
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- hzb
- shader
- wave
- ue4
- forward
- ShadowMap
- GPU
- Study
- Graphics
- SIMD
- Nanite
- scalar
- UE5
- scattering
- atmospheric
- texture
- VGPR
- vulkan
- unrealengine
- GPU Driven Rendering
- rendering
- RayTracing
- DirectX12
- 번역
- deferred
- Wavefront
- SGPR
- Shadow
- DX12
- optimization
- Today
- Total
RenderLog
[번역] Even more compute shaders | Anteru's Blog 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 : https://anteru.net/blog/2018/even-more-compute-shaders/
Even more compute shaders
GPU compute 에 관한 작은 시리즈가 된 것 같습니다, 그리고 이번 주에는 execution unit 과 cache 에 대해서 논의해보려고 합니다. 첫 번째 글(번역링크) 두 번째 글(번역링크) 을 먼저 읽어보길 강력 추천합니다, 그 둘을 자주 참조할 것이기 때문입니다. Cache 와 execution unit, 어디서부터 시작해야 할까요? execution unit 먼저 시작해봅시다.
Issue ports
만약 당신이 현대 CPU 디자인에 익숙하다면, 당신은 CPU 는 한 번에 하나의 명령어를 처리하는 scalar 가 아니라는 것을 알 것입니다. Zen 같은 현대 CPU architecture 는 10 개의 issue port 를 가집니다:

GPU 는 여러 issue port 의 장점을 얻습니다, 그러나 CPU 와 같은 방식은 아닙니다. CPU 에서는, 명령어가 순서대로 실행되지 않습니다, 그리고 그들 중 몇몇은 추측에 근거하여 실행됩니다. 이것은 GPU 에서는 적절하지 않습니다. 이름을 변경하는 레지스터로 전체 순서가 보장되지 않는 시스템은 더 많은 레지스터를 요구합니다(The whole out-of-order machinery with register renaming requires even more registers), 그리고 GPU는 이미 많은 수의 레지스터를 갖고 있습니다(Vega10 GPU 는 예를 들어 16MiB 의 레지스터가 있습니다). 예측 실행이 파워 사용률을 증가시키는 것과 아주 광범위한 작업량(workload)을 수행하는 GPU 에서는 이미 크게 제한되었습니다. 마지막으로, GPU 프로그램은 시작부터 CPU 프로그램과 같지 않습니다 - CPU는 순서대로 처리되지 않고, 예측하고, 사전로드(prefetching) 것 등등은 GCC 를 실행하고 있다면 좋습니다, 그러나 오래된 pixel shader 는 그렇지 않습니다.
즉, SIMD 가 데이터 작업하는 동안 메모리 요청을 제출하는 것 또는 scalar 명령을 동시에 실행하는 것은 매우 타당합니다. 우리는 어떻게 순서대로 처리하면서 이런 장점을 얻을 수 있을 까요? CPU 에 비해서 GPU 의 장점은 많은 작업이 진행 중이라는 것입니다. 메모리 지연 시간을 숨기기 위해 우리가 이런 장점을 취하는 것처럼, 우리는 또한 스케쥴링을 이용할 수 있습니다. CPU 에서, 우리는 single instruction stream 을 보고 독립적인 명령을 찾길 시도합니다. GPU 에서, 우리는 이미 수많은 독립적인 instruction stream 을 가지고 있습니다. instruction-level 병렬화를 얻는 가장 쉬운 방법은 간단히 서로 다른 타입을 위한 단위를 가지는 것입니다. 그리고 그것에 따라 제출합니다. CU 당 약간의 execution port 를 가진 GCN 는 정확히 이렇게 설정되어 있는 것으로 밝혀졌습니다:

총, 6개의 분리된 execution port 가 있습니다, 그리고 dispatcher 는 한 개의 명령을 cycle 당 최대 5 개 까지 보낼 수 있습니다. 약간 특별한 명령어도 있습니다. 그것은 dispatcher 에서 즉시 처리됩니다 (no-ops 같은 것 - unit 으로 보내도 사용하지 않음). 매 clock cycle 마다, dispatcher 는 active wave 을 확인합니다, 그리고 다음 명령이 준비되었는지 확인합니다. 그리고 나서 그것을 다음 사용가능한 unit 에 보냅니다. 예를 들어, 우리가 아래와 같은 코드를 실행하고 있다고 가정합시다:
v_add_f32 r0, r1, r2
s_cmp_eq_i32 s1, s2만약 2개의 wave 가 준비되어있다면, dispatcher 는 첫 번째 v_add 를 첫 번째 SIMD 에 제출할 것입니다. 다음 cycle 에서, s_cmp 는 첫번째 wave 로 부터 그리고 v_add 는 두 번째 wave 에서 제출될 것입니다. 이런 방식으로 scalar 명령은 vector 명령과 겹칩니다, 그리고 우리는 사전 예측이나 값비싼 비순서 시스템 없이 명령어 수준에서의 병렬화를 얻습니다.
