지 않기 때문입니다.
실제 에지 탐지에 대해서, 내 샘플은 2 개의 다른 접근을 지원합니다. 첫 번째 접근법은 Material ID 만 체크하는 것입니다, 그래서 여러 머터리얼 ID 값을 포함하는 픽셀에 플래그를 지정합니다. 이것은 보수적인 접근법입니다, 왜냐하면 서로 다른 머터리얼을 사용하는 메시가 겹친 픽셀에만 플래그를 지정하기 때문입니다. 두 번째 접근법은 더 공격적입니다, 그리고 varying depth gradient 를 추가적인 픽셀 플래그로 지정합니다. varying depth gradient 는 우리가 동일평면이 아닌 여러 개의 삼각형을 가진다는 것을 의미합니다, 이것은 우리가 평평한 평면이 테셀레이션 된 케이스에 포함되는 에지는 태깅을 피한다는 의미입니다. 여기에 Material ID 만을 사용하여 에지 탐지를 보여줍니다:

…그리고 더 공격적인 depth gradient 체크:

Decals
전통적인 디퍼드 쉐이딩의 큰 장점은 라이팅 패스 전에 G-Buffer 를 수정할 수 있다는 것입니다. 많은 게임들이 deferred decals[14] 를 그래피티, 블러드스플래터, 파편 그리고 포스터들 같은 것들을 장면에 렌더링함으로써 이 장점을 얻습니다. 이것은 전통적인 포워드 렌더링된 데칼보다 훨씬 더 좋습니다, 왜냐하면 여러 개의 데칼이 축적되더라도 픽셀당 라이팅을 단 한 번만 하기 때문입니다. 일반적인 접근법은 라이팅 전에 디퍼드 패스에서 적용하는 것입니다, 여기서 각 데칼이 영향을 미치는 영역을 표현하는 바운딩 볼륨이 레스터라이징 됩니다. 픽셀 쉐이더에서, depth buffer 는 표면의 위치를 계산하는데 사용됩니다, UV 값을 계산하기 위해서 2D 로 투영됩니다. 투영된 UV 는 테칼의 표면 속성을 포함하는 텍스쳐를 샘플하기 위해서 사용됩니다, 이것들은 G-Buffer 로 블랜딩되어 기록됩니다. 최종 결과는 복잡한 장면 지오메트리에서 작동할 수 있는 저렴한 데칼입니다.
일반적인 디퍼드 데칼 시스템을 사용하기 위해서 당신은 2가지가 필요합니다: depth buffer 그리고 G-Buffer. Depth buffer 는 프로젝션 파트를 위해서 필요하며 G-Buffer 는 쉐이딩 전에 속성을 혼합하기 위해서 필요합니다. 포워드 렌더링에서는 depth prepass 를 통해 depth buffer 를 얻을 수 있습니다, 그러나 G-Buffer 파트는 원하는 대로 되지 않습니다. 디퍼드 텍스쳐링에서도 비슷한 위치에 있습니다: 우리는 depth 를 가지고 있지만 G-Buffer 에는 일반적으로 데칼에서 수정하길 원하는 파라메터들이 없습니다. The Order 에서 나는 아주 특화된 데칼 시스템을 만들어서 이 문제를 회피했습니다. 우리는 각 텍스쳐의 채널에 하드코드된 데칼 타입에 해당하는 텍스쳐의 각 채널과 함께, 궁극적으로 렌더타겟에 값을 누적시켰습니다:총알/대미지/분화구, 그을림 그리고 피. 포워드 쉐이더는 이런 값을 읽을 것입니다, 그리고 쉐이더의 라이팅 단계를 수행하기 전에 머터리얼 파라메터를 바꾸기 위해 그들을 사용할 것입니다. 작동은하지만, 명백하게 완전히 우리 게임에 특화되어 있고 전혀 일반적이지 않습니다. 비록 우리가 이 접근법에서 두 가지 좋은 것을 얻었더라도: 머터리얼은 데칼에 어떻게 반응할지를 커스터마이즈 할 수 있었습니다(머터리얼은 실제로 총알 데칼 안쪽의 데미지를 입은 영역에 대해서 완전히 합성된 레이어를 할당할 수 있습니다), 그리고 데칼은 다른 것 위에 적절하게 누적할 수 있습니다.
