
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SGPR
- GPU Driven Rendering
- scattering
- unrealengine
- Study
- ue4
- RayTracing
- GPU
- SIMD
- hzb
- Graphics
- texture
- DX12
- ShadowMap
- VGPR
- forward
- DirectX12
- rendering
- Shadow
- atmospheric
- UE5
- scalar
- optimization
- wave
- shader
- deferred
- Nanite
- vulkan
- Wavefront
- 번역
- Today
- Total
RenderLog
AsyncCompute - DX12, Vulkan 본문
AsyncCompute - DX12, Vulkan
최초 작성 : 2024-02-13
마지막 수정 : 2024-02-13
최재호
목차
1. 목표
2. 내용
2.1. 사전에 알아야 할 것들
2.1.1. CommandQueue
2.1.2. 동일한 CommandQueue 내 렌더커맨드의 실행 순서
2.1.3. Resource Barrier
2.2. CommandQueue 간의 동기화
2.3. CommandQueue 간의 동기화 구현
2.3.1. 현재 CommandQueue 에서 실행 한 렌더커맨드가 모두 실행될 때까지 기다릴 수 있도록 동기화 정보를 제공
2.3.2. 특정 CommandQueue 가 앞서 다른 CommandQueue 에서 받은 동기화 정보를 사용
2.4. 실제 사용 예제
3. 테스트 케이스
3.1. Graphics Queue 에서 모두 실행하는 경우
3.2. Atmospheric 가 모두 실행된 후 AsyncComputeTest 가 모두 실행되고나서 PostProcess 가 실행된 경우
3.3. Atmospheric 가 모두 실행된 후 AsyncComputeTest 가 수행되고, AsyncComputeTest 와 PostProcessPass 는 겹침
3.4. BasePass 가 모두 실행된 후 AsyncComputeTest 가 수행되고, 이후 모든 패스와 겹침
3.5. ShadowPass 가 모두 실행된 후 AsyncComputeTestPass 가 수행되고, 이후 모든 패스와 겹침
3.6. AsyncComputeTest 가 바로 수행되어 모든 패스와 겹침
4. 레퍼런스
1. 목표
AsyncCompute 를 사용하는데 고려해야 할 것들을 알아봅니다.
DX12, Vulkan 에 AsyncCompute 를 구현하여 테스트해 봅니다.
사전지식
DX12, Vulkan API 렌더링 커맨드의 생성과 실행
Graphics API : Fence, Semaphore
Vulkan 의 vkQueueSubmit 에 사용되는 Signal, Wait semaphore 에 대한 이해
2. 내용
오늘은 AsyncCompute 에 대해서 알아볼 것입니다. GPU 에 렌더커맨드를 전달할 때, 일반적으로 Graphics CommandQueue 에 필요한 렌더커맨드를 제출합니다. 하지만 특정 렌더커맨드는 GPU 내부의 Shader core 를 충분히 채우지 못해서 처리량이 낮을 수 있습니다. 이런 경우 AsyncCompute 가 좋은 대안이 될 수 있습니다. AsyncCompute 는 Graphics CommandQueue 에서 실행 중인 작업과 종속성이 없는 Compute Shader 작업들을 Compute CommandQueue 에 밀어 넣어서 사용하지 못하던 Shader core 를 채울 수 있습니다. 이런 방식으로 작업 처리량을 늘리는 것이 AsyncCompute 를 사용하는 목적입니다.
물론 Graphics CommandQueue 내에서 적절하게 종속성을 잘 관리해 줘서 추가 CommandQueue 사용하지 않아도 되면 좋겠지만 CommandQueue 내에서 관리되는 Barrier 나 다양한 상황에서 이 부분을 완벽하게 해결하기는 어렵습니다. 레퍼런스1 에서는 이런 점을 아주 잘 설명해주고 있습니다. (개인적으로는 레퍼런스2 의 GDC 의 요약본을 먼저 보고 보시는 게 이해하는데 더 쉽다고 생각됩니다.)
AsyncCompute 를 본격적으로 시작하기 전 먼저 알아야 할 부분들을 가볍게 둘러봅시다.
2.1. 사전에 알아야 할 것들
2.1.1. CommandQueue
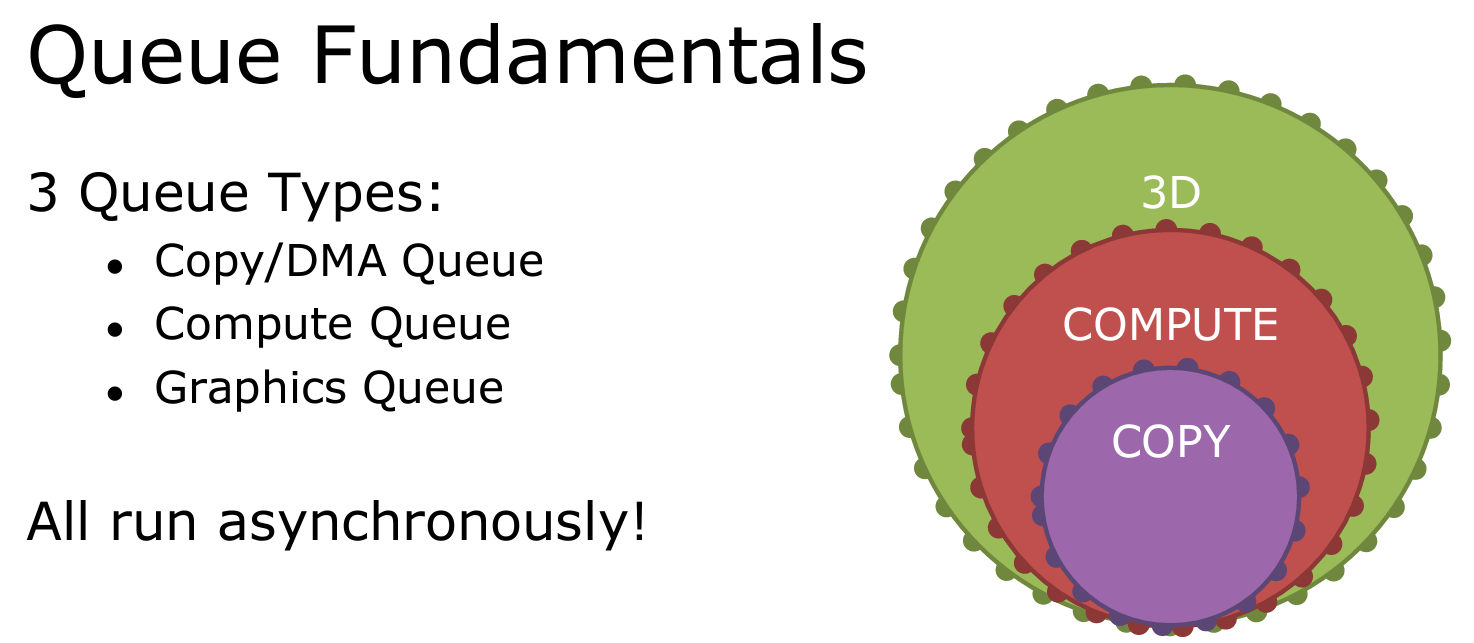
실제 렌더링에 사용되는 렌더커맨드들을 커맨드리스트에 녹화한 다음에 GPU 에게 실행해 달라고 전달해야 하는 통로가 바로 CommandQueue 입니다. CommandQueue 는 총 3가지 타입이 있습니다. 각각의 타입은 하위 타입의 기능을 모두 가지고 있습니다. (Graphics > Compute > Copy)
2.1.2. 동일한 CommandQueue 내 렌더커맨드의 실행 순서
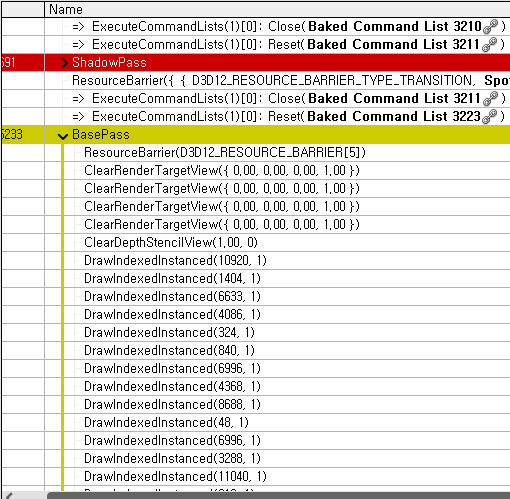
그림2의 렌더독에서 캡처한 렌더커맨드를 보면 모든 커맨드들이 순서대로 실행된 것처럼 보입니다.
