
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- DirectX12
- Wavefront
- SIMD
- vulkan
- Shadow
- VGPR
- UE5
- forward
- Graphics
- unrealengine
- rendering
- RayTracing
- SGPR
- ue4
- GPU Driven Rendering
- wave
- atmospheric
- hzb
- DX12
- Study
- shader
- texture
- optimization
- ShadowMap
- deferred
- GPU
- scalar
- scattering
- 번역
- Nanite
- Today
- Total
RenderLog
[번역] Introduction to compute shaders | Anteru's Blog 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 : https://anteru.net/blog/2018/intro-to-compute-shaders/
Introduction to compute shaders
몇 달 전에 나는 누구든 강연를 제안할 수 있고, 어떤 강연으로 할지 빠른 투표가 진행되는 bar camp 인 Munich GameCamp 에 갔습니다. 나는 몇 가지 아이디어를 주변에 물어봤습니다, 그리고 한 개발자는 아마도 내가 compute shader 를 다루길 원할 것이라 했습니다. 그래서 나는 많은 사람들의 주목을 끌지 않길 바라며 들어갔습니다, 그러나 거의 참가자의 1/4 이 거의 한 시간 동안 compute shader에 대해서 이야기하는 만원인 방이 되었습니다. 내가 받은 주요 질문은: "이것을 어디서 읽을 수 있죠?" 였습니다, 그리고 나는 compute shader 에 대해서 좋은 소개를 할 수 없었습니다(Ryg’s “a trip through the graphics pipeline 이 있습니다만 이미 꽤 오래전에 소개되었습니다).
The hardware
어떻게 compute shader 가 만들어졌는지 이해하려면, 먼저 하드웨어의 진화를 봐야 합니다. 쉐이더 이전으로 돌아가면, 우리는 Geometry processing와 Texturing를 분리했었습니다. 예를들어, Voodoo² card 는 1개의 레스터라이저와 2개의 texturing unit 을 가지고 있어서 그들 사이의 작업량(workload)를 분리 되었습니다. 이런 구조는 오랜시간 유지되었습니다, 심지어 쉐이더가 소개된 이후에도요. GeForce 7 과 Radeon X1950 까지, GPU는 vertex 와 pixel shader unit 이 따로 있었습니다. 이런 unit 은 그들이 무엇을 계산할 수 있는지의 측면에서 비슷했습니다(결국, 덧셈과 곱셈은 GPU에서 하는 대부분의 작업입니다), 그러나 memory access 는 상당히 달랐습니다. 예를 들면, texture 접근은 vertex shader 에서 오랫동안 할 수 없었습니다. 그때는, 장면이 적은 수의 폴리곤으로 구성되었고 이것들은 많은 픽셀들을 다루었기 때문에 vertex shading power가 더 낮은 것은 보통 병목을 만들지 않았습니다. 그래서 이런 분리는 타당했습니다. vertex shader 의 기능을 제거하여, 더 나은 최적화 될 수 있었고, 그래서 더 빨리 수행될 수 있었습니다.

그러나, 고정된 분포는 리소스 부하 분산(load-balance)을 불가능하게 합니다. 게임이 발전하면서, 가끔 vertex power 가 더 많이 필요할 때가 있었습니다. 예를들면, 나무 같은 밀도 높은 geometry 를 렌더링 할 때가 있습니다. 반면에 다른 게임은 더 복잡한 Pixel shader를 작성하기 위해서 새로운 쉐이더 프로그래밍 모델을 사용했습니다. 이 시기는 GPGPU 프로그램이 시작한 시기입니다. 프로그래머들은 GPU에서 numerical program을 해결하려고 노력하고 있었습니다. 결국, 이런 고정적인 unit의 분리가 좋지 않다는 것이 분명해졌습니다. 2006 년 말 ~ 2007 년 초에, GeForce 8800 GTX 와 Radeon HD 2800(기술적으로는 XBox 360 이 커스터마이즈된 ATI 칩을 처음으로 사용했습니다) 이 출시되면서 "unified shaders" 의 시대가 시작되었습니다. 분리된 unit의 시대는 지났습니다; 대신, shader core 는 어떤 종류의 작업(workload)도 처리도 가능했습니다.