좋은 뉴스는 디퍼드 프로젝터는 명백히 데칼을 위한 유일한 방법이 아니라는 것입니다. 당신은 라이트를 위해 사용할 수 있는 동일한 클러스터 접근법으로 전환하여 실제로 depth buffer 와 G-Buffer 의 필요성을 제거할 수 있습니다. 이 아이디어는 1 or 2 년 동안 생각해 온 아이디어입니다. 당신은 데칼의 클러스터 당 리스트를 만들 필요가 있습니다, 당신의 쉐이딩 패스에서 리스트를 순회합니다, 그리고 데칼을 그것의 프로젝션에 따라 적용합니다. 중요한 점은, 우리의 쉐이딩 패스는 장면에서 모든 가능한 데칼의 텍스쳐에 접근할 필요가 있다는 것입니다, 그리고 데칼 인덱스를 기반으로 적절한 텍스쳐에 접근할 필요가 있습니다. D3D11 에서는 텍스쳐 배열이나 아틀라스를 사용한다는 의미입니다, 그러나 D3D12 에서는 bindless 로 인해 잠재적으로 이런 머리 아픈 점들을 제거할 수 있습니다.
그래서 데칼에 클러스터 접근법이 실제로 동작하나요? 작동합니다! 나는 그들을 내 앱에 구현했습니다, 그리고 클러스터드 포워드와 디퍼드 텍스쳐링 렌더링 패스에서 작동하게 했습니다. 당신이 원하는 위치에 데칼을 표시할 수 있도록 피커(picker) 도 만들었습니다, 이것은 정말 재미있습니다! 데칼 그 자체는 sci-fi 컬러 세트와 노멀맵입니다, 그래서 DeviantArt[15] 로부터 Nobiax 에 의해 무료로 제공되었습니다. 다음과 같이 보일 것입니다:

내 데모에서 데칼 컬러와 노멀은 컬러 텍스쳐의 알파 채널을 기반으로 표면 파라메터로 블랜딩 됩니다. 그러나 이 방법으로 데칼을 적용함으로써 한 가지 장점은 프레임 버퍼의 블랜딩 오퍼레이션에 제한되지 않는다는 것입니다. 예를 들면, 당신은 기반 표면의 노멀에 상대적인 노멀을 만들기 위해서 표면 노멀을 데칼 노멀의 방향을 조정함[19]으로써 누적할 수 있습니다.
성능에 관해서는, 불행하게도 비교할 다른 데칼 구현이 없습니다. 그러나 화면 대부분을 11 개의 데칼로 덮는 테스트 케이스를 설정하면, 디퍼드 패스의 비용 (no MSAA) 는 GTX970 에서 1.50ms 에서 2.00ms 가 됩니다. 만약 데칼의 분기를 완전히 넘겨버리면(클러스터 비트필드 버퍼로 부터 읽는 것 포함), 비용은 1.33ms 으로 떨어집니다. 포워드 패스에 비용은 데칼 없이 약 1.55ms 입니다, 데칼이 있으면 2.20ms 입니다, 그리고 전체 데칼 스텝을 건너뛰면 1.38 입니다.
Performance
성능 측정을 위해, timestamp 쿼리를 통해 GPU 타이밍 정보를 캡쳐했습니다. 모든 측정은 기본 카메라 위치에서 측정했으며 1920x1080 해상도입니다. 테스트 장면은 CryTek Sponza (우리는 정말로 새로운 테스트 장면이 필요해요!) 로 20 개의 spotlight 를 손으로 배치했고 각각은 1024x1024 의 쉐도우맵을 캐스팅합니다. 태양에 대한 디렉셔널 라이트가 하나 있고 4개의 2048x2048 쉐도우 케스케이드를 사용합니다. 장면은 Alexandre Pestana[16]가 제공한 노멀, 알베도, 러프니스 그리고 메탈릭맵을 사용합니다. 여기에 no MSAA 에서의 디퍼드 텍스쳐링 패스의 프레임 분석이 있습니다:
Render Total: 7.40ms (7.47ms max)
Cluster Update: 0.08ms (0.08ms max)
Sun Shadow Map Rendering: 1.30ms (1.34ms max)
Spot Light Shadow Map Rendering: 1.04ms (1.04ms max)
G-Buffer Rendering: 0.67ms (0.67ms max)
Deferred Rendering: 3.54ms (3.58ms max)
Post Processing: 0.59ms (0.60ms max)…그리고 여기에 4x MSAA 가 있습니다:
Render Total: 9.86ms (9.97ms max)
Cluster Update: 0.08ms (0.08ms max)
Sun Shadow Map Rendering: 1.30ms (1.34ms max)
Spot Light Shadow Map Rendering: 1.04ms (1.05ms max)
G-Buffer Rendering: 1.48ms (1.49ms max)
Deferred Rendering: 4.64ms (4.67ms max)
Post Processing: 0.56ms (0.57ms max)
MSAA Mask: 0.16ms (0.16ms max)
MSAA Resolve: 0.21ms (0.21ms max)첫 번째 타이밍 숫자는 64 프레임의 평균입니다, 두 번째 숫자는 지난 64 프레임들에서의 최대 시간입니다.