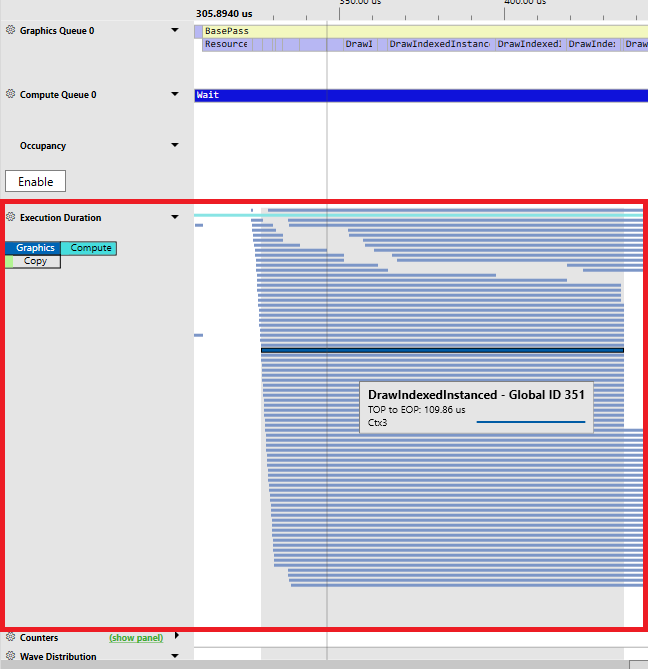
하지만 내부적으로는 렌더커맨드들이 병렬로 동작하고 있습니다. 아래 그림3의 PIX 에서 촬영한 렌더커맨드를 보면 커맨드들이 병렬로 동작하는 것을 볼 수 있습니다.
하지만 항상 렌더커맨드들이 병렬로 실행될 수는 없으며, 렌더커맨드 사이에 종속성이 필요한 경우도 있습니다. 예를 들면 앞서 실행된 렌더커맨드1 은 텍스쳐A 에 렌더링을 하고, 이어서 실행되는 렌더커맨드2 는 렌더커맨드1 을 통해 렌더링 된 텍스쳐A 를 사용하여 추가 처리를 한다고 합시다. 이런 경우는 렌더커맨드1 이 완료된 다음 렌더커맨드2 가 실행되어야 할 것입니다. 그리고 이 실행 순서만 동기화되는 것이 아니라 실행 결과로 갱신된 메모리들도 다른 Shader core 들에서 사용(관찰, Visibility) 할 수 있어야 합니다.
렌더커맨드 사이의 종속성을 관리하기 위해서는 Resource Barrier 를 사용할 수 있습니다.
2.1.3. Resource Barrier
Barrier 는 동일한 CommandQueue 내의 실행 순서 보장(Execution dependency) 와 실행 결과로 갱신된 메모리의 Visibility 를 보장해 줍니다.
DX12 에서는 Resource Barrier, Vulkan 에서는 Pipeline Barrier 라 불리는 기능을 통해 이 과정을 수행합니다.
Barrier 가 어떻게 종속성을 관리할지 생각해 봅시다. 여기서는 DX12 를 기준으로 Barrier 를 소개하겠습니다. Barrier 사용에 대한 차이는 jEngine 의 ResourceBarrierBatcher 클래스를 비교해 볼 수 있습니다.
- Vulkan BarrierBatcher : https://github.com/scahp/jEngine/blob/AsyncCompute/jEngine/RHI/Vulkan/jResourceBarrierBatcher_Vulkan.cpp
- DX12 BarrierBatcher : https://github.com/scahp/jEngine/blob/AsyncCompute/jEngine/RHI/DX12/jResourceBarrierBatcher_DX12.cpp
추가로 Vulkan 의 Pipeline Barrier 의 경우 Execution dependency 와 Memory Visibility 를 더 세밀하게 컨트롤할 수 있습니다. 레퍼런스5 영상에 Vulkan Barrier 에 대한 좋은 내용이 있습니다. 이 글에서는 AsyncCompute 에 초점을 두고 있기 때문에 Barrier 에 대한 더 자세한 내용까지는 다루지 않을 예정입니다.
Barrier 를 사용하는 간단한 예를 확인해 봅시다.
텍스쳐가 하나 있고, 해당 텍스쳐를 D3D12_RESOURCE_STATE_RENDER_TARGET(쓰기) → D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE(읽기) 상태로 Resource Transition 을 요청했다고 합시다. 아래 코드는 DX12 의 Barrier 를 사용하여 리소스 상태를 전환하는 예제입니다.
D3D12_RESOURCE_BARRIER barrier = {};
barrier.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
barrier.Flags = D3D12_RESOURCE_BARRIER_FLAG_NONE;
barrier.Transition.pResource = InResource;
barrier.Transition.StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET;
barrier.Transition.StateAfter = D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE;
barrier.Transition.Subresource = D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES;
CommandList->ResourceBarrier(1, &barrier);
GPU 는 이 Barrier 가 호출된 시점을 기준으로 2가지를 알 수 있을 것입니다.
- Barrier 보다 앞서 실행된 Command 가 텍스쳐 리소스를 RenderTarget 으로 사용하여 데이터를 기록함.
- Barrier 의 실행 이후 다음 실행된 Command 가 해당 텍스쳐의 데이터를 PixelShader 내에서 읽는 데 사용함.
이 정보를 알고 있다면 Barrier 전/후 렌더커맨드는 서로 실행에 종속성이 걸려있고, Memory visibility 또한 보장되어야 한다고 알 수 있을 것입니다.
앞에서 설명한 종속성은 Resource 가 기록되고 읽혀지는 상태 기반으로 종속성을 알아냅니다. 하지만 Compute Shader 가 연속적으로 실행된다면 어떨까요? Compute Shader 는 UAV 타입의 리소스를 사용하여 읽기/쓰기를 동시에 처리할 수 있습니다. Compute Shader 1, 2, 3 이 차례로 실행되지만 Resource Transition 이 전혀 필요 없을 수 있습니다. 이럴 때 사용할 수 있는 것이 UAV Barrier 입니다. 아래 코드를 참고해 주세요.
D3D12_RESOURCE_BARRIER barrier = {};
barrier.Type = D3D12_RESOURCE_BARRIER_TYPE_UAV;
barrier.UAV.pResource = InResource;
CommandList->ResourceBarrier(1, &barrier);
2.2. CommandQueue 간의 동기화
다시 AsyncCompute 로 돌아왔습니다. AsyncCompute 는 Graphics ComandQueue 에 전달한 작업이 GPU 의 Shader core 사용율을 가득 채울 수 없는 경우에 Compute CommandQueue 를 통해 추가로 렌더커맨드를 제출하여 Shader core 의 사용율 높일 수 있다고 하였습니다. Compute CommandQueue 에서 실행이 마친 후 생성된 데이터(텍스쳐나 버퍼)는 Graphics CommandQueue 에서 사용되어서 최종 결과물에 영향을 미칠 것입니다. 그렇다는 말은 AsyncCompute 를 사용하기 위해서는 CommandQueue 간의 동기화 기능이 추가로 필요하다는 것입니다.