그래서 그땐 무슨 일이 일어났나요? Math 명령어를 실행하는 유닛인 ALU는 이미 비슷했습니다. 달라진 점은 unit 간의 차이가 완전히 제거되었습니다. Vertex shader 는 이제 pixel shader 와 완전히 같은 unit 에서 수행됩니다. 이런 점은 vertex 와 pixel shader 작업의 작업량 균형을(balance the workload) 맞출 수 있게 합니다. 여기서 당신이 알 수 있는 것은 vertex 와 pixel shader는 어떻게든 통신이 필요하다는 것입니다. Vertex color 와 같은 보간을 위해서 attribute 를 저장하는 것은 상당한 양의 메모리를 필요로 합니다. Vertex shader 는 vertex 별로 계산 후 다음 vertex 로 이동하지만, pixel shader는 아마 모든 pixel 이 처리되는 동안 기다려야 할 것입니다. 이것은 나중에 알아볼 것이니 지금은 기억만 해두도록 합시다.

몇몇 ALU 가 서로 묶여있고, 이 들이 서로 통신하기 위해서 약간 추가 메모리를 가지는, 이 모델은 "compute shader"와 동시에 소개되었습니다. 실제로는 몇가지 더 세부사항이 있습니다, 예를 들어, compute unit 은 보통 단일 요소를 처리하지 않고 여러개를 사용합니다, 그리고 이 모든 것을 효율적으로 만들기 위해서 관련된 캐시가 몇 개 더 있습니다. 아래 다이어그램은 AMD GCN architecture 의 single compute unit 입니다. 이전에 "compute unit" 이라고 불리던 것은 이제 "SIMD" 입니다, 잠시 후에 더 자세히 알아봅시다.
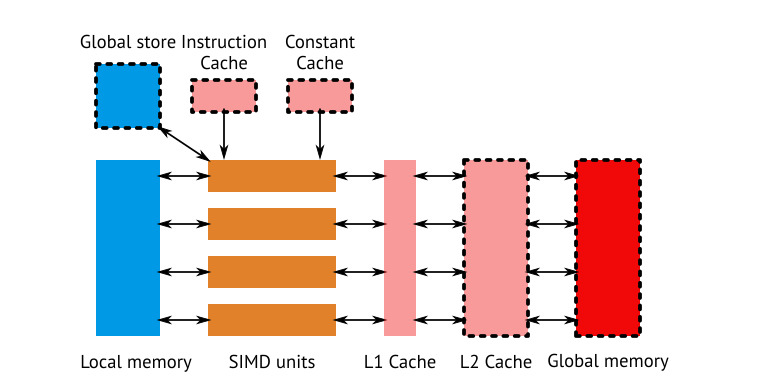
다른 GPU 도 매우 비슷합니다, 나는 GCN 에 가장 익숙하기 때문에 사용했습니다. NVIDIA 하드웨어에서는, GCN compute unit 이 "streaming multiprocessor" 또는 SM 이 됩니다. SIMD 너비가 다르고, 캐시는 약간 다르게 보일 것입니다, 그러나 기본 compute model 은 여전히 정확히 동일합니다. SIMD 유닛으로 돌아와서, GPU는 항상 많은 것들을 동시에 처리하기에 최적화 되어왔습니다. 픽셀을 처리할 곳에는 많은 픽셀이 있고, 모두 동일한 쉐이더를 수행합니다, 그래서 하드웨어는 이렇게 디자인 되었습니다. GCN 의 경우, 디자이너는 16-wide SIMD 4개를 각 compute unit 에 배치했습니다. SIMD (SIMD는 간단히 single instruction multiple data 입니다) unit 은 1개의 연산을 16개의 요소에 한번에 실행할 수 있습니다. 약간의 지연 때문에 1 개의 clock cycle 에서 하지 않습니다, 그러나 GCN 에서, 지연은 4 cycle 입니다, 그래서 4 개의 SIMD 를 가지고, SIMD 가 16이 아니라 64 wide 로 간주하면, 머신은 cycle 당 64 개 명령을 실행하는 것 처럼 동작합니다. 복잡한가요? 걱정마세요, 이것은 그냥 구현상의 세부사항입니다, 여기서의 핵심은 모든 GPU 가 명령어 세트를 같이 수행한다는 것입니다, 같이 수행하는 수는 GCN architecture 는 64개 NVIDIA architecture 는 32 개를 동시에 수행합니다. 결과적으로 GPU 는 여러 compute unit 으로 구성되고, 각 compute unit 은 다음을 포함합니다:
- 명령을 실행하는 SIMD 프로세서의 묶음
- 각 compute unit 의 내부에는 몇 가지 local memory 가 있고, 그것은 shader stage 간 통신에 사용됩니다.