아래의 차트는 MSAA 레벨을 올릴 때, 다양한 구성중 일부가 어떻게 스케일 되는지 보여줍니다:
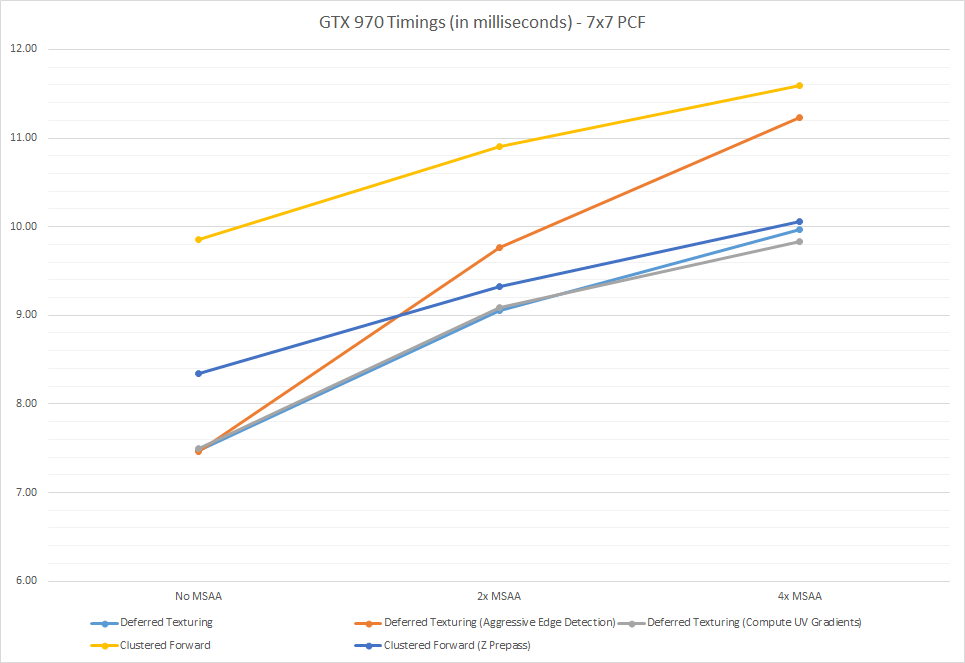
이 데이터로부터 몇 가지 관찰된 것이 있습니다. 먼저, 디퍼드 패스는 일반적으로 포워드 패스보다 잘 동작합니다. depth prepass 가 없는 포워드 패스는 기본적으로 쓸모없습니다, 그 말은 우리가 명백하게 오버드로우 문제에 고통받는다는 의미입니다. 나는 실제로 메인 포워드 패스를 렌더링 할 때 depth 를 기준으로 정렬합니다, 그러나 내 테스트 장면은 앞에서 뒤쪽의 순서로 잘 정렬하기에 충분히 세분화(granularity) 되어있지 않습니다. Depth prepass 를 활성화하는 것은 이것은 상당히 개선해 줍니다, 그러나 디퍼드 성능만큼은 아닙니다. MSAA 를 활성화하면 상황이 조금 달라집니다, 포워드 패스는 디퍼드 렌더링 패스에 비해서 더 잘 확장되기 때문입니다. 4x 포워드 그리고 디퍼드는 거의 비슷합니다, 그러나 이 경우는 디퍼드 패스가 에지 픽셀을 탐지하기 위해 보수적인 머터리얼 ID 체크만 사용하는 경우입니다. 보수적인 패스는 테스트 장면에서 많은 에지를 건너뜁니다, 그래서 AA 품질은 포워드 패스보다 좋지 않습니다. 공격적인 depth gradient 에지 테스트를 사용하는 것은 포워드 패스와 더 비슷한 수준의 품질을 가지게 됩니다만 그것도 꽤 비쌉니다. 그러나 포워드 패스가 복잡한 장면으로 더 좋지 않게 확장될 것이라고 예측할 수 있습니다, 왜냐하면 픽셀 쉐이더의 효율성은 삼각형 개수가 증가함에 따라 감소할 것이기 때문입니다. 우리가 할 수 있는 또 다른 흥미로운 관찰은 UV gradient 를 기록하는 것은 내 970 에서 동작하고 있는 우리의 테스트 장면에서 문제가 되지 않아보이는 것입니다. no MSAA 로, gradient 를 계산하는 대신 그냥 기록하는 것은 실제로 살짝 더 빠릅니다 (7.47ms vs 7.50ms), 그러나 4x MSAA 에는 (9.97ms vs 9.83ms) 로 시간이 변화합니다.