예를 들면, Graphics Queue 에서 ShadowDepth 를 렌더링하는 동안 Compute Command Queue 에서 SSAO 작업을 동시에 수행합니다. 그리고 Graphics Queue 에서 Compute CommandQueue 에서 생성한 SSAO 를 최종 렌더타겟에 적용합니다.
이런 과정을 위해서는 CommandQueue 간의 동기화를 책임져줄 동기화 객체가 필요합니다. 아래 그림4는 Fence 를 사용하여 CommandQueue 간의 동기화를 맞추는 것을 보여줍니다.
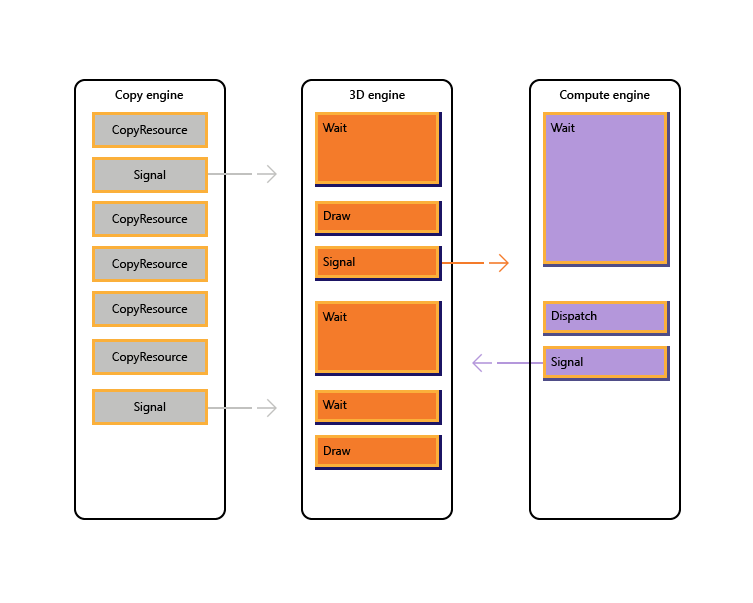
위에서 본 것처럼 DX12 는 CommandQueue 간의 동기화를 위해서 Fence 를 사용합니다. Fence 는 CPU ↔ GPU 간의 동기화에도 사용할 수 있고 CommandQueue 의 Signal, Wait 함수를 통하여 동기화를 구현합니다. Fence 에 대한 더 자세한 설명은 레퍼런스6 을 참고해 주세요.
Vulkan 의 경우는 Semaphore 나 Fence 를 사용할 수 있는데 여기서는 Timeline Semaphore 를 사용하여 동기화 하는 것을 알아볼 예정입니다. Timeline Semaphore 는 DX12 의 Fence 와 같이 내부적으로 uint64 변수를 갖고 있으며 계속해서 해당 값이 증가하는 형태로 구현됩니다. Timeline Semaphore 에 대해서는 레퍼런스5 를 확인해주세요. Fence 로도 동기화 할 수 있지만 Fence 의 경우 CPU ↔ GPU 간의 동기화까지 고려하고 있습니다. 여기서는 CommandQueue 간의 동기화만 만들면 되기 때문에 GPU 의 Queue 간의 동기화만 할 수 있는 Timeline Semaphore 를 선택하는 것이 좋다고 생각했습니다.
2.3. CommandQueue 간의 동기화 구현
AsyncCompute 에 실행할 작업을 특정 렌더패스(Graphics Queue 를 사용하는)에서 발행하고, Compute Queue 의 작업을 기다렸다가 작업을 마친 결과를 특정 렌더패스에서 사용하는 형태로 사용하게 될 것입니다.
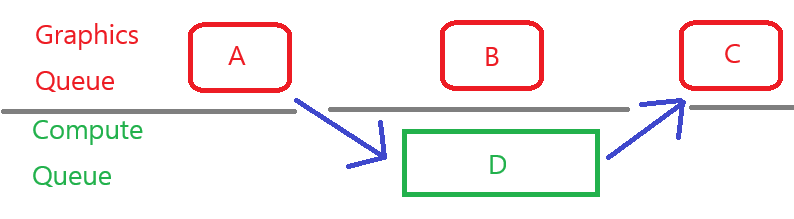
이 부분을 고려해 봤을 때, 구현해야 할 기능은 크게 2가지입니다.
- 현재 CommandQueue 에서 실행 한 렌더커맨드가 모두 실행될 때까지 기다릴 수 있도록 동기화 정보를 제공
- 특정 CommandQueue 가 앞서 다른 CommandQueue 에서 받은 동기화 정보를 사용하여 해당 동기화 지점까지 렌더커맨드가 실행되는 것을 기다릴 수 있어야 함.
2.3.1. 현재 CommandQueue 에서 실행 한 렌더커맨드가 모두 실행될 때까지 기다릴 수 있도록 동기화 정보를 제공
현재 CommandQueue 에 전달한 렌더커맨드가 잘 실행되었는지 알 수 있으려면 아래 내용들이 필요할 것입니다.
- 어떤 CommandQueue 에 렌더커맨드를 넣었나?
- CommandQueue 의 실행이 완료되었음을 알 수 있는 동기화 객체
jEngine 에서는 jSyncAcrossComputeQueue 를 통해서 위의 정보를 넣어줬습니다.
// Make a syncronization between CommandQueues(Graphics, Compute, Copy)
struct jSyncAcrossCommandQueue : std::enable_shared_from_this<jSyncAcrossCommandQueue>
{
virtual ~jSyncAcrossCommandQueue() {}
virtual void WaitSyncAcrossCommandQueue(ECommandBufferType InWaitCommandQueueType) {};
};
// DX12 is using Fence for sync between CommandQueues
struct jSyncAcrossCommandQueue_DX12 : public jSyncAcrossCommandQueue
{
jSyncAcrossCommandQueue_DX12(ECommandBufferType InType, jFence_DX12* InFence, uint64 InFenceValue = -1);
virtual ~jSyncAcrossCommandQueue_DX12() {}
virtual void WaitSyncAcrossCommandQueue(ECommandBufferType InWaitCommandQueueType) override;
ECommandBufferType Type = ECommandBufferType::MAX;
jFence_DX12* Fence = nullptr;
uint64 FenceValue = 0;
};
// Vulkan is using Semaphore for sync between CommandQueues
struct jSyncAcrossCommandQueue_Vulkan : public jSyncAcrossCommandQueue
{
jSyncAcrossCommandQueue_Vulkan(ECommandBufferType InType, jSemaphore_Vulkan* InWaitSemaphore, uint64 InSemaphoreValue = -1);
virtual ~jSyncAcrossCommandQueue_Vulkan() {}
virtual void WaitSyncAcrossCommandQueue(ECommandBufferType InWaitCommandQueueType) override;
ECommandBufferType Type = ECommandBufferType::MAX;
jSemaphore_Vulkan* WaitSemaphore = nullptr;
uint64 SemaphoreValue = 0; // for timeline semaphore
};
2.3.2. 특정 CommandQueue 가 앞서 다른 CommandQueue 에서 받은 동기화 정보를 사용
이제 jSyncAcrossComputeQueue 를 갖고 있으면 언제든 WaitSyncAcrossComputeQueue 함수를 사용하여 앞서 다른 CommandQueue 에서 실행한 렌더커맨드의 실행을 기다릴 수 있습니다.
