
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 번역
- Graphics
- vulkan
- GPU
- scalar
- SGPR
- GPU Driven Rendering
- unrealengine
- wave
- SIMD
- DirectX12
- ShadowMap
- UE5
- rendering
- deferred
- shader
- optimization
- Shadow
- Nanite
- texture
- Study
- ue4
- RayTracing
- scattering
- atmospheric
- DX12
- Wavefront
- hzb
- VGPR
- forward
- Today
- Total
RenderLog
[번역] Perspective Shadow Maps: Care and Feeding 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 : https://developer.download.nvidia.com/books/HTML/gpugems/gpugems_ch14.html
Chapter 14. Perspective Shadow Maps: Care and Feeding
Simon Kozlov
SoftLab-NSK
14.1 Introduction
그림자의 생성은 리얼타임 3D 그래픽스 프로그램에서 항상 큰 문제입니다. 한 점이 쉐도우인지 아닌지 결정하는 것은 현대 GPU에게는 쉽지 않습니다, 특히 GPU 는 레이트레이싱 대신 폴리곤을 레스터라이즈 하는 형태로 작동하기 때문입니다.
오늘날 쉐도우는 완전히 동적입니다. 대부분은 장면의 모든 오브젝트가 쉐도우를 만들고 받습니다, 셀프 쉐도잉도 있습니다, 그리고 모든 오브젝트는 소프트 쉐도우여야만 합니다. 오직 2개의 알고리즘이 이 요구사항을 만족시킬 수 있습니다: 쉐도우 볼륨(혹은 스텐실 쉐도우) 그리고 쉐도우 매핑.
쉐도우 볼륨과 쉐도우 매핑 알고리즘간의 차이는 오브젝트 공간 vs 이미지 공간으로 볼 수 있습니다:
- 오브젝트 공간 쉐도우 알고리즘은, 쉐도우 볼륨 같은, 쉐도우 오클루더를 표현하는 폴리곤 구조를 만듬으로써 작업됩니다. 그것은 우리가 항상 정확한 픽셀 수준 정확도의 쉐도우를 가진다는 의미입니다, 그러나 하드 쉐도우. 이 방법은 폴리곤 구조를 가지지 않는 오브젝트로 다룰 수 없습니다, 알파 테스트로 변경된 지오메트리나 displacement mapped 지오메트리와 같은. 또한, 쉐도우 볼륨을 그리는 것은 많은 fill rate를 요구합니다, 그리고 그것은 밀도가 높은 장면에서 모든 오브젝트들이 쉐도우 볼륨을 사용하기 힘들게 합니다, 특히 여러개의 라이트가 있는 경우.
- 이미지 공간 쉐도우 알고리즘은 어떤 오브젝트의 수정도 잘 다룹니다 (만약 우리가 특정 오브젝트를 그린다면, 우리는 그림자를 얻을 것입니다), 그러나 그들은 앨리어싱에 의해 고통받습니다. 앨리어싱은 종종 큰 장면들에서 넓거나 혹은 전방향 라이트 소스에서 일어납니다. 그 문제는 쉐도우 매핑에 사용된 프로젝션 변환이 카메라에 가까운 텍셀이 더 커지도록 쉐도우맵 텍셀의 화면크기를 변화시킵니다. 그 결과 우리는 좋은 해상도를 얻기 위해서 거대한 쉐도우맵을 사용해야만 합니다 (4배의 스크린 해상도나 혹은 더 큰) . 여전히, 쉐도우맵은 쉐도우 볼륨보다 복잡한 장면에서 더 빠릅니다.
Perspective shadow maps (PSMs)는, SIGGRAPH 2002 에서 Stamminger and Drettakis (2002) 이 제안한, 그들은 모든 근처의 오브젝트들이 멀리 있는 오브젝트 보다 더 커지는 post-projective 공간을 사용하므로써 쉐도우맵의 앨리어싱을 제거하려 했습니다. 불행히도, 원본 알고리즘은 특정 상황에서만 잘 동작하기 때문에 사용하기 어려웠습니다.