- 각 SIMD unit 은 여러 항목(item)에 대해 1개의 명령을 수행합니다.
이러한 사전조건으로, Pixel 과 Vertex shader 작업을 하지 않을 때, 우리가 그들을 어떻게 노출 시킬 수 있을지 봅시다. 계속 가봅시다.
The kernel
목표는 눈앞에 있는 하드웨어의 활용하도록 하는 프로그래밍 시스템을 작성하는 것입니다. 명백하게, 가장 먼저 우리가 알 수 있는 것은 우리가 cross-compute-unit 통신을 피하고 싶다는 것입니다. 모든 compute unit 은 L2 캐시의 클라이언트 입니다, 그러나 명백히 L1 캐시는 동기화 되지 않을 수 있습니다, 그래서 만약 우리가 작업을 분배하면, 우리는 compute unit 들 사이에 대화할 수 없는 것 처럼 해야 합니다. 이것은 우리가 어떻게든 작업을 더 작은 단위로 분할 해야 함을 의미합니다. 우리는 compute unit 이 없는 척하고, 개별 항목(item)을 dispatch 할 수도 있습니다. 그러나 local memory 에 대해서 놓치고 있습니다, 그래서 "여기에 모든 작업이 있어요" 보다 한 단계 낮은 수준의 내용이 필요한 것으로 보입니다.
우리는 SIMD 수준으로 바로 갈 수 있습니다, 그러나 compute unit 내에서 아직 논의하지 않은 것이기 때문에 최적의 선택은 아닙니다. 우리가 local memory 와 같은 것을 가지고 있기 때문에, 우리가 그것을 SIMD unit 의 동기화에 사용한다고 가정하는 것은 자연스럽습니다(로컬 메모리에서 어떤 것을 기록하고 그것이 보일 때까지 기다릴 수 있다면). 이것은 또한 우리가 single compute unit 내에서 동기화 가능하다는 것을 의미합니다, 그래서 그것들을 다음 그룹 레벨로 사용합니다. 우리는 single compute unit 에 같이 있는 작업들을 work group 이라 부를 것입니다. 우리는 work group 으로 분할 될 수 있는 work domain 에서 부터 시작합니다. 각각의 work group 은 서로 독립적으로 수행됩니다. 개발자가 동시에 얼마나 많은 group 이 수행될 수 있는지 모를 수 있기 때문에, work group 은 다음과 같은 사실에 의존할 수 없도록 강제합니다:
- 같은 Domain 안에 다른 Work group 이 수행 중입니다.
- 한 Domain 내의 Work group은 특정한 순서대로 실행됩니다.