DX12 와 Vulkan 에서의 구현이 각각 다른데 차례로 알아봅시다.
DX12 의 경우는 Fence 를 사용하기 때문에 간단히 CommandQueue 에 Wait 함수를 호출하여 Fence 가 Signal 되기를 기다립니다. 아래 코드를 확인해 주세요.
// Passing jSyncAcrossCommandQueue to TargetCommandQueue that want to wait for
void jSyncAcrossCommandQueue_DX12::WaitSyncAcrossCommandQueue(ECommandBufferType InWaitCommandQueueType)
{
if (!ensure(InWaitCommandQueueType != Type)) // Can't wait same type queue
return;
auto CommandBufferManager = g_rhi->GetCommandBufferManager(InWaitCommandQueueType);
CommandBufferManager->WaitCommandQueueAcrossSync(shared_from_this());
}
// The CommandQueue wait for Fence of jSyncAcrossCommandQueue
void jCommandBufferManager_DX12::WaitCommandQueueAcrossSync(const std::shared_ptr<jSyncAcrossCommandQueue>& InSync)
{
auto Sync_DX12 = (jSyncAcrossCommandQueue_DX12*)InSync.get();
CommandQueue->Wait(Sync_DX12->Fence->Fence.Get(), Sync_DX12->FenceValue);
}
Vulkan 의 경우 즉시 Wait 되는 것이 아니라 vkQueueSubmit 이 호출되는 시점에 Semaphore 를 같이 전달하여 종속성을 만들어 줍니다. 그래서 WaitSyncAcrossCommandQueue 를 호출하면 즉시 동기화 지점을 기다리지 않고, jSyncAcrossCommandQueue 가 가지고 있는 동기화 객체를 기다릴 CommandQueue 에 다음 vkQueueSubmit 이 있을 때 해당 동기화 객체를 사용할 수 있게 등록만 합니다. 그리고 최종적으로 vkQueueSubmit 이 진행될 때 동기화 객체로부터 WaitSemaphore 와 WaitSemaphoreValue 를 추출하여 전달합니다. 아래 코드를 확인해 주세요.
// Enqueued jSyncAcrossCommandQueue to WaitSemaphoreAcrossQueues then use it at vkQueueSubmit.
void jCommandBufferManager_Vulkan::WaitCommandQueueAcrossSync(
const std::shared_ptr<jSyncAcrossCommandQueue>& InSync)
{
WaitSemaphoreAcrossQueues.push_back(InSync);
}
// Extract Semaphore and Semaphore Value which to wait, It will use at vkQueueSubmit.
void jCommandBufferManager_Vulkan::GetWaitSemaphoreAndValueThenClear(
std::vector<VkSemaphore>& InOutSemaphore, std::vector<uint64>& InOutSemaphoreValue)
{
if (WaitSemaphoreAcrossQueues.empty())
return;
check(InOutSemaphore.size() == InOutSemaphoreValue.size());
InOutSemaphore.reserve(InOutSemaphore.size() + WaitSemaphoreAcrossQueues.size());
InOutSemaphoreValue.reserve(InOutSemaphoreValue.size() + WaitSemaphoreAcrossQueues.size());
for(int32 i=0;i< WaitSemaphoreAcrossQueues.size();++i)
{
auto Sync_Vulkan = (jSyncAcrossCommandQueue_Vulkan*)WaitSemaphoreAcrossQueues[i].get();
InOutSemaphore.push_back(Sync_Vulkan->WaitSemaphore->Semaphore);
InOutSemaphoreValue.push_back(Sync_Vulkan->SemaphoreValue);
}
WaitSemaphoreAcrossQueues.clear();
}
// Submit commandqueue the commandBuffer
std::shared_ptr<jSyncAcrossCommandQueue_Vulkan> jCommandBufferManager_Vulkan::QueueSubmit(
jCommandBuffer_Vulkan* InCommandBuffer, jSemaphore* InWaitSemaphore, jSemaphore* InSignalSemaphore)
{
...
// Extract Semaphore and Semaphore Value which to wait
std::vector<VkSemaphore> WaitSemaphores;
std::vector<uint64> WaitSemaphoreValues;
CurrentInCommandBufferManager->GetWaitSemaphoreAndValueThenClear(WaitSemaphores, WaitSemaphoreValues);
// Added WaitSemaphore which will signal from previous vkQueueSubmit.
if (InWaitSemaphore)
{
WaitSemaphores.push_back((VkSemaphore)InWaitSemaphore->GetHandle());
WaitSemaphoreValues.push_back(InWaitSemaphore->GetValue());
}
check(WaitSemaphoreValues.size() == WaitSemaphores.size());
...
uint64 signalValue = 0;
const bool UseWaitTimeline = InWaitSemaphore && InWaitSemaphore->GetType() == ESemaphoreType::TIMELINE;
const bool UseSignalTimeline = InSignalSemaphore && InSignalSemaphore->GetType() == ESemaphoreType::TIMELINE;
// The timeline semaphore needs additional structure of VkTimelineSemaphoreSubmitInfo.
VkTimelineSemaphoreSubmitInfo timelineSemaphoreSubmitInfo = {};
if (UseWaitTimeline || UseSignalTimeline)
{
timelineSemaphoreSubmitInfo.sType = VK_STRUCTURE_TYPE_TIMELINE_SEMAPHORE_SUBMIT_INFO;
timelineSemaphoreSubmitInfo.waitSemaphoreValueCount = (uint32)WaitSemaphoreValues.size();
timelineSemaphoreSubmitInfo.pWaitSemaphoreValues = WaitSemaphoreValues.data();
signalValue = InSignalSemaphore->IncrementValue();
timelineSemaphoreSubmitInfo.signalSemaphoreValueCount = 1;
timelineSemaphoreSubmitInfo.pSignalSemaphoreValues = &signalValue;
submitInfo.pNext = &timelineSemaphoreSubmitInfo;
}
std::vector<VkPipelineStageFlags> WaitStages(WaitSemaphores.size(), WaitStage);
// Set WaitSemaphores to vkSubmitInfo
submitInfo.pWaitSemaphores = WaitSemaphores.data();
submitInfo.waitSemaphoreCount = (uint32)WaitSemaphores.size();
submitInfo.pWaitDstStageMask = WaitStages.data();
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &vkInCommandBuffer;
...
// Do QueueSubmit
auto queueSubmitResult = vkQueueSubmit(CurrentQueue.Queue, 1, &submitInfo, vkFence);
...
// Make a jSyncAcrossCommandQueue_Vulkan for subsequent vkQueueSubmit
return std::make_shared<jSyncAcrossCommandQueue_Vulkan>(InCommandBuffer->Type, (jSemaphore_Vulkan*)InSignalSemaphore);
}
2.4. 실제 사용 예제
아래 예제는 jEngine 의 AsyncCompute 를 사용하는 코드 예제입니다.
1. 맨 첫줄은 jRenderFrameContext 에서 AsyncComputeRenderFrameContext 를 생성합니다.
2. AsyncCompute 에 실행할 커맨드를 녹화합니다.
3. Compute CommandQueue 제출하는 과정을 보여줍니다. CommandQueue 에 제출한 후에 제출한 작업을 기다릴 수 있도록 하기 위해서 jSyncAcrossCommandQueue 를 생성하여 SyncPtr 에 담아줍니다.
4. 마지막 줄에 있는 SyncPtr->WaitSyncAcrossCommandQueue(ECommandBufferType::GRAPHICS) 는 제출한 Compute Queue 를 다음에 제출할 Graphics Queue 에 작업을 제출하기 전에 완료해 달라는 의미입니다.