이 모든 타이밍이 무거운 임무(heavy-duty) 를 수행하는 동안 캡쳐되었습니다, “thrash your cache” 7x7 PCF 커널은 GatherCmp 를 사용한 unrolled loop 로 구현되었습니다. 의심할 여지 없이 메모리 트래픽이 크게 증가합니다, 그래서 레지스터의 압박 또한 증가시킬 것입니다. 나는 이것이 포워드 패스에 대해서 특히 더 안좋다고 생각됩니다, 왜냐하면 모든 것이 한개의 픽셀 쉐이더에서 완료되기 때문입니다. 대안으로, 나는 GatherCmp 를 한 번만 사용하는 간단한 2x2 PCF 커널로 되돌리는 옵션을 가지고 있습니다(Shading.hlsl 의 맨 위에서 ”UseGatherPCF_” 를 변경하여 토글 할 수 있습니다). 이 패스는 filterable shadow map 그리고 공격적인 PCF 샘플링 최적화를 사용하는 게임에서 아마도 더 적합할 것입니다. 데이터는 다음과 같습니다:

이런 결과 중 일부는 7x7 경우와 비교할 때 꽤 다릅니다. 포워드 패스는 이전에 했던 것보다 더 좋습니다, 특히 4x MSAA 에서요. 디퍼드 패스는 이전에 그랬던 것처럼 동일하게 확장되며, 공격적인 에지 탐지로 다시 한번 프레임 시간이 길어집니다.
집에서 나는 GTX970 에만 사용합니다, 그래서 내 테스트, 프로파일링 그리고 최적화에 거의 대부분에 사용했습니다. 그러나 나는 GTX 980 뿐 아니라 AMD R9 280 에서 데모가 작동하는 것을 확인할 수 있었습니다. 나는 아래의 테이블에부터 모든 성능 데이터의 요약을 게시했습니다. (모든 타이밍은 밀리세컨드):






만약 당신이 프레임당 분석을 포함하는 Raw 성능 데이터를 보고 싶다면, 그것을 여기에 업로드했습니다: https://mynameismjp.files.wordpress.com/2016/03/deferred-texturing-timings.zip. 당신은 앱에서 스크린의 왼쪽 상단의 “Timings” 버튼을 클릭하여 타이밍 데이터에 접근할 수 있습니다.
그러면 이 실험으로부터 어떤 결론을 그릴 수 있을까요? 개인적으로 나는 비교를 위한 단 한 개의 근거로 만든 인공적인 테스트 시나리오에서 너무 많은 것을 추론하는 것을 조심합니다, 그러나 내 생각에 bindless 디퍼드 텍스쳐링 접근법에는 게임에서 불필요한 것을 만드는 타고난 성능 이슈는 없습니다. 또는 적어도, 내가 테스트를 위해서 사용한 하드웨어에 제약되지 않습니다. 나는 처음에 SampleGrad 그리고 다양한 디스크립터 인덱스(divergent descriptor indices)의 조합이 최선의 퍼포먼스가 아닐 것이라는 걱정을 했었습니다만 마지막에는 나의 특정 설정에 대해 이슈가 보이지 않았습니다. 완전히 공정하게 하자면(Although to be completely fair), 텍스쳐 샘플링은 쉐이딩 프로세스에서 상대적으로 적은 부분을 차지합니다. 그것은 텍스쳐의 숫자가 증가하거나 스크린스페이스에서 머터리얼의 밀도가 높아져서 인덱싱이 다양성(divergent)이 더 높아지면 상황은 달리질 수 있다는 것은 확실합니다. 그러나 동시에 이런 상황은 포워드 패스 또는 전통적인 G-Buffer 패스 동안 성능 감소를 만들 수 있습니다, 그래서 그것이 세탁될 수도 있어요(so it might end up being a wash anyway).