완성된 예제를 봅시다, 여러 개의 wavefront scalar, vector 그리고 memory 명령들을 적절한 조합으로 실행합니다:
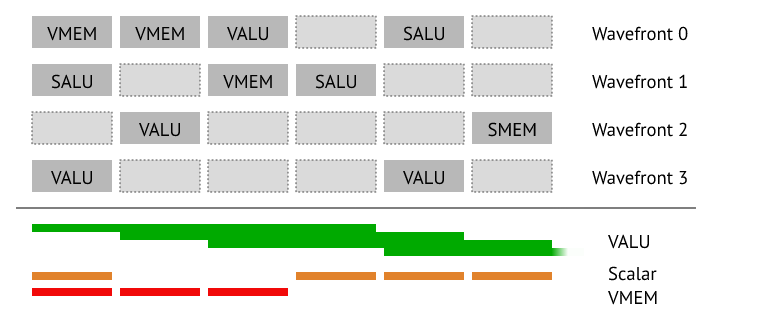
이것을 마무리하기 전에 마지막으로 해야 할 것은 load 와 store 를 처리하는 것입니다. CPU 에서는, 모든 것이 투명합니다, 당신은 다음과 같이 시퀀스를 작성할 수 있습니다:
mov rcx,QWORD PTR [rsp+0x8]
add rdx, rcx이것은 그냥 동작할 겁니다, 왜냐하면 CPU 는 사전에 정보를 추적하여 load 가 끝나 있어야 한다는 것을 "알고 있기" 때문입니다. GPU 에서, 레지스터가 load 에 의해서 기록되는 것을 추적하는 것은 상당한 추가 하드웨어를 요구합니다. GPU 에서의 해결책은 문제를 "one level up" 하여 쉐이더 컴파일러로 옮기는 것입니다. 컴파일러는 필요한 정보를 갖고 있으며, load 를 위해서 wait 를 수동으로 추가합니다. GCN ISA 에서는, 특정 수의 load 가 완료될 때까지 대기하기 위해서 특별한 명령 - s_waitcnt - 을 사용합니다. 이것은 단지 모든 것을 기다리는 것이 아니라, 여러 개의 load 를 동시에하는 파이프라이닝을 가능하게 합니다 그러고 나서 그들을 하나씩 소비합니다. 이와 대응되는 GCN ISA 는 아래와 같습니다:
s_buffer_load_dword s0, s[12:15], 0x0 ; load a single dword
s_waitcnt lgkmcnt(0) ; wait for the previous
; load to finish
v_add r0, s0, r1 ; consume the loaded data
코어(compute unit) 당 4개의 스레드가 돌고 있는 (GCN)GPU를 CPU 로 생각하는 것이 좋다고 생각합니다, 그리고 각 스레드는 scalar, vector 그리고 다른 명령어를 호출할 수 있습니다. 그것은 차례대로 수행되고 디자이너는 하드웨어와 소프트웨어의 복잡도를 트레이드오프 했습니다. 값비싼 하드웨어 대신, GPU 는 대규모 병렬 소프트웨어가 필요합니다 - 지연을 숨기기 위한 것만이 아니라, 모든 unit 의 실행하는 장점 또한 얻기 위해서, "자동" 추적 대신, 컴파일러가 추가 연산을 집어넣는 것이 필요합니다, 그래서 어플리케이션이 이것을 완전히 활용할 수 있도록 충분한 병렬화를 제공합니다, 그러나 동시에, 이것은 대규모 처리량과 수많은 execution unit 을 제공합니다. 이것은 당신이 실행하고 있는 코드의 특성이 하드웨어 디자인에 어떻게 영향을 주는지에 대한 좋은 예제입니다.