// 1. 어싱크 컴퓨트 용 jRenderFrameContext 를 생성함. 이제 이 Context 를 통해서 렌더커맨드를 전송하면 Compute Queue 에 들어감.
// - 이 때 전달한 SyncAcrossCommandQueuePtr 이 nullptr 이 아니면 해당 동기화 객체를 기다림.
std::shared_ptr<jRenderFrameContext> AsyncRenderFrameContextPtr
= RenderFrameContextPtr->CreateRenderFrameContextAsync(SyncAcrossCommandQueuePtr);
...
// 2. 렌더커맨드 녹화
...
// 3. 렌더커맨드 CommandQueue 에 서밋
auto SyncPtr = AsyncRenderFrameContextPtr->SubmitCurrentActiveCommandBuffer(jRenderFrameContext::None, false);
// 4. AsyncCompute 에 Submit 한 렌더커맨드의 실행을 후속 Graphics CommandQueue 가 기다려야 하는 경우 아래 코드 실행.
if (gOptions.WaitSubsequentGraphicsQueueTask)
SyncPtr->WaitSyncAcrossCommandQueue(ECommandBufferType::GRAPHICS);
3. 테스트 케이스
이 테스트 케이스는 https://github.com/scahp/jEngine/tree/AsyncCompute 를 사용하여 진행했습니다.
렌더패스는 아래와 같은 형태로 구성됩니다. 그리고 AsyncCompute 를 테스트하기 위해서 “AsyncComputeTestPass(A→B→C)” 패스를 만들었습니다.
ShadowPass → BasePass → AtmosphericPass → AsyncComputeTestPass(A→B→C) → PostProcessPass
아래 코드는 AsyncComputeTest 함수입니다.
- AsyncComputeTest 에서 실행되는 렌더커맨드 A, B, C 는 Compute CommandQueue 에서 실행됩니다.
- 사전에 다른 CommandQueue 에 들어간 다른 렌더커맨드를 기다릴 수 있도록 std::shared_ptr<jSyncAcrossCommandQueue> SyncAcrossCommandQueuePtr 를 Argument 로 전달받습니다. (None, ShadowPass, BasePass, AtmosphericPass 이 될 수 있음)
- AsyncComputeTestPass 의 후속 작업에는 PostProcessPass 가 있습니다. 그래서 PostProcess 가 실행되기 전 AsyncComputeTestPass 를 완료를 기다릴지 여부를 결정할 수 있습니다.
void jRenderer::AsyncComputeTest(std::shared_ptr<jSyncAcrossCommandQueue> SyncAcrossCommandQueuePtr)
{
...
{
std::shared_ptr<jRenderFrameContext> CurrentRenderFrameContextPtr = gOptions.UseAsyncComputeQueue ? RenderFrameContextPtr->CreateRenderFrameContextAsync(SyncAcrossCommandQueuePtr) : RenderFrameContextPtr;
...
// 1. AsyncComputeTest_A 제출
{
SCOPE_CPU_PROFILE(AsyncComputeTest_A);
SCOPE_GPU_PROFILE(CurrentRenderFrameContextPtr, AsyncComputeTest_A);
DEBUG_EVENT_WITH_COLOR(CurrentRenderFrameContextPtr, "AsyncComputeTest_A", Vector4(0.8f, 0.0f, 0.0f, 1.0f));
jRHIUtil::DispatchCompute(CurrentRenderFrameContextPtr, AsyncComputeTestPtr->GetTexture()
, [&](const std::shared_ptr<jRenderFrameContext>& RenderFrameContextPtr, jShaderBindingArray& InOutShaderBindingArray, jShaderBindingResourceInlineAllocator& InOutResourceInlineAllactor)
{
InOutShaderBindingArray.Add(jShaderBinding::Create(InOutShaderBindingArray.NumOfData, 1, EShaderBindingType::UNIFORMBUFFER_DYNAMIC, EShaderAccessStageFlag::COMPUTE
, InOutResourceInlineAllactor.Alloc<jUniformBufferResource>(OneFrameUniformBuffer.get()), true));
}
, [](const std::shared_ptr<jRenderFrameContext>& InRenderFrameContextPtr)
{
jShaderInfo shaderInfo;
shaderInfo.SetName(jNameStatic("AyncComputeTestCS"));
shaderInfo.SetShaderFilepath(jNameStatic("Resource/Shaders/hlsl/AyncComputeTest_cs.hlsl"));
shaderInfo.SetShaderType(EShaderAccessStageFlag::COMPUTE);
shaderInfo.SetEntryPoint(jNameStatic("AsyncComputeTest_A"));
jShader* Shader = g_rhi->CreateShader(shaderInfo);
return Shader;
}
);
}
g_rhi->UAVBarrier(CurrentRenderFrameContextPtr->GetActiveCommandBuffer(), AsyncComputeTestPtr->GetTexture());
// 2. AsyncComputeTest_B 제출
{
SCOPE_CPU_PROFILE(AsyncComputeTest_B);
SCOPE_GPU_PROFILE(CurrentRenderFrameContextPtr, AsyncComputeTest_B);
DEBUG_EVENT_WITH_COLOR(CurrentRenderFrameContextPtr, "AsyncComputeTest_B", Vector4(0.0f, 0.8f, 0.0f, 1.0f));
jRHIUtil::DispatchCompute(CurrentRenderFrameContextPtr, AsyncComputeTestPtr->GetTexture()
, [&](const std::shared_ptr<jRenderFrameContext>& RenderFrameContextPtr, jShaderBindingArray& InOutShaderBindingArray, jShaderBindingResourceInlineAllocator& InOutResourceInlineAllactor)
{
InOutShaderBindingArray.Add(jShaderBinding::Create(InOutShaderBindingArray.NumOfData, 1, EShaderBindingType::UNIFORMBUFFER_DYNAMIC, EShaderAccessStageFlag::COMPUTE
, InOutResourceInlineAllactor.Alloc<jUniformBufferResource>(OneFrameUniformBuffer.get()), true));
}
, [](const std::shared_ptr<jRenderFrameContext>& InRenderFrameContextPtr)
{
jShaderInfo shaderInfo;
shaderInfo.SetName(jNameStatic("AyncComputeTestCS"));
shaderInfo.SetShaderFilepath(jNameStatic("Resource/Shaders/hlsl/AyncComputeTest_cs.hlsl"));
shaderInfo.SetShaderType(EShaderAccessStageFlag::COMPUTE);
shaderInfo.SetEntryPoint(jNameStatic("AsyncComputeTest_B"));
jShader* Shader = g_rhi->CreateShader(shaderInfo);
return Shader;
}
);
}
g_rhi->UAVBarrier(CurrentRenderFrameContextPtr->GetActiveCommandBuffer(), AsyncComputeTestPtr->GetTexture());
// 3. AsyncComputeTest_C 제출
{
SCOPE_CPU_PROFILE(AsyncComputeTest_C);
SCOPE_GPU_PROFILE(CurrentRenderFrameContextPtr, AsyncComputeTest_C);
DEBUG_EVENT_WITH_COLOR(CurrentRenderFrameContextPtr, "AsyncComputeTest_C", Vector4(0.0f, 0.0f, 0.8f, 1.0f));
jRHIUtil::DispatchCompute(CurrentRenderFrameContextPtr, AsyncComputeTestPtr->GetTexture()
, [&](const std::shared_ptr<jRenderFrameContext>& RenderFrameContextPtr, jShaderBindingArray& InOutShaderBindingArray, jShaderBindingResourceInlineAllocator& InOutResourceInlineAllactor)
{
InOutShaderBindingArray.Add(jShaderBinding::Create(InOutShaderBindingArray.NumOfData, 1, EShaderBindingType::UNIFORMBUFFER_DYNAMIC, EShaderAccessStageFlag::COMPUTE
, InOutResourceInlineAllactor.Alloc<jUniformBufferResource>(OneFrameUniformBuffer.get()), true));
}
, [](const std::shared_ptr<jRenderFrameContext>& InRenderFrameContextPtr)
{
jShaderInfo shaderInfo;
shaderInfo.SetName(jNameStatic("AyncComputeTestCS"));
shaderInfo.SetShaderFilepath(jNameStatic("Resource/Shaders/hlsl/AyncComputeTest_cs.hlsl"));
shaderInfo.SetShaderType(EShaderAccessStageFlag::COMPUTE);
shaderInfo.SetEntryPoint(jNameStatic("AsyncComputeTest_C"));
jShader* Shader = g_rhi->CreateShader(shaderInfo);
return Shader;
}
);
}
// 4. AsyncCompute 작업 Queue 에 제출 후, 후속 Graphics Queue 작업이 시작되기전 Compute CommandQueue 에 들어간 작업을 완료해달라고 요청
if (gOptions.UseAsyncComputeQueue)
{
auto SyncPtr = CurrentRenderFrameContextPtr->SubmitCurrentActiveCommandBuffer(jRenderFrameContext::None, false);
if (gOptions.WaitSubsequentGraphicsQueueTask)
SyncPtr->WaitSyncAcrossCommandQueue(ECommandBufferType::GRAPHICS);
}
}
}
아래의 AsyncCompute 조정 UI 를 통해서 AsyncCompute 기능을 테스트합니다.