PSM 알고리즘에서 보이는 가장 큰 문제는 이 세가지 입니다:
- 모든 Potential shadow 케스터(역주 : 화면엔 나오지 않지만 쉐도우는 보이는 물체)가 가상 카메라 프러스텀의 안쪽에 있게 하기 위해서, 라이트 소스가 카메라 뒤에 있을때 "Virtual Cameras"를 사용합니다. 이것은 좋지 않은 품질의 쉐도우를 초례합니다.
- 쉐도우 품질은 카메라 공간의 라이트 위치에 의존 합니다.
- Biasing 문제는 원본 논문에 언급되지 않았습니다. Bias 는 텍셀 영역이 nonuniform 방식으로 분배되기 때문에 PSM 쉐도우의 문제입니다. nonuniform 방식의 이미는 Bias 가 더 상수가 아니라는 의미이고 텍셀의 위치에 의존해야한다는 의미입니다.
이런 문제들은 다음 섹션에서 논의할 것입니다. 이 챕터는 디렉셔널 라이트에 중점을 둘것입니다 (왜냐하면 그들은 큰 앨리어싱 문제를 가지고 있기 때문입니다), 그러나 모든 아이디어와 알고리즘은 쉽게 다른 타입의 라이트 소스에 적용가능 합니다 (적절한 곳에서 세부사항이 추가되어집니다). 게다가, 우리는 그림에 필터링과 블러링을 사용하므로써 쉐도우맵의 퀄리티를 올리는데 사용할 트릭을 논의합니다.
보통, 이 챕터는 기술과 PSM의 효과를 증가시키는 방법에 대해서 설명합니다.
그러나, 대부분의 아이디어는 여전히 당신의 필요에 따라 조정되어져야만 합니다.
14.2 Problems with the PSM Algorithm
14.2.1 Virtual Cameras
먼저, 이 문제의 핵심을 봅시다. 보통의 projective 변환은 카메라 뒷면에 있는 오브젝트를 post-projective 공간의 무한평면의 다른 쪽으로 이동시킵니다. 그러나, 만약 라이트 소스 역시 카메라의 뒷면에 있다면, 이런 오브젝트들은 Potential 쉐도우 케스터이고 쉐도우맵에 그려져야만 합니다.
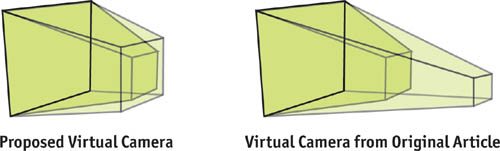
그림 14-1의 Perspective 변환은, 레이가 지나가는 점의 순서입니다. 원본 PSM 논문의 저자는 우리가 PSM을 일반적인 방법으로 사용할 수 있도록 하기 위해서, 뷰 프러스텀에 Potential 쉐도우 케스트들을 모두 넣기 위해서 카메라를 뒤로 "가상으로" 이동시키는 것을 제안했습니다, 그림 14-2에 나오는 것 처럼.
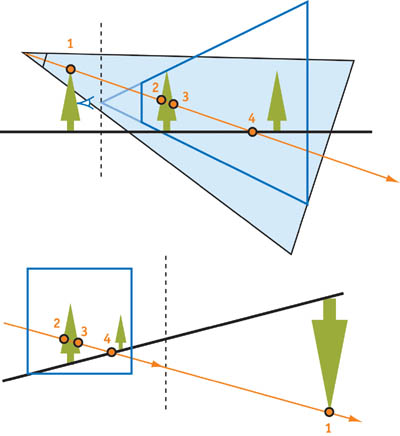
Virtual Camera 이슈들
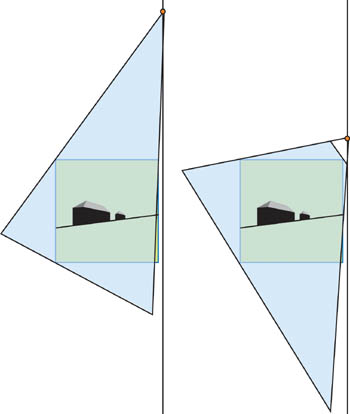
그러나 실제로는 Virtual Camera는 나쁜 품질의 쉐도우를 만듭니다. "Virtual" 이동은 ,실제 카메라에 가까이 있는 오브젝트들이 더 작아지게 하기 위해서, 효과적인 그림자맵의 해상도를 크게 감소시킵니다, 그리고 쉐도우맵에서 많은 공간이 사용되지 않을 것입니다. 게다가, 우리는 카메라 뒤에서 큰 쉐도우를 만드는 오브젝트를 위해서 아주 많이 뒤로 이동해야만 할 수 있습니다. 그림 14-3은 약간의 이동에 얼마나 품질이 크게 변하는지 보여줍니다.

