
Notice
Recent Posts
Recent Comments
Link
반응형
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- SGPR
- shader
- hzb
- Nanite
- ShadowMap
- GPU
- rendering
- VGPR
- 번역
- Study
- Wavefront
- ue4
- SIMD
- Graphics
- unrealengine
- DirectX12
- GPU Driven Rendering
- texture
- wave
- vulkan
- forward
- RayTracing
- scalar
- UE5
- optimization
- scattering
- atmospheric
- DX12
- deferred
- Shadow
Archives
- Today
- Total
RenderLog
[번역] Sampling Importance Resampling 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 : https://blog.demofox.org/2022/03/02/sampling-importance-resampling/
마지막 게시물인 weighted reservoir sampling 은 2020년 논문 “Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting” 의 주요 기술 중 하나 입니다. (https://research.nvidia.com/sites/default/files/pubs/2020-07_Spatiotemporal-reservoir-resampling/ReSTIR.pdf). 이 글은 또다른 주요 기술로 사용된 Sampling importance resampling 또는 SIR 에 대한 글입니다.
SIR 는 확률 분포 A 로 부터 아이템 리스트를 가질 수 있게 해줍니다, 그리고 확률 분포 B 로 부터 아이템을 꺼낼 수 있게 해줍니다.
이 글과 함께 제공되는 C++ 코드는 여기에 있습니다. https://github.com/Atrix256/ResampledImportanceSampling
SIR Algorithm
이 알고리즘은 확률 분포 A 로 부터 값의 리스트를 꺼내면서 시작합니다, 그리고 각각의 값에 weight 1 로 할당합니다.
다음으로, 각 아이템의 weight 를 분포 A의 아이템에 대한 PDF 로 나눕니다.
그리고나서 각 아이템의 weight 에 타겟 분포인 분포 B의 아이템에 대한 PDF 를 곱합니다.
그 뒤 리스트에 있는 모든 아이템을 정규화하고 그들의 합이 1.0 이 되도록 합니다.
각 아이템을 선택하기 위해서 정규화된 weight 값을 확률로 사용한다면, 확률 분포 A 가 리스트를 만들기 위해서 사용되었지만, 당신은 확률 분포 B 로 부터 값을 가져옵니다.
Example and Intuition
내 생각에 이 예제가 이해하는데 크게 도움을 줄 것 같습니다.
우리는 작은 리스트로 시작합니다:
4, 5, 5
이 리스트에서 아이템을 선택하는 것은 4 보다 5를 선택될 가능성이 두배입니다. 왜냐하면 2배 더 많기 때문입니다. 만약 우리가 이 리스트에서 균일 샘플링(uniform sampling) 을 한다면, 모든 weight 가 1인 리스트의 weight sampling 하는 것과 같습니다. 리스트에 weight 를 둬봅시다.
4 (1), 5 (1), 5 (1)
리스트에서 각 값을 선택하는 확률은 다음과 같습니다:
4: 1/3
5: 2/3
다음을 얻기 위해서, weight 를 그것의 확률로 나눕니다:
4 (3), 5 (3/2), 5 (3/2)
Or
4 (3), 5 (1.5), 5 (1.5)
이것은 다음과 같이 정규화 할 수 있습니다:
4 (0.5), 5 (0.25), 5 (0.25)
만약 당신이 이 weight 를 사용하는 리스트로 부터 weighted random selection 을 한다면, 이제 당신은 4를 얻을 확률이 5를 얻을 확률과 같다는 것을 알 수 있습니다. 그래서 확률로 weight 를 나누는 것은 균일 분포를 만들어 줍니다.
이제, 우리의 4를 선택할 가능성이 5 보다 3배 더 많은 타겟 분포에 대해서 이야기 해봅시다. 여기에서 그것에 대한 확률이 있습니다:
4: 0.75
5: 0.25
우리는 이제 weight 에 이 확률을 곱해서 다음을 얻습니다:
4 (0.375), 5 (0.0625), 5 (0.0625)
이 weight 를 정규화 하면, 우리는 이것을 얻습니다:
4 (0.75), 5 (0.125), 5 (0.125)
만약 당신이 이런 weight 를 사용하는 리스트로 부터 샘플링 한다면, 75% 확률로 4, 25% 확률로 5를 얻을 것입니다.