- UseAsyncComputeQueue 는 AsyncCompute 활성 여부입니다.
- WaitPrerequsiteGraphicsQueueTask 는 AsyncCompute 실행 전에 실행 완료를 보장해야 할 Graphics 렌더패스입니다.
- WaitSubsequentGraphicsQueueTask 는 AsyncCompute 실행 후에 다음 Graphics 렌더패스 실행 전에 AsyncCompute 의 작업이 완료 되도록 보장할지 여부입니다. 만약 이 옵션이 켜져 있다면, AsyncComputeTest 단계와 PostProcess 는 겹칠 수 없습니다.
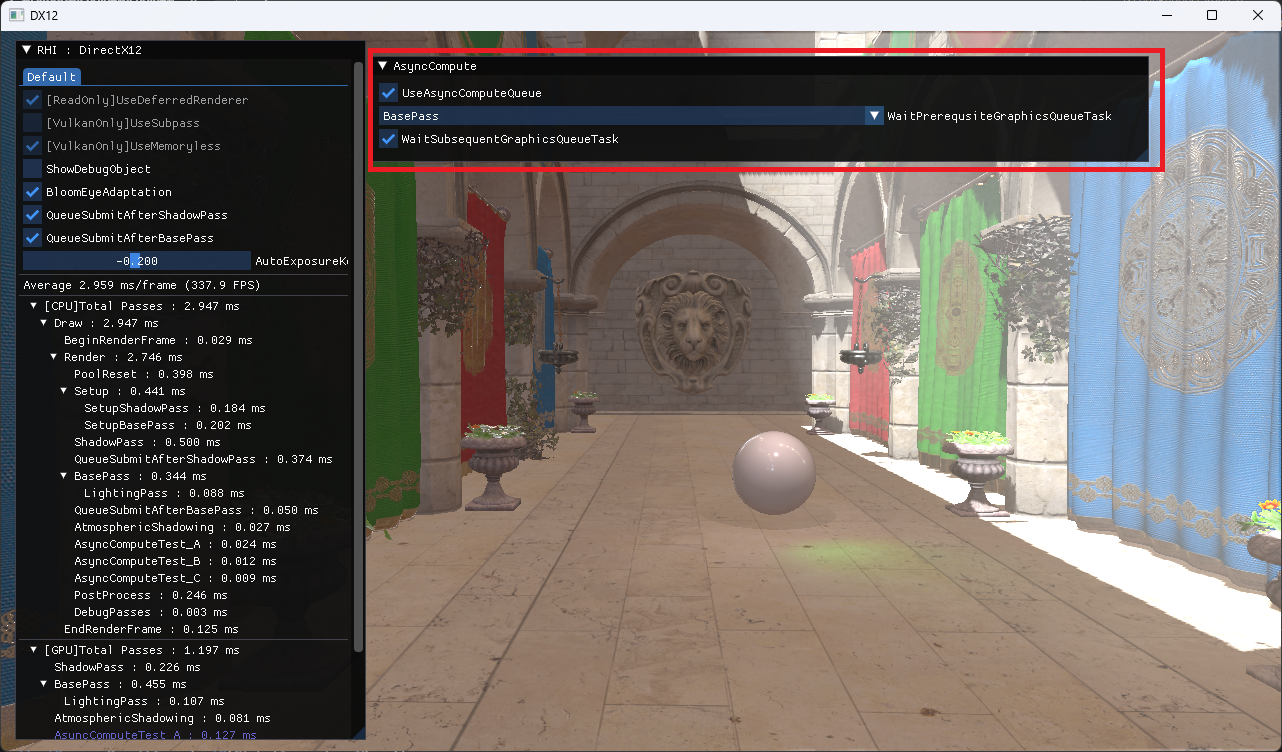
렌더커맨드가 잘 겹쳐서 실행되는지 여부는 Nvidia Nsight 를 통해서 확인합니다. 이 프로그램은 Nvidia 그래픽 카드에서만 작동합니다.
Nsight 에 표시되는 1 frame 에 소모된 GPU time 은 실행시마다 캡쳐 상황에 따라 다르기 때문에 큰 의미를 두지 않고 봐주세요.
3.1. Graphics Queue 에서 모두 실행하는 경우


3.2. Atmospheric 가 모두 실행된 후 AsyncComputeTest 가 모두 실행되고나서 PostProcess 가 실행된 경우
그림9를 봐주세요. Nsight 는 Vulkan 의 경우 Semaphore 의 Signal, Wait 연결을 보여줍니다. Signal or Wait 를 선택하면 연결된 Signal or Wait 를 빨간 선으로 연결해서 보여줍니다. Signal 의 경우 초록색, Wait 의 경우를 노란색 박스로 표시하였습니다. AsyncComputeTest 작업들이 AtmosphericPass 가 끝나고 호출되는 Signal 을 기다리고 있는 것을 확인할 수 있습니다. 그리고 PostProcess 는 AsyncComputeTest 패스가 호출하는 Signal 을 기다리고 있는 것을 볼 수 있습니다.