또 다른 문제는 실제 "뒤로 이동하는 거리"를 최소화 하는 것입니다, 그것은 이미지 품질을 최대화 합니다. 이것은 우리가 장면을 분석하고, Potential 쉐도우 케스터를 찾기, 기타 등등을 요구합니다. 물론, 우리는 바운드 볼륨을 사용할 수 있습니다, 장면의 계층 구조, 그리고 비슷한 기술들, 그러나 그들은 CPU에 큰 부담을 줄것입니다. 게다가, 우리는 항상 오브젝트가 Potential 쉐도우 케스트가 되는 동안 급격한 쉐도우 품질 변화를 겪을 것입니다. 이 경우, 뒤로 이동하는 거리는 순간적으로 변화합니다, 쉐도우 품질 또한 급겹하게 변화하도록 만듭니다.
Virtual Camera 이슈들의 해결책
우리는 Virtual camera 문제의 해결책 하나를 제안합니다: 라이트 매트릭스를 위한 특별한 프로젝션 변환을 사용하는 것. 실제로 post-projective 공간은 보통의 월드 공간에서는 불가능한 몇몇 프로젝션 트릭을 가능케 합니다. "무한 보다 더 먼곳"을 볼 수 있는 특별한 프로젝션 매트릭스를 만들 수 있는 것으로 드러났습니다.
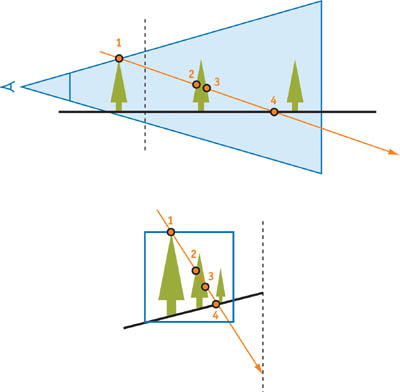
원본 (nonvirtual) 카메라와 Directional "Inverse" 라이트 소스 그리고 카메라 뒤에 있는 오브젝트로 구성된 post-projective 공간을 봅시다, 그림 14-4.
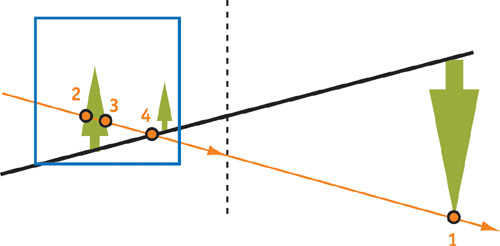
이 해결책의 결점은 라이트 소스로 부터 나와야만 하지만 그렇지 않은 반직선이 점 1에서 부터 음의 무한으로 가는 것입니다, 그리고 나서 양의 무한을 지나고 점 2, 3, 4를 거치면서 라이트 소스로 돌아옵니다.
다행히도, 이런 "불가능한" 반직선과 맞는 프로젝션 매트릭스가 있습니다, 그것은 Near 평면이 음수, Far 평면이 양수입니다. 그림 14-5를 보세요.