Caches
하드웨어에 영향을 주는 소프트웨어에 대해 말하면, 우리는 cache 에 대해서도 이야기해야만 합니다. GPU 캐시는 GPU 가 대규모 병렬 작업(workload) 을 위해서 어떻게 만들어졌는지 예제, 그리고 CPU 에 비해서 디자이너가 어떤 트레이드오프를 했는지에 대한 것을 보여주는 또 다른 예제입니다(그리고 이 시리즈의 마지막입니다). 우리는 CPU 가 실제로 GPU 와 같은 길을 가고 있다는 것을 깨달을 것입니다!
CPUs
현재 CPU 가 어떻게 생겼는지 보는 것으로 시작해봅시다, 예를 들어, Zen architecture 기반으로 구축된 32-core 서버 CPU:

CPU 는 엄청 큽니다. 그리고 흥미롭게도, 고성능 코드에는 topology 가 중요합니다. 같은 L3 를 공유하는 두 개의 코어는 명백히 거기서 데이터를 교환할 수 있습니다, 반면에 다른 L3 로 가는 동안에는 약간의 이동이 필요합니다 - die 간에 이동하는 것에 대해서는 말할 것도 없습니다. 그것은 당연한 것입니다, 칩이 크면 클수록 die 면적 또한 커집니다, 그래서 먼 거리를 이동하는 것은 power 사용률과 지연 측면에서 점점 비용이 많이 듭니다. 이것에 대해 뾰족한 방법은 없습니다 - 이건 물리적인 거예요 - 그리고 모든 core 가 모든 core 에 대해서 최악의 지연 비용을 지불하는 것을 제외하면, 항상 가까운 곳에 몇몇 core 들이 있을 것입니다.
어플리케이션 개발자에 이것은 무슨 의미일까요? 어플리케이션은 "서로 가까이" 서 작업하는 것을 유지해야만 합니다 - 보통, OS 스케쥴러는 이것을 관리할 것입니다. 기본적으로, 모든 캐시는 서로 일관성(coherent) 있습니다, 이것은 만약 core가 좌상단 코너에서 어떤 것을 메모리에 기록한다면, 우하단에 있는 core 는 이것을 볼 수 있다는 것입니다. 이것을 처리하기 위해서 여러 규약(Various protocols) 이 디자인되었습니다; 요지는 어떠한 core 도 메모리를 기록할 수 있고 다른 core 는 기본적으로 새로운 데이터를 볼 수 있을 것입니다. 어플리케이션에 의해 다른 추가 작업은 요구되지 않습니다 - 그러나 core 간에 데이터 공유는 수많은 corss-core 통신을 강제한다는 것을 이미 상상할 수 있습니다.