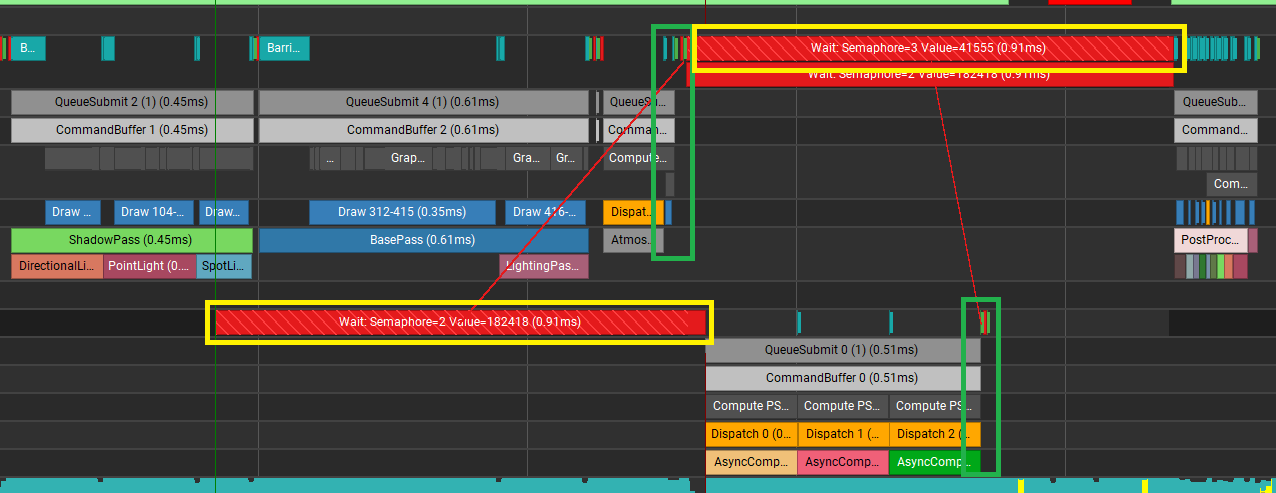
DX12 의 경우는 별도의 Fence 에 대한 정보를 보여주진 않습니다. 하지만 AtmosphericPass 와 AsyncComputeTest, PostProcess 가 겹치지 않고 잘 동작한 것을 확인할 수 있습니다.
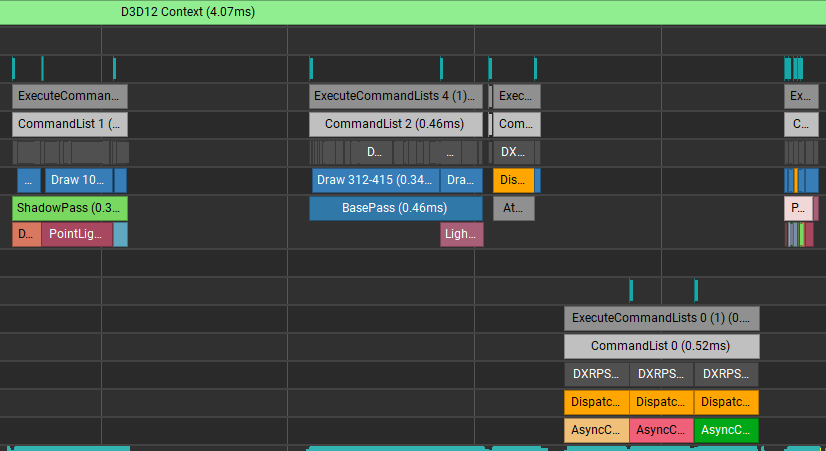
3.3. Atmospheric 가 모두 실행된 후 AsyncComputeTest 가 수행되고, AsyncComputeTest 와 PostProcessPass 는 겹침
이 경우는 AsyncComputeTest 에서 생성된 jSyncAcrossCommandQueue 를 후속 작업으로 올 Graphics 렌더패스(PostProcess) 가 사용하지 않는 상황입니다. 예상대로 AtmosphericPass 와 AsyncComputeTest 사이에만 종속성이 걸려있기 때문에 AsyncComputeTest 와 PostProcess 가 잘 겹쳐서 실행되는 것을 볼 수 있습니다.
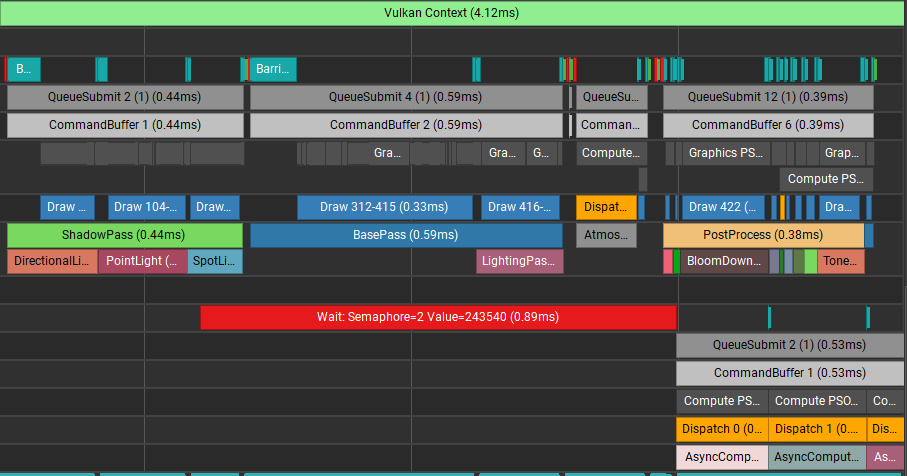
3.4. BasePass 가 모두 실행된 후 AsyncComputeTestPass 가 수행되고, 이후 모든 패스와 겹침
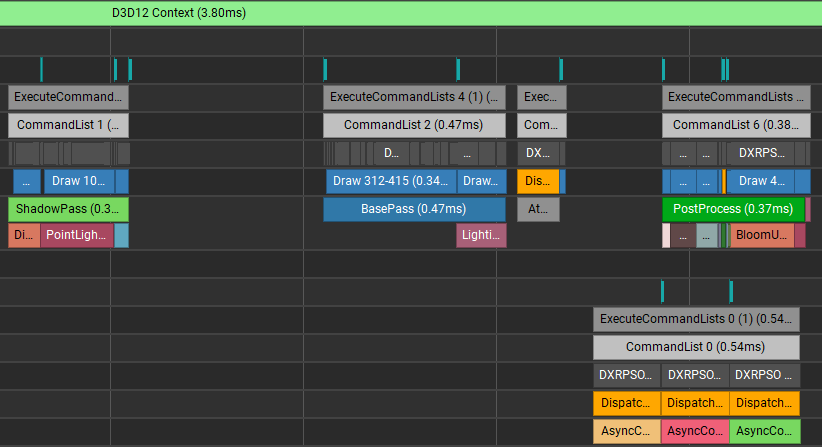
이제 AsyncComputeTest 가 Graphics CommandQueue 의 BasePass 의 실행 완료만 기다리고, 이후 과정은 Graphics Compute CommandQueue 가 겹쳐서 실행되는 예제입니다. Vulkan, DX12 모두 비슷한 결과를 볼 수 있습니다.