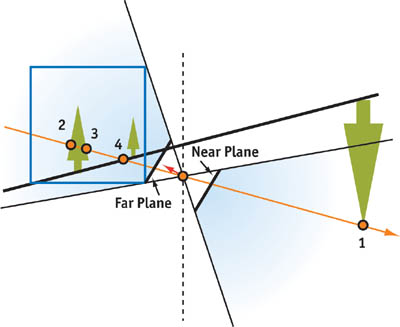
가장 간단한 경우,
a는 전체 unit cube에 딱 맞게 충분히 작습니다. 그 다음 우리는 일반 projection matrix로 inverse projection을 만듭니다, 여기 보는 것 처럼, 그리고 이 매트릭스는 row-major 입니다:
변환된 Z 좌표의 결과에대한 공식은, 쉐도우맵에 들어갑니다:
Z psm (-a) = 0, 그리고 만약 우리가 z 값을 음의 무한으로 계속 감소시킨다면, Z psm 은 ½이 되는 경향이 있습니다. Z psm = ½ 과 동일한 값은 양의 무한에 대응됩니다, 그리고 양의 무한대에서 Far 평면 까지 이동는 것은 Far 평면에서 Z psm 을 1로 증가시킵니다. 이것이 레이가 순서대에 맞게 모든 점을 지나가는 이유이고 "virtual 이동"을 post-projective space에 대해서 만들 필요가 없는 이유입니다.
이 트릭은 post-projective 공간에서만 작동합니다 왜냐하면 보통 무한의 평면 뒤의 모든 점들은 w < 0을 가집니다, 그래서 레스터라이즈화 되지 않습니다. 그러나 라이트 카메라에 의한 또 다른 projection 변환은, 이런 점들은 카메라의 뒤에 위치합니다, 그래서 w 좌표는 반전되며 다시 positive가 됩니다.
이 inverse projection matrix를 사용하므로써, 우리는 virtual camera를 사용하지 않아도 됩니다. 그 결과 우리는 더 나은 쉐도우 퀄리티를 CPU 의 장면 분석과 관련된 artifacts 없이 얻을 수 있습니다.
Inverse projection matrix의 유일한 결점은 우리는 더 나은 쉐도우맵 depth 값 정밀도가 필요한 것입니다, 우리는 큰 z 값 범위를 사용하기 때문입니다. 그러나, 적절한 경우 24-bit 고정 소수점 depth 값은 충분합니다.
Virtual camera는 여전히 유용할 수 있습니다, 왜냐하면 쉐도우 품질이 카메라의 Near 평면의 위치에 종속되기 때문입니다. post-perspective z 공식은 이것 입니다:
우리가 보는 것처럼, Q를 1에 아주 가깝습니다 그리고 Zn이 Zf 보다 훨씬 작다면 크게 변경되지 않습니다, 이 것은 일반적인 경우입니다. 이것이 Q값에 영향을 미치기 위해서 near 과 far 평면이 크게 변해야만 하는 이유 입니다, 그리고 보통은 불가능합니다. 동시에, near 평면 값은 크게 post-projective 공간에 영향을 미칩니다. 예를들어, Zn = 1 meter(m) 경우, Near 평면 이후 월드 공간에서의 첫 1 meter는 post-perspective 공간에서 unit cube 의 절반을 차지합니다. 이런 측면에서, 만약 우리가 Zn 을 2m 으로 변경하면, 우리는 효과적으로 z 값의 해상도를 2배로 할 수 있고 쉐도우 품질을 증가시킬 수 있습니다. 이것은 우리가 Zn 값을 어쨌든 최대화 해야만 한다는 의미입니다.
완벽한 방법은, 원본 PSM 글에 제시된, depth buffer를 다시 읽고, 각 픽셀을 스캔하여, 가능한 최대 Zn을 매 프레임 찾는 것입니다. 불행히도, 이 방법은 아주 비쌉니다: 이것은 많은 양의 비디오 메모리를 다시 읽어야 하고, 추가적인 CPU/GPU stall을 유발, swizzled 와 hierarchical depth buffer와 잘 작동하지 않습니다. 그래서 우리는 PSM 렌더링의 near 평면 계산에 맞는 다른 방법 (아마 덜 정확한) 을 찾아야만 합니다.
PSM 렌더링을 위한 적절한 near 평면 값을 찾기위한 다른 방법은 CPU 장면 분석의 여러가지 방법이 포함될 수 있습니다:
- 대략의 바운드 볼륨 계산 기반 방법 (이후에 "The Light Camera" 에서 간단히 설명됨)
- 가장 가까운 오브젝트와의 거리를 평가하기 위한 충돌 감시 시스템
- 로우 폴리곤의 LOD(Low-polygon-count level-of-detail)로 추가적인 소프트웨어 장면 렌더링, 오클루젼 컬링에 유용할 수 있습니다.