적어도 내 데모에서, 디퍼드 패스에서의 가장 큰 성능 이슈는 MSAA 인 것 같습니다. 디퍼드 렌더러로 저렴한 MSAA 를 구현하는 것이 얼마나 어려운지를 생각해 보면 이것은 놀랍지 않습니다. 내 바램은 디퍼드 텍스쳐링 접근법이 아주 큰 G-Buffer 를 사용하는 전통적인 디퍼드 렌더러보다 더 나았으면 하는 것입니다, 그러나 불행히도 나는 그것을 증명할 데이터가 없습니다. 궁극적으로 그것은 중요하지 않을 것입니다, 왜냐하면 요즘은 MSAA 로 괴롭히는 사람이 거의 없기 때문입니다. :(
한계에 관해서는요? 여러 UV 세트는 기껏해야 골칫거리입니다, 그리고 최악에서의 선택사항이 아닙니다. 내 생각에 당신의 아티스트가 또 다른 UV 세트를 G-Buffer 에 저장하는 것을 감수해야만 합니다, 그리고 또 다른 UV gradient 세트의 저장비용을 지불하거나 계산하는 비용이 듭니다. 전체 G-buffer 를 가지고 있지 않는 것은 SSAO 또는 스크린스페이스 리플렉션과 같은 특정 스크린스페이스 기술에 문제가 있을 수 있습니다. 전체 G-Buffer 없이도 데칼을 가질 수 있다는 것을 보여주었습니다만 더 복잡하고, 전통적인 디퍼드 데칼보다 더 비쌀 수 있습니다. 그러나 반대로, 특정 텍스쳐를 샘플링할 필요가 없는 가벼운 지오메트리 패스를 가지는 것은 정말 좋습니다! 또한 그것은 GPU-driven 배칭 기술에 아주 친숙합니다, 이것의 데모는 SIGGRAPH 의 RedLynx 프리젠테이션에서 볼 수 있습니다.
당신이 이것을 원하지 않을 수도 있는 (또는 적어도 지금 당장은) 마지막 이유가 있습니다: 이 데모를 DX12 에서 작동시키는 것은 정말 고통스러웠습니다. 드라이버 버그, 쉐이더 컴파일 버그, 긴 컴파일 시간, 밸리데이션 버그, 드라이버 크래시, 죽음의 블루스크린: 나는 그런 것과 마주쳤을 때 성가셨습니다. 다이나믹 인덱싱의 지원은 쉐이더 컴파일러와 드라이버 모두에서 다소 미숙한 것으로 보입니다, 그래서 조심스럽게 다룹니다. 마지막 코드는 몇 가지 구현상의 회피가 있습니다, 그래서 나는 주석에 언급했습니다.
Update 8/4/2019: 내가 이 글을 쓴 이후에 상황이 상당히 개선되었습니다. RAD 에서 우리의 엔진은 다양한 렌더링 패스를 전반에 걸쳐 bindless 리소스를 최대한 활용합니다. 드라이버는 더 견고해졌고 오픈 소스 쉐이더 컴파일러 (DXC) 는 FXC 에 비해서 더 빠르고 더 견고합니다(이것은 나의 회피를 제거할 수 있게 해 줬습니다). 나는 scalarization 기술을 구현하기 위해서 라이트/데칼 데이터의 로딩에 SM6.0 의 wave-level intrinsics 를 사용했습니다, 이것은 wave coherency 를 강제하며 AMD 하드웨어에서 상당한 VGPR 사용율을 감소시킬 수 있습니다. 또한 디스크립터 인덱싱을 통해 리소스 접근을 확인할 수 있는 GPU 기반 밸리데이션 레이어가 있습니다, 그리고 PIX 는 드로우나 디스패치 내에서 실제로 어떤 리소스가 사용되는지 보여주기 위해 비슷한 분석을 할 수 있습니다.