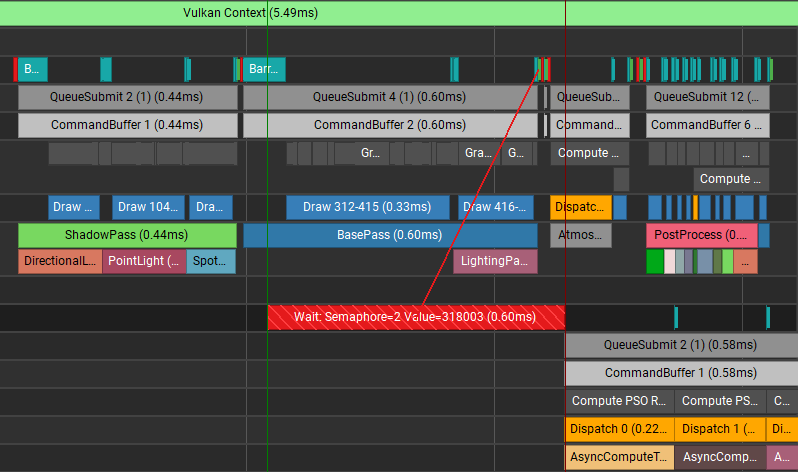
3.5. ShadowPass 가 모두 실행된 후 AsyncComputeTestPass 가 수행되고, 이후 모든 패스와 겹침
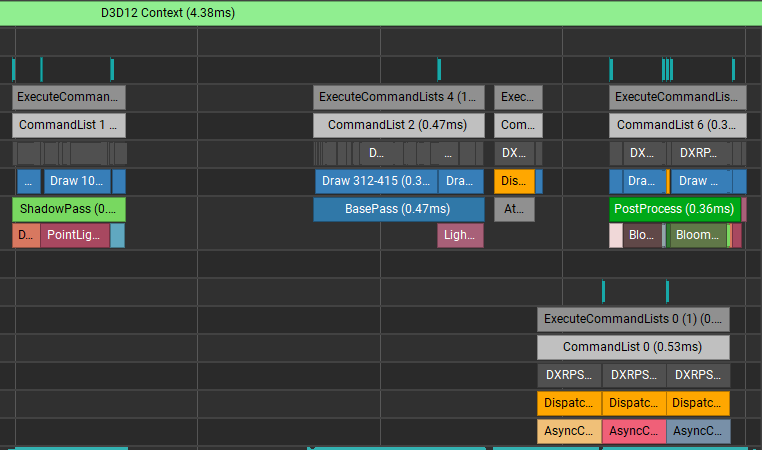
조금 더 당겨서 ShadowPass 실행 완료된 후 바로 AsyncComputeTest 를 겹쳐서 실행하는 예제입니다. BasePass 부터 같이 겹쳐서 실행되는 것을 볼 수 있습니다.
이번 케이스의 경우 오히려 BasePass 와 AsyncComputeTest 의 실행시간이 더 길어졌습니다. 이런 경우 AsyncCompute 에 사용할 Shader core 가 충분히 남아있지 않거나 또는 다른 이슈(캐시 쓰레싱, 계산 부하) 때문에 Graphics 와 Compute 작업이 서로 경쟁하게 된 상황일 수 있습니다. 이 경우 Nsight 에서 제공하는 지표를 확인하여 서로 겹쳐서 실행하기 좋은 렌더패스인지 확인해 보는 것이 좋습니다. 만약 확인 결과 서로 겹쳐서 실행하기 어려운 경우 AsyncCompute 를 사용하지 않는 편이 더 나을 것입니다.
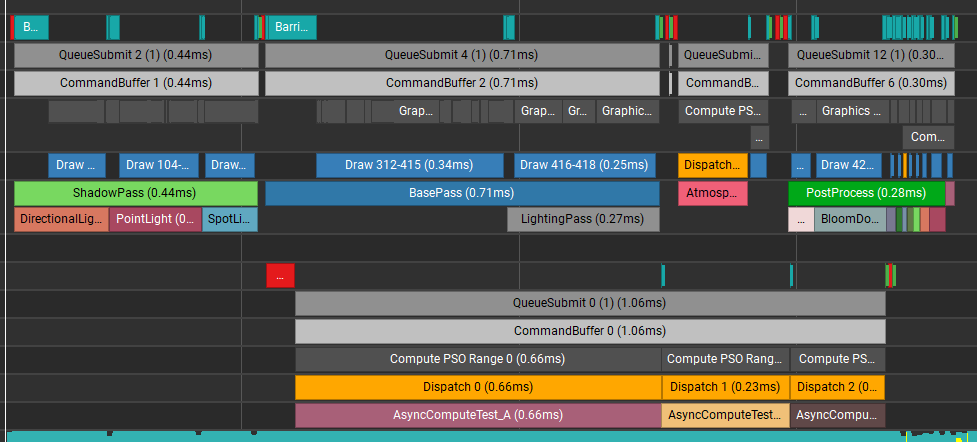
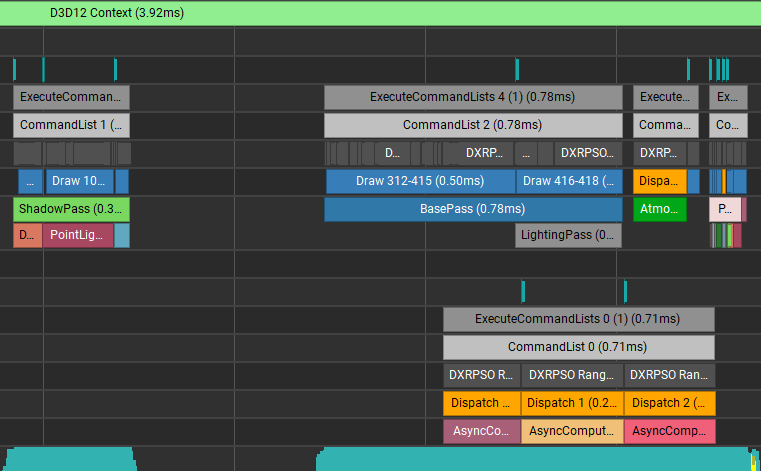
3.6. AsyncComputeTest 가 바로 수행되어 모든 패스와 겹침
마지막으로 AsyncComputeTestPass 를 즉시 실행 할 수 있도록 하였습니다. 이전에 관찰되던 AsyncComputeTest 의 앞에 있던 Semaphore 가 없는 것도 확인할 수 있습니다. CommandQueue 제출한 렌더커맨드가 즉시 실행되는 것이 아니라 Driver 나 OS 에 의해 적절한 스케쥴링이 적용되기 때문에 이런 결과가 나온 것 같습니다.

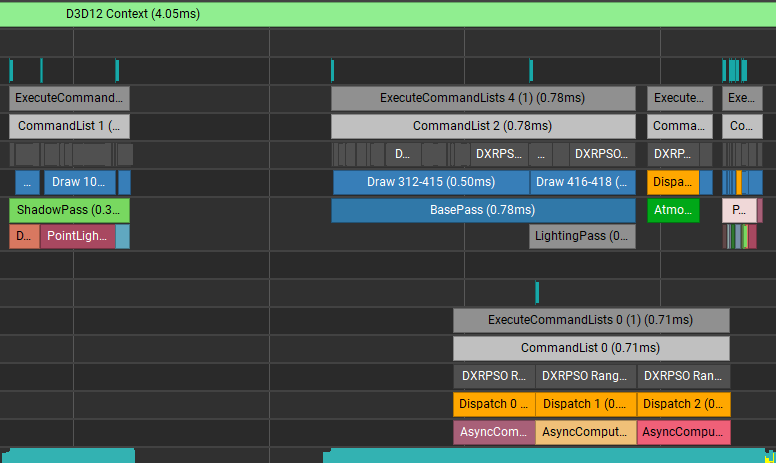
4. 레퍼런스
1. https://therealmjp.github.io/posts/breaking-down-barriers-part-1-whats-a-barrier/ (6개 시리즈 전체)
2. https://gpuopen.com/gdc-presentations/2019/gdc-2019-agtd5-breaking-down-barriers.pdf
3. https://gpuopen.com/wp-content/uploads/2017/03/GDC2017-Asynchronous-Compute-Deep-Dive.pdf
4. https://learn.microsoft.com/en-us/windows/win32/direct3d12/user-mode-heap-synchronization
5. https://youtu.be/GiKbGWI4M-Y?si=J48ZjZL0tQESimsH
6. https://codingfarm.tistory.com/579
'Graphics > Graphics' 카테고리의 다른 글
| PathTracing (1/2) (1) | 2024.03.01 |
|---|---|
| RayTraced Ambient Occlusion(RTAO) (0) | 2024.01.31 |
| Bindless Resource - DX12, Vulkan (0) | 2024.01.17 |
| DX12 Shader Visible Descriptor Heap (0) | 2023.08.05 |
| BCn Texture Compression Formats 정리 (0) | 2023.04.21 |