이것은 single unit 에서 다른 work group 후에 work group 을 수행하거나 모든 work group 을 한번에 수행할 수 있게 해줍니다. Work group 내에서, 우리는 여전히 많은 독립적인 work item 이 필요합니다, 그것으로 우리는 모든 SIMD unit 을 채울 수 있습니다. 개별 work item 을 앞으로 work item 이라고 부릅시다, 그리고 우리의 프로그래밍 모델은 많은 work item 을 포함하는 work group 실행합니다-적어도 충분히 1개의 compute unit을 채울 수 있을 정도로(우리는 아마도 그것을 충분히 채우는 것 이상의 것을 원할 것 이지만 이후에 더 알아봅시다)
모든 것을 종합해봅시다: 우리의 domain 은 work group 으로 구성됩니다, 각 work group 은 1개의 compute unit 에 매핑 됩니다, 그리고 SIMD unit 은 work item 을 수행합니다.

우리가 다루지 않은 수준 하나가 더 있습니다. 나는 SIMD unit 이 여러개의 work item 을 같이 실행한다고 했습니다만 우리는 그것을 우리의 프로그래밍 모델에 노출 하지 않았습니다, 우리는 "독립적인" work item 만 갖고 있습니다. 서로 같이 실행되는 work item 에 이름을 붙입시다. 우리는 그것을 subgroup 이라 부를 것입니다(AMD 에서는 보통 "wavefront" or "wave" 라고 부릅니다, 반면에 NVIDIA 는 "warp" 라고 부릅니다.) 이제, 우리는 SIMD 내의 모든 item 들에 대해 작업을 수행하는 또 다른 명령 세트를 노출할 수 있습니다. 예를들어, 우리는 로컬 메모리를 거치지 않고도 모든 값 중 최소값을 계산할 수 있습니다. 나는 순서에 대해서는 제약이 거의 없다고 언급했었습니다. 예를들어, GPU 는 아마도 single compute unit 에서 전체 domain 을 실행하길 원할 수 있습니다. 이것을 하길 원하는 이유 중 하나는 메모리 지연 때문입니다. wide SIMD unit 은 숫자 처리(crunching)에 좋습니다, 그러나 이것은 메모리 접근은 상대적으로 아주 느리다는 것을 의미합니다. 실제로, 끔직하게 느립니다, GCN CU 는 cycle 당 64 개의 float multiply-add 명령을 처리를 할 수 있기 때문입니다. 이것은 64x3x4 byte 의 입력 데이터와 64x5 byte 의 출력 데이터 입니다. Vega10 과 같이 큰 chip 에서 single cycle 에서 48KiB 를 읽을 수 있습니다 - 1.5 GHz 에서, 그것은 67 TiB 의 데이터를 읽습니다. GPU 메모리 시스템은 그래서 지연을 희생하고 처리량에 최적화 되었습니다, 그리고 그것은 우리가 프로그래밍 하는 방식에 영향을 줍니다. 이것이 프로그래밍 모델에 영향을 미치는 것을 보기 전에, Compute shader 가 어떻게 생겼는지 요약해 봅시다:
- Work는 3 수준의 계층 구조로 정의됩니다.
- 몇몇 API 는 중간 수준을 노출시킵니다 - subgroup 은 work group의 아래, work item 의 위 수준입니다.
- Work group 은 내부적으로 동기화 가능하며 local memory 를 통해서 데이터 교환 가능합니다.
이 프로그래밍 모델은 GPU compute shader 에서 보편적입니다. 차이점은 어떤 것을 보증하느냐에 따라 생깁니다, 예를 들어, API는 수행중인 work group 의 수를 제한 하여 그들 모두가 서로 동기화 될 수 있게 해줍니다; 또는 몇몇 하드웨어는 실행 순서를 보장합니다 그래서 당신은 한 work group 에서 다음으로 전달 가능합니다.