그래서, 우리가 5가 4보다 2배 더 많은 샘플링 되도록 만들었지만, 이제 4가 5보다 3배 더 높도록 할 수도 있습니다.
weight 를 리스트를 생성한 확률로 나누어서 리스트를 균일하게 만들 수 있다는 것을 직관적으로 알 수 있습니다. 우리가 weight 를 새로운 분포의 확률로 곱해주면, 그것은 리스트가 그 분포를 취하도록 만들어줍니다. 엄청 복잡하진 않죠?
Results
여기서 우리는 이 방법을 100,000 개의 -1~1 사이의 균일한 랜덤 float 값을 생성하는데 사용합니다, 그리고 그것으로 부터 10000 sigma 0.1 가우시안 랜덤 수를 샘플링하기 위해서 이 기술을 사용합니다. 이것은 히스토그램으로 시작하며, sampling importance resampled 값의 히스토그램 입니다.
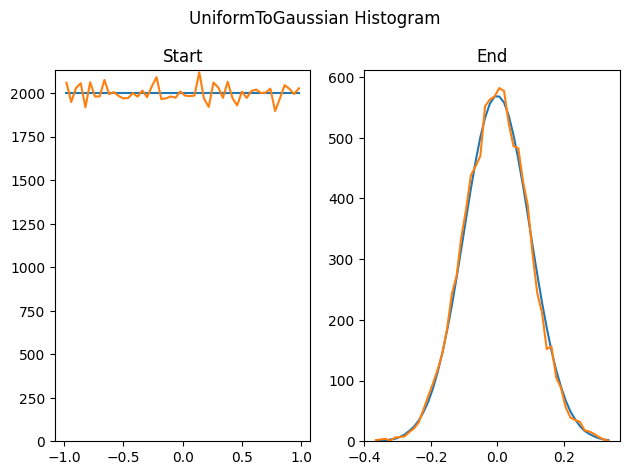
여기서 우리는 sigma 1.0 가우시안 분포값으로 시작합니다, 그리고 그것을 y=3x^2 PDF 로 리샘플링 합니다.

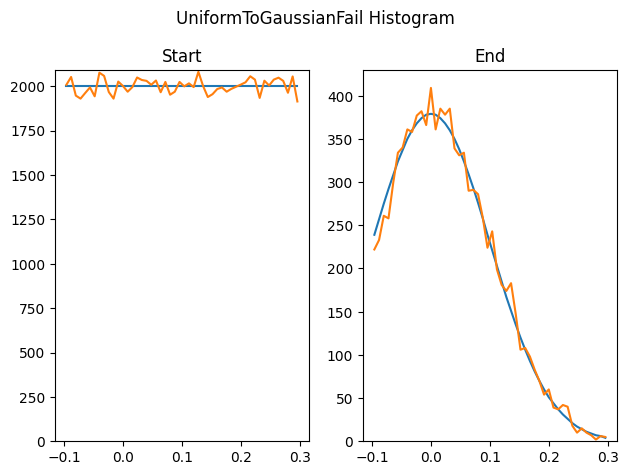
이것이 항상 잘 작동하는 것은 아닙니다. 이 방법은 시작 리스트에 있는 값만 출력할 수 있습니다, 그래서 시작할 때의 리스트가 타겟 PDF 의 전체 범위을 포함하지 못하면, 타겟 PDF 의 전체 범위를 얻을 수 없을 것입니다. 여기서 우리는 -0.1~0.3 사이의 균일한 랜덤 값을 생성하고 sigma 0.1 가우시안으로 리샘플링 하려고 합니다. 우리는 -0.1~0.3 사이에 있는 숫자만 출력할 수 있으며 이것은 가우시안의 전체 범위가 아닙니다.
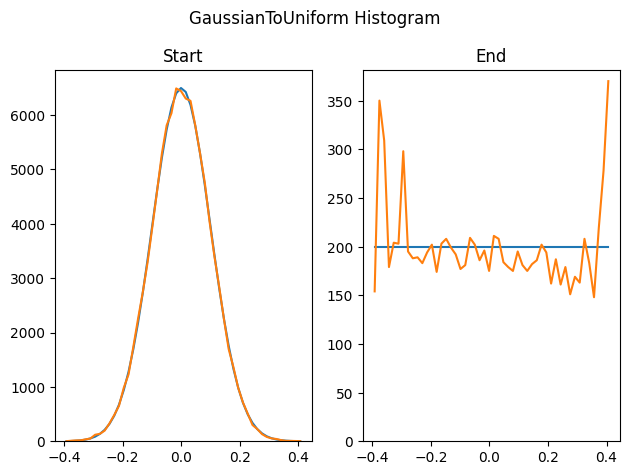
이 기술은 만약 소스 리스트에서 유니크 값이 충분하지 않아도 문제가 될 수 있습니다. 여기서 우리는 우리가 이전 테스트에서 했던 100,000 개 대신에 500 개의 균일 랜덤 샘플을 생성했습니다, 그리고 이것을 가우시안으로 변환하려 합니다.