GPUs
이제, GPU 는 훨씬 더 많이 병렬화 된 CPU 입니다. Vega10 GPU 는 사실상 비슷한 캐시 계층을 가지고 있는 64-core CPU 를 말합니다. 봅시다:

크기는 완전 다르지만, 여전히 어렴풋이 비슷합니다. 만약 눈을 가늘게 뜨면, 당신은 single die 의 64-core 라고 생각할 수 있습니다. 명백히, 또다시 악마는 디테일에 숨어있습니다, 왜냐하면 CPU 는 일관성(coherency)를 기본적으로 가집니다, GPU는 아주 다른 모드로 작동합니다. 프로그래밍 모델은 많은 독립된 작업들을 위해서 디자인되었습니다, 그래서 어떻게 이것이 우리의 cache 디자인에 영향을 줬을지 생각해봅시다. 주어진 모든 work item 은 독립적입니다, 우리는 각 core 가 자신이 소유한 데이터로 작업하고, core 간의 공유가 거의 없거나 약간만 있다고 가정합니다. 이것을 위해 하드웨어를 최적화하려면 어떻게 해야 할까요? 먼저, 우리는 기본적으로 일관성(coherency)을 제거할 것입니다, 왜냐하면 이것은 동기화(sync)를 요구하기 때문입니다 - 첫 번째는 메모리 (우리는 캐시 바깥 어딘가로 데이터를 내보낼 필요가 있습니다), 그리고 둘째로, 두 번째 core 가 실제로 같은 데이터를 처리하는 경우입니다. 우리가 배웠듯, 실행 순서는 일반적으로 GPU 가 제공하는 것이 아니며 그것은 캐시 처리에 직접적으로 영향을 미칩니다. 개발자가 미리 동기화해야 한다면, 그들은 동시에 메모리 베리어 할 수 있습니다.
다른 부분은 캐시가 자체적으로 관리되지 않는다는 것입니다. CPU 에서, single process 범위 내에서 동작하는 경향이 있습니다만 GPU 에서는, cache 의 내보내기(flushing) 과 무효화(invalidating) 는 매우 명시적인 작업입니다. 만약 compute shader 하나를 마쳤고 다음 것을 시작하길 원한다면, GPU 는 모든 작업이 완료되게 하기 위해서 일반적으로 배수관(drain)(역주 : 모든 작업 실행 후 특정 내용이 실행 될 수 있게 길을 마련 한단 의미로 보임)을 삽입합니다, 그리고 다음 dispatch 가 데이터를 볼 수 있게 하기 위해서, 모든 compute-unit local cache 를 내보내고(flush) 고 무효화(invalidate) 합니다. 이것은 L2 에 데이터를 보존하는 것을 중요하게 합니다 - L1 cache 의 내보내기(flushing) 은 자주 일어납니다, 왜냐하면 작고, 저렴하기 때문입니다. 그에 비해 single core 에 L2 가 있는 CPU 는 이미 GPU 의 모든 L1 캐시의 절반 크기입니다!
다른 흥미로운 것은 공유 캐시(shared cache)입니다. CPU 의 경우, L3 데이터만 공유 데이터입니다. GPU 의 경우, 우리는 많은 compute unit을 실행하기 위한 single program이라고 예상합니다, 명령 캐시는 compute unit 사이에서 공유됩니다. 이것은 이상적으로는 우리가 동일한 프로그램을 GPU 내에서 특정 목적(랜덤하지 않은 방식)으로 선택한 4 개의 compute unit 그룹에 보내길 원한다는 것을 의미합니다. 비슷하게, 우리는 동일한 프로그램을 실행하는 모든 wave 에 동일한 상수가 로드된다고 가정합니다. 이것은 상수(constant)/scalar cache 가 분리되는 결과를 초례합니다. 이것은 실질적으로 읽기 전용입니다(atomic 명령어 제외), 이것은 내보낼(flush) 필요가 없다는 의미입니다(데이터가 변하지 않아서), 그러나 dispatch 간에 무효화(invalidation)은 여전히 필요합니다. 당신은 아마도 기본 설정을 사용하면, 어떻게 cache 간의 일관성을 얻을 수 있을지 궁금할 수 있습니다. 물론 방법이 있습니다, GLSL 의 예로 coherent modifier 가 있습니다. 반가운 답입니다 - 그리고 이것의 해결책은 꽤 간단합니다. 모든 compute unit 은 동일한 L2 를 공유합니다, 그래서 만약 우리가 일관성을 보장하길 원하면, 우리는 그냥 L1 을 지나칠 수 있습니다. 만약 당신이 GCN ISA 을 본다면, 거기에는 GLC bit 가 있고 이런 의미입니다: “강제로 L1 cache 를 지나친다”. L2 에 기록함으로써, 그리고 항상 L2 에서 읽음 으로써 우리는 어떤 일관성 규약 없이, 캐시 일관성 효과를 얻을 수 있습니다. 모든 기본 비용은 (작은)L1 을 무시하는 것입니다 - 다시 말해, GPU 에 대한 트레이드오프는 타당합니다.