만약 내가 여기에 더 많은 시간을 보내면, 내 생각에 디퍼드 텍스쳐링의 더 극단적인 변경 중 일부를 탐구하는 것이 흥미로울 것입니다. 특히 Intel’s 논문인 Visibility Buffers[17] 입니다, 저자는 완전히 Triangle ID 와 인스턴스 ID 를 제외한 모든 표면 데이터 저장을 완전히 포기합니다. 대신에 모든 표면 데이터는 디퍼드 패스 동안 버택스를 변환함으로써 복원합니다, 그리고 barycentrics interpolation 을 계산하기 위해서 ray-triangle 교차 테스트를 수행합니다. Tomasz Stachowiak 가 발표한 deferred material rendering[18]도 있습니다, 여기서는 barycentric coordinates 는 복원(그는 드라이버를 속여서 그의 손으로 작성한 GCN 어셈블리를 받아들이게 합니다!!!)하는 대신 G-Buffer 에 저장됩니다. 그는 머터리얼을 기반으로 서로 다른 쉐이더 패스를 실행하기 위해서 타일 분류를 사용한 몇 가지 좋은 아이디를 가지고 있습니다, 내 데모에서 수행되고 있는 MSAA 타일 분류와 함께 통합될 수 있습니다. 마지막으로 RedLynx 의 프리젠테이션에서 그들은 MSAA 를 절반의 해상도로 렌더링 하는 좋은 트릭을 사용합니다, 그런 다음 디퍼드 패스 중에 최대 해상도의 표면 샘플을 복원합니다. 이것은 디퍼드 쉐이더를 더 복잡하게 하지만 픽셀 쉐이더의 G-Buffer 레스터라이징 코스트를 줄입니다. 내게 무한의 시간이 있다면, 내 데모에서 구현하고 싶지만 나는 잠도 자야 합니다. :)
That’s All, Folks!
여기까지 왔다면, 버텨줘서 고마워요! 이것은 지금까지 중에 가장 긴 글일지도 모릅니다! 나는 이것을 시리즈로 만들까 했지만 저자가 절대 끝내지 못하는 블로그 시리즈가 되게 하고 싶지 않았습니다.
만약 당신이 코드를 보고 싶거나 샘플을 실행하고 싶다면, 모든 것은 GitHub 에 있습니다:
https://github.com/TheRealMJP/DeferredTexturing
만약 당신이 버그나 제안을 갖고 있다면, 댓글, 이메일, GitHub issue 또는 트위터를 통해 알려주시길 바랍니다!
References
[1]Introduction To Resource Binding In D3D12 (Intel)
[2]OpenGL Bindless Extensions (Nvidia)
[3]GL_NV_bindless_texture (OpenGL Extension Registry)
[4]Deferred Texturing (Nathan Reed)
[5]GPU-Driven Rendering Pipelines (Haar and Aaltonen, SIGGRAPH 2015)
[6]Modern Textureless Deferred Rendering Techniques (Beyond3D)
[7]The Bitsquid Low-Level Animation System
[8]Practical Clustered Shading (Emil Persson)
[9]Deferred Rendering for Current and Future Rendering Pipelines (Intel, Andrew Lauritzen)
[10]Forward+: Bringing Deferred Lighting To The Next Level (AMD, Takahiro Harada)
[11]Forward Clustered Shading (Intel)
[12]Correct Frustum Culling (Íñigo Quílez)
[13]Conservative Rasterization (MSDN)
[14]Screen Space Decals in Warhammer 40K: Space Marine (Pope Kim)
[15]Free Sci-Fi Decals 2 (Nobiax, DeviantArt)
[16]Base color, Roughness and Metallic textures for Sponza (Alexandre Pestana)
[17]The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading (Burns and Hunt, JCGT)
[18]A Deferred Material Rendering System (Tomasz Stachowiak)
[19]Blending In Detail (Barré-Brisebois and Hill)
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] SV_Barycentrics (0) | 2023.07.22 |
|---|---|
| [번역] Reservoir Sampling (0) | 2023.01.17 |
| [번역] Sampling Importance Resampling (0) | 2023.01.03 |
| [번역] Journey to Lumen (0) | 2022.10.09 |
| [번역] Octahedron normal vector encoding (2) | 2022.09.30 |