Latency hiding & how to write code
이제 우리는 하드웨어와 프로그래밍 모델이 어떤지 이해했습니다, 우리가 어떻게 효율적으로 프로그래밍 할 수 있을까요? 지금까지, 일반적인(normal) 코드를 작성하는 것 같았고 work-item 을 처리하고 잠재적으로 같은 SIMD 의 이웃과 통신하고, local memory 를 통해 통신하며 마지막으로 global memory 를 통해 읽고 쓰는 것이 전부 였습니다. 문제는 “일반적인(normal)” 코드는 좋지 않습니다, 왜냐하면 우리는 지연을 숨길 필요가 있기 때문입니다. GPU 가 지연을 숨기는 방법은 더 많은 작업을 수행하는 것 입니다. 수 많은 작업 - GCN 의 예로, 모든 compute unit 은 40개 까지의 subgroup을 수행할 수 있습니다. subgroup 은 메모리에 접근할 때마다, 다른 subgroup이 스케쥴링 되어 들어옵니다. 한번에 4개만 실행될 수 있다면, 우리가 원래 요청을 시작한 subgroup으로 돌아가기 전에 10번 전환 가능하다는 의미입니다.
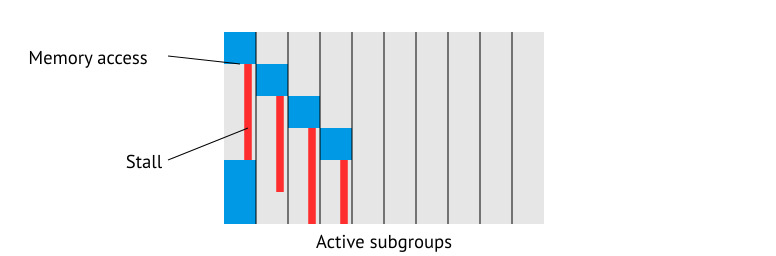
여기서 문제는 - subgroup 전환은 가능한 즉시 일어나야 합니다. 즉, 당신은 프로그램의 상태를 메모리에 기록하고 다시 읽어올 수 없다는 의미입니다. 대신에, 모든 프로그램의 모든 상태는 레스터레 안에서 영구적으로 유지됩니다. 이것은 아주 큰 양의 레지스터를 요구합니다 - GCN 의 single compute unit은 256 KiB 의 레지스터를 가집니다. 이를 통해, 우리는 점유(Occupancy)를 줄이기 전에 (256 KiB / 40 / 4 / 64B) = 24 레지스터까지만 single item에 사용하도록 설정해야 합니다. 우리의 프로그래밍 스타일에서는, 우리가 유지해야 할 상태의 양을 가능하면 최소화 해야 한다는 의미입니다. 만약 우리가 메모리에 접근하지 않는다면, single wave는 SIMD 를 100% 점유로 유지할 수 있습니다. 우리는 local memory 와 L1 캐시를 가능한 사용하고 있는지 확인해야 합니다, 왜냐하면 그들은 외부 메모리에 비해서 더 큰 대역폭과 낮은 지연을 가지기 때문입니다.