- 특정 어플리케이션을 위한 장면의 구조의 특정 기능을 기반한 정교한 분석. 예를들어, 고정 카메라 경로를 사용하는 시나리오를 다룰때, 당신은 near 평면을 매 프레임 미리 계산해둘 수 있습니다.
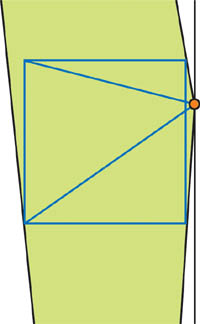
이러한 방법들은 실제 Near 평면 값을 증가시키길 시도합니다. 그러나 우리는 이 값들 또한 "가상으로" 증가시킬 수 있습니다. 이 아이디어는 이전 virtual camera와 같습니다, 그러나 하나 다른점이 있습니다. 카메라를 뒤로 움직일 때, 원본 Near 평면 Quad와 virtual camera가 같은 plane에 남아있도록 우리는 Near 평면 값을 증가시킵니다. 그림 14-6을 보세요.
우리가 Virtual camera를 뒤로 밀때, 우리는 z 값의 해상도를 향상시킵니다. 그러나, 이것은 x와 y 값의 분포를 가까운 오브젝트에 대해 더 좋지 않게 합니다, 그래서 카메라로 부터 near 그리고 far 인 쉐도우의 품질이 유지됩니다.
Post-perspective 공간에서 아주 불규칙한 z 값 분포와 near 평면 값의 큰 영향 때문에, 이 균형은 "virtual" 뒤로 밀기 없이 얻어질 수 없을 것입니다. 보통의 카메라와 가까이 있는 것은 좋아 보이지만 멀리 있는 오브젝트는 그렇지 않은 문제는 쉐도우맵의 텍셀 분포가 균형되지 않은 결과입니다.
14.2.2 The Light Camera
또 다른 PSM의 문제는 쉐도우 품질이 라이트와 카메라의 위치의 관계에 의존하는 것입니다. 수직 방향의 라이트에서, 앨리어싱 문제는 완전히 제거됩니다, 그러나 라이트가 카메라를 향하고 정면에 가까운 경우, 심각한 쉐도우맵 앨리어싱이 있습니다.
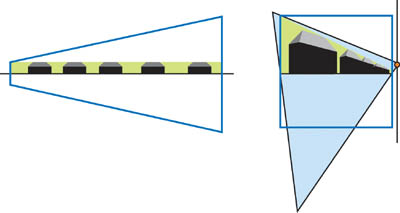
우리는 한개의 쉐도우맵 텍스쳐에 전체 unit cube를 두려고 합니다, 그래서 우리는 라이트 시야를 전체 큐뷰에 맞게 필요한 만큼 크게 합니다. 이것은 Near 평면과 가까운 오브젝트들이 충분한 텍스쳐 샘플을 받지 못할 것이라는 의미입니다. 그림 14-7을 보세요.
라이트 소스가 unit cube에 가까울 수록, 더 좋지 않은 품질입니다. 우리가 알듯이,
큰 실외 장면은 Zn=1 그리고 Zf=4000, Q=1.0002, 이것은 라이트소스가 극단적으로 unit cube와 가깝다는 의미입니다. Zf/Zn의 상관관계는 보통 50보다 큽니다. 그리고 그것은 Q = 1.02 에 대응되고 문제를 만들기 충분히 가깝습니다.
우리는 항상 전체 unit cube를 한개의 쉐도우맵 텍스쳐에 맞춰야하는 문제를 가질 것입니다. 문제의 한 부분을 해결하는 2개의 해결책: Unit cube 클리핑은 unit cube의 필요한 부분에서만 라이트 카메라가 대상으로 합니다, 그리고 cube map 접근을 여러 텍스쳐에 depth 정보를 저장하기 위해 사용합니다.