마지막으로, 크기에 대해서 한번 더 이야기해봅시다. CPU 와 비교하여, 캐시는 작습니다, 왜 캐시가 있는 걸까요? CPU 에서, cache 는 모두 재사용과 관련 있습니다, 그리고 레지스터에 데이터를 거의 보관할 수 없으므로 큰 cache 가 필요합니다. 다른 한편으로는 CPU 코드가 모든 곳에서 메모리를 읽는 경향이 있다는 것입니다, 그러나 일반적으로 주변 데이터의 큰 덩어리(chunk) 를 읽지 않습니다. 데이터 베이스를 생각해보세요 - 서로 옆에 있는 몇 개의 항목을 읽을 가능성은 아주 낮습니다.
반면에 GPU 는 다른 문제를 해결해야 합니다. 작동 중인 수많은 스레드, 그들 모두가 데이터를 통해 스트리밍 하거나 공간적으로 일관된(spatially coherent) 방식으로 데이터에 접근하길 원할 것입니다(텍스쳐를 생각해보세요). 이런 사례를 통해서, 당신은 읽기/쓰기를 조합하고 데이터를 레지스터로 이동할 수 있을 만큼 충분히 오래 유지할 수 있도록 하는 cache 를 원합니다. 예를 들어, 컴포넌트 별로 4-컴포넌트인 벡터 컴포넌트를 로딩 중입니다. 이상적으로, 당신은 4 개의 컴포넌트가 로드가 끝나기 전까지 "cached" 되길 원합니다. 작은 cache 는 이것에 아주 잘 맞습니다 - cache line 이 소비될 때까지 유지합니다, 그리고 다시 cache 에 적중할 기회는 굉장히 적습니다. 왜냐하면 보통 당신의 스레드는 엄청난 수 (독립적인) 데이터를 처리하고 있기 때문입니다. 이 시리즈에서, 이것은 어떻게 어플리케이션과 예상 사용량(usage)이 GPU를 CPU와 매우 다르게 만들었는지 보여주는 마지막 예제입니다.
Summary
이게 전부입니다! 나는 당신이 이 시리즈를 즐겼기를 바랍니다 - 그리고 CPU 와 GPU 둘 다 멀티-코어 프로세서이지만 다른 사용 예를 위해서 특별히 설계되었고 그에 맞게 조정되었습니다. 다른 흥미로운 것은 어떻게 프로그래밍 모델이 하드웨어 디자인에 영향을 미쳤는지 이고 그 반대도 마찬가지입니다 - 그리고 우리가 수렴하기 위해서 어떤 길로 가고 있는지. 현대 GPU 코드는 현재 GPU 에서 잘 수행되는 경향이 있습니다; 그것은 이미 많은 core 의 장점을 얻을 수 있고, non-uniform 메모리 접근을 처리할 수 있는 것, 그리고 적은 cache 일관성 보장도 쉽게 대처할 수 있도록 잘 디자인되어 있습니다. 우리는 어디로 향하나요? 나는 모르겠습니다, 하지만 확실하게, compute shader 와 GPU execution model 의 개념은 미래의 우리가 어디로 향하던 준비할 수 있게 도와줄 것입니다!
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] Journey to Lumen (0) | 2022.10.09 |
|---|---|
| [번역] Octahedron normal vector encoding (2) | 2022.09.30 |
| [번역] More compute shaders | Anteru's Blog (0) | 2022.07.28 |
| [번역] Introduction to compute shaders | Anteru's Blog (0) | 2022.07.25 |
| [번역] Multiple Importance Sampling in 1D (0) | 2022.04.11 |