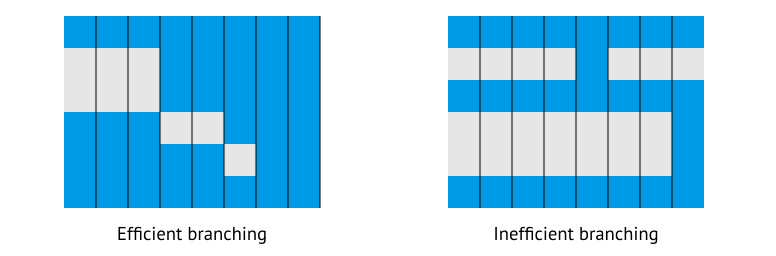
우리가 만날 다른 문제는 branch 를 어떻게 처리할 것인가 입니다. SIMD 는 모든 것을 함께 실행합니다, 그래서 그들은 jump 를 수행할 수 없습니다. 대신에 개별 lane 은 off 로 마스킹 됩니다, 즉, 그들은 더 이상 참여하지 않습니다. 모든 work item 이 같은 branch 를 하지 않는다면, GPU 는 일반적으로 branch 의 앙쪽을 모두 실행한다는 것을 암시합니다. 그래서 N 길이의 SIMD 경우, 우리는 최악의 경우 1/N 의 사용율을 얻을 것 입니다. CPU 에서 N 은 보통 1..8 개입니다, 그래서, 이것은 재앙 수준은 아닙니다, 그러나 GPU 에서 N은 64 까지 올라갈 수 있는데 이점은 정말 중요합니다. 이런 일이 일어나지 않게 하려면 어떻게 해야 할까요? 먼저, subgroup 실행의 장점을 활용해야 합니다. 만약 우리가 저렴한 것과 비싼 것을 선택하는 branch 를 갖고 있다면, 우리는 특정 work item 이 비싼 것을 실행하길 원하는지 찾아낼 수 있습니다. 만약 그렇다면, 우리는 모든 work item 을 비싼 것으로 실행하도록 강제 할 것입니다. 이것은 저렴한 것과 비싼 경로 둘에서 비싼 경로로 변경하여 실행 비용을 줄입니다. 다른 부분은 추가 과도한 branch 를 피하는 것입니다. CPU 의 폭이 더 넓어짐에 따라, 이것은 더 중요해지고 있습니다, 그리고 개별 work item 에서 무거운 branch 를 하는 것 보다 모든 데이터를 먼저 정렬하고 처리하는 것이 더 흥미로워 집니다. 예를들어, 만약 당신이 파티클 시뮬레이션 엔진을 기록하는 중이라면, 모든 가능한 시뮬레이션 프로그램을 각각의 파티클에 대해 실행하는 것에 비해 파티클 타입으로 먼저 정렬하고 특수화된 프로그램을 각각 수행하는 것이 훨씬 더 빠릅니다. 우리가 무엇을 배웠나요? 우리는 다음이 필요합니다:
- 큰 문제 영역(A large problem domain) - 독립적인 work item 일수록 더 좋습니다.
- 메모리 집약적 코드는 높은 점유를 허용하기 위해서 상태를 최소화해야 합니다.
- 우리는 대부분의 subgroup 을 비활성화하는 branch 를 피해야 합니다.
이런 가이드라인은 일반적으로 모든 GPU 에 적용될 것입니다. 결국, 이 모든 것들은 대규모 병렬 그래픽스 프로그램을 해결하기 위해서 설계되었습니다, 그리고 그들은 적은 branch , 실행 중 상태가 너무 많지 않으며, 그리고 수많은 독립적인 work item을 가집니다.
Summary
나는 이 블로그 글이 우리가 어떻게 compute shader 를 가지게 되었는지 잘 알 수 있기를 바랍니다. 정말 흥미로운 것은 최소 통신, local memory 접근, 그리고 divergence 비용 개념은 보편적으로 적용 가능 하다는 것입니다. 현대 멀티 코어 CPU 는 또한 새로운 수준의 통신 비용이 생기고 있습니다, NUMA 는 메모리 접근과 기타 등등을 위한 비용을 모델링 하는데 사용되어 왔습니다. 모든 메모리가 동일하지 않다는 것을 이해하고 기반 하드웨어에서 특정 방법으로 당신의 코드가 수행되는 것을 이해하면 당신은 어디서나 더 많은 성능을 얻을 수 있을 것입니다.
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] Even more compute shaders | Anteru's Blog (0) | 2022.07.30 |
|---|---|
| [번역] More compute shaders | Anteru's Blog (0) | 2022.07.28 |
| [번역] Multiple Importance Sampling in 1D (0) | 2022.04.11 |
| [번역] Monte Carlo Integration Explanation in 1D (0) | 2022.04.09 |
| [번역] Monte Carlo Integration (2) | 2022.03.12 |