여기서 우리는 동일한 수의 시작과 끝 샘플의 수를 사용하여 가우시안 테스트에 non failure uniform 을 역으로 수행합니다. 가우시안의 양쪽 꼬리 끝에 이벤트가 드물게 폭발하는 것처럼 보입니다...
Other Stuff
SIR 알고리즘을 할때, 우리는 리스트로 부터 랜덤 선택을 할 수 있기 위해서 weight 를 정규화 했습니다. 정규화된 아이템의 weight 는 그것이 선택될 확률입니다.
이것은 당신이 이 리스트를 여러 패스 동안 수행해야 된다는 의미입니다: weight 의 합계를 얻으면, 그들을 다시 정규화합니다. 이제 리스트로 부터 아이템을 무작위로 선택할 수 있습니다.
지난 블로그 글은 우리에게 한개의 패스로 weighted 리스트에서 공정한 무작위 선택을 하는 방법을 보여줬습니다, 여기서 weight 는 정규화 될 필요가 없습니다. 그래서, 만약 당신이 reservoir sampling 을 weighted 리스트로 부터 샘플링하는데 사용한다면, 당신은 weight 를 정규화 할 필요가 없습니다, 그리고 당신은 어떠한 전처리도 없이 무작위로 weighted 선택을 가능하게 해줍니다. 당신이 아이템을 처음 볼 때, 그 아이템에 대한 weight 를 계산할 수도 있습니다 (레이 트레이싱의 결과 같이?), 왜냐하면 당신은 weighted 무작위 선택을 위해 (공정하게) 그것을 고려하기 때문입니다. 얼마나 멋진가요?
더 나아가, Importance sampling 을 리샘플링 하기 전에 선택한 샘플의 리스트은 균일할 것입니다, 그러나 그것이 필요하지 않습니다. 한개의 분포를 사용하여 아이템을 선택하고 두번째 분포를 사용하여 최적의 항목을 찾는?, 아마도 당신은 MIS 와 같은것을 할 수 있을 것입니다, 그게 말이될지 말지는 확신할 수 없습니다.
마지막으로, 균일과 비균일 분포에 대해서 이야기 하는 동안, white noise 가 내포되어 있지만, 반드시 white noise 일 필요는 없습니다. 가우시안 blue noise 는 균일한 red noise 입니다(Gaussian blue noise is a thing, or uniform red noise). 입력과 출력에 서로 다른 noise color 를 사용하기 위한 방법도 있습니다, 또는 low discrepancy 나 메모리나 다른 샘플에 대해서 알고 있는 종류의 다른 scoring 함수로 승급하기 위해 weighting(scoring)을 하는 방법도 있습니다.
그것은 약간 주제와 벗어났지만, 요점은 여기에 많은 가능성이 있다는 것입니다.
만약 당신이 이글과 저번 글을 이해했고 더 많은 것을 원하면 논문을 읽어보세요. 당신은 그것이 무엇에 대한 이야기인지 이해할 수 있을 것입니다, 그리고 일부 관련 주제와 구현 디테일에 대해 더 깊게 들어갈 것입니다.
“Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting” https://research.nvidia.com/sites/default/files/pubs/2020-07_Spatiotemporal-reservoir-resampling/ReSTIR.pdf
읽어주셔서 감사합니다!
반응형
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] Bindless Texturing for Deferred Rendering and Decals (2) | 2023.02.22 |
|---|---|
| [번역] Reservoir Sampling (0) | 2023.01.17 |
| [번역] Journey to Lumen (0) | 2022.10.09 |
| [번역] Octahedron normal vector encoding (2) | 2022.09.30 |
| [번역] Even more compute shaders | Anteru's Blog (0) | 2022.07.30 |
'Graphics/참고자료' Related Articles
more