Unit Cube Clipping
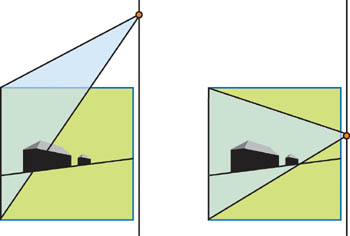
이 최적화는 실제 오브젝트에만 쉐도우맵이 필요하다는 사실에 의존합니다, 그리고 오브젝트들에 의한 Volume은 보통 전체 뷰 프러스텀 Volume 보다 더 작습니다 (특히 far 평면에 가까움). 그것이 우리가 라이트 카메라가 실제 오브젝만을 담도록(전체 unit cube가 아닌) 조정하는 이유입니다, 우리는 더 나은 품질을 얻을 것입니다. 물론, 우리는 바운드 볼륨과 같은 간략화된 장면 구조를 사용하여 카메라를 조정해야만 합니니다.
Cube 클리핑은 원본 PSM 글에서 언급되었습니다, 그러나 그것은 Virtual camera를 만들기 위해 View frustum과 frustum 바깥에 있는 potential 쉐도우 케스터를 포함한.. 장면에 모든 오브젝트를 고려합니다. 우리는 virtual camera가 더이상 필요없기 때문에, 우리는 쉐도우 리시버에서의 라이트 카메라에만 중점을 둘 수 있습니다, 그리고 그것은 더 효과적입니다. 그림 14-8을 보세요. 여전히, 우리는 쉐도우맵에서 모든 쉐도우 케스터들을 얻기 위해 post-projective 공간의 라이트 카메라를 위해 Near과 Far clip-plane 값을 선택해야만 합니다. 그러나 그것은 쉐도우의 품질에 영향을 주지 않습니다. 왜냐하면 그것은 텍셀 영역의 분포를 변화시키지 않기 때문입니다.
바운드 볼륨의 먼 부분이 post-perspective 공간에서 크게 수축하기 때문에, 라이트 카메라의 시야 영역은 더 커지지 않습니다, 장면의 나머지 부분이 라이트 소스에 가까이 있어도 마찬가지입니다.
실제로는, 우리는 충분한 품질을 유지하기 위해서 대략의 바운드 볼륨을 사용할 수 있습니다 - 우리가 흥미가 있는 장면의 일부를 가리킬 필요가 있습니다. 실외 장면에서는, 풍경에 있는 오브젝트의 근사된 높이입니다; 실내 장면에서는, 현재 방, 기타 등등의 바운드 볼륨입니다.
우리는 장면을 묘사하는 대략적인 바운드 볼륨을 만든 후 장면에서 쉐도우 리시버에 중점을 둔 카메라를 계산하는 알고리즘을 공식화 하고싶습니다. 실제로, 라이트 카메라에 위치, 방향, Up Vector 그리고 Projection 파라메터들이 주어집니다, 대부분 미리 정의되어 있습니다:
- 우리는 위치를 바꿀 수 없습니다 : post-projective 공간의 라이트 위치이며 다른것은 없습니다.
- 실제로, up vetor는 품질을 크게 변화시키지 않습니다, 그래서 우리는 적절한 것을 선택할 수 있습니다.
- Projection 파라메터들은 전적으로 view matrix에 의해 정의 됩니다.
몇몇의 흥미로운 점은 바운드 볼륨으로 라이트 카메라의 방향을 선택하는 것입니다. 제안된 알고리즘은 이것입니다:
- Constructive solid geometry 연산의 Vertex 목록 계산, 여기서 Bi 는 i 번째 바운드 볼륨, F 는 현재 프레임에서 볼 수 있는 모든 쉐도우 케스터 바운드 볼륨을 위한 프러스텀, 그리고 모든 이런 연산들은 View 카메라 공간에서 수행됩니다. 그리고나서 모든 정점을 post-projective 공간으로 변환합니다. 이 단계 후에, 우리는 라이트 카메라가 "봐야만하는" 모든 점들을 가집니다. (그런데, 우리는 좋은 near 평면 값을 이 점들로 부터 찾아야 합니다. 왜냐하면 depth 버퍼로 부터 값을 읽어드리는 것은 좋지 않은 해결책이기 때문입니다.)
- 라이트 카메라를 찾기. 우리가 이미 알듯이, 이것은 최선의 라이트 카메라 방향을 찾는 것을 의미합니다, 왜냐하면 모든 다른 파라메터들은 주어진 방향에 대해 쉽게 계산되어질 수 있습니다. 우리는 최적의 방향을 구하는 것을 라이트 소스를 중심으로 하고 모든 리스트 안의 점을 포함하는 최소의 Cone 축으로 부터 근사하는 것을 제안합니다. 이 알고리즘은 최적의 콘을 점들의 집합에서 찾으며 선형시간내에 처리합니다. 그리고 이것은 가장 작은 바운드 Sphere를 모든 점들의 집합에 대해서 선형시간내에 찾는 알고리즘과 유사합니다. (Gartner 1999)
이 방법에서, 우리는 최적의 라이트 카메라를 바운드볼륨의 수에 따라서 선형시간내에 찾을 수 있습니다, 그리고 그것은 그렇게 크지 않습니다. 왜냐하면 우리는 대략의 장면 구조 정보만 필요하기 때문입니다.
이 알고리즘은 큰 실외 장면에서 direct 라이트에서 효율적입니다. 쉐도우 품질은 라이트 각도에 거의 무관합니다. 그리고 라이트의 카메라를 향하고 있으면 살짝 감소합니다. 그림 14-9에서 uni cube 클리핑과 사용하지 않은 경우의 차이를 보여줍니다.

Using Cube Maps
Cube 클리핑이 몇몇 상황에서 효과적일지라도, 다른 때에 쓰기는 힘듭니다. 예를들어, 우리는 unit cube를 밀도 높게 채워 사용하거나 (보통), 혹은 우리는 전혀 바운드 볼륨을 사용하지 않을 수도 있습니다. 추가로, cube 클리핑은 포인트 라이트와 함께 사용할 수 없습니다.
더 일반적인 방법은 cube map texture를 쉐도우 매핑에 사용하는 것이빈다. 대부분의 라이트 소스는 post-perspective 공간에서 포인트 라이트가 됩니다, 그래서 cube map을 포인트 라이트 소스와 함께 쉐도우매핑에 사용하는 것은 자연스럽습니다. 그러나 post-perspective 공간에서, 상황이 약간 바뀝니다. 그리고 우리는 cube map을 다르게 사용해야만 합니다. 왜냐하면 우리는 unit cube 에 대한 정보만 저장할 필요가 있기 때문입니다.
제안된 해결책은 라이트에 대해서 unit cube의 뒷면을 cube map 면의 텍스쳐로 사용하는 것입니다.
Post-projective 공간에서 Direct 라이트 소스를 위해, cube map 은 그림 14-10과 같습니다.
사용된 cube map을 면들은 라이트의 위치에 따라 다릅니다(3~5개의 범위). 우리는 라이트가 나머지 장면에 가깝고 카메라 방향을 향한다면 최대 면의 숫자를 사용합니다, 그래서 추가 텍스쳐 리소스가 필요합니다. unit cube의 바깥에 있는 다른 타입의 라이트 소스에 대해서, 그림은 비슷할 겁니다.
Unit cube의 내부에 있는 포인트 라이트의 경우, 우리는 6개의 cube map 을 사용해야만 합니다, 그러나 그들은 여전히 unit cube 면들에 집중합니다. 그림 14-11을 보세요.

우리가 "중심이 변경된 cube map" 형태를 구성했다고 할 수 있습니다. 그리고 그것은 일반 cube map 과 유사합니다, 그러나 상수 vector가 그것의 텍스쳐 좌표에 더해집니다. 다른말로 하면, cube map을 위한 텍스쳐 좌표는 post-projective 공간에서 라이트 소스 포지션에 의해 이동되어진 Vertex 위치입니다.
Texture coordinates = vertex position - light position
Unit cube 면을 cube map으로 선택함으로써, 우리는 texture 영역의 비율을 스크린 크기로 분배하고 쉐도우 품질이 라이트 카메라 위치에 의존되지 않도록 보장합니다. 실제로, post-projective 공간의 텍셀 사이즈는 범위는 보장된 범위내에 있습니다, 그래서 그것의 화면에서의 투영은 그것이 투영된 평면에만 의존합니다. 이 프로젝션은 텍셀을 많이 늘리지 않습니다, 그래서 화면에서의 텍셀 사이즈 역시 보장된 범위 내에 있습니다. Vertex와 Pixel 쉐이더가 쉐도우맵을 렌더링할 때 비교적 짧기 때문에, 중요한 점은 순수하게 백버퍼와 뎁스쉐도우맵 버퍼를 채우는 속도입니다. 그래서 하나의 쉐도우맵과 총 크기가 동일한 cube map의 그리는 것은 거의 차이가 없습니다 (좋은 오클루젼 컬링을 사용하더라도)
Cube map 접근은 단일 텍스쳐와 동일한 총 텍스쳐의 크기로 더 나은 품질을 가잡니다. 다른 점은 렌더타겟의 전환 비용과 cube map 텍스쳐 좌표의 추가적인 명령을 계산을 vertex와 pixel 쉐이더에서 하는 것입니다.
텍스쳐 좌표를 어떻게 계산하는지 봅시다. 먼저 그림 14-12를 고려해봅시다. 파란색 정사각형이 우리의 unit cube 입니다, P는 라이트 소스의 점입니다, 그리고 V는 우리가 생성하고 있는 텍스쳐 좌표인 점입니다. 우리는 6 cube map 면을 분리된 패스에서 쉐도우맵에 그립니다; 각 패스의 Near 평면은 초록색으로 보입니다. 그들은 또다른 작은 cube를 구성합니다, Z1 = Zn/Zf 는 모든 패스에서 상수입니다.
이제 우리는 점 V에 대해서 텍셀 좌표와 깊이 값을 계산해야만 합니다. 이것은 우리가 이 점을 (V-P) 방향으로 cube와 교차할때까지 이동시켜야만 한다는 의미입니다. d1, d2, d3, d4, d5 그리고 d6을 (14-12의 면의 숫자) P로 부터 각 cube map 면의 거리로 고려해봅시다.
우리가 찾고 있는 Cube 위의 점은(그것은 또한 cube map 텍스쳐 좌표):
텍스쳐의 값을 특정 값의 projective 변환의 결과에 대해 비교합니다. 왜냐하면 우리는 이미 그것을 그와 대응하는 d 값으로 나누었기 때문입니다, 그래서 효과적으로 Zf = 1 그리고 Zn = Z1, 우리가 해야하는 모든 것은 projective 변환에 적용되었습니다. 섹션 14.2.1의 Inverse camera projection 이 경우 주목할 점은, Zn=-Z1, Zf=Z1 입니다.
(모든 이런 계산은 OpenGL 좌표계로 만들어짐, Unit cube는 실제로 unit cube. Direct3D 에서는, Unit cube 가 half size, 왜냐하면 z 좌표가 [0..1] 범위이기 때문)
리스트 14-1 은 어떻게 쉐이더 코드가 보일지에 대한 예제입니다.
Example 14-1. Shader Code for Computing Cube Map Texture Coordinates // c[d1] = 1/d1, 1/d2, 1/d3, 0 // c[d2] = -1/d4, -1/d5, -1/d6, 0 // c[z] = Q, -Q * Zn, 0, 0 // c[P] = P // r[V] = V // cbmcoord - output cube map texture coordinates // depth - depth to compare with shadow map values //Per-vertex level sub r[VP], r[V], c[P] mul r1, r[VP], c[d1] mul r2, r[VP], c[d2] //Per-pixel level max r3, r1, r2 max r3.x, r3.x, r3.y max r3.x, r3.x, r3.z rcp r3.w, r3.x mad cbmcoord, r[VP], r3.w, c[P] rcp r3.x, r3.w mad depth, r3.x, c[z].x, c[z].y
Depth 텍스쳐는 cube map이 될 수 없기 때문에, 우리는 컬러 텍스쳐를 사용 할 수 있습니다, 패킹된 depth 값을 컬러 채널에 넣습니다. 이것을 하는 많은 방법이 있습니다. 그리고 많은 구현에 따른 트릭이 있습니다, 그러나 그들의 설명은 이 챕터의 범위를 벗어납니다.
또 다른 가능성은 멀티텍스처링을 사용한 cube map 접근을 에뮬레이팅 하는것입니다. 그리고 그것은 모든 cube map 면이 독립된 텍스쳐가 됩니다 (이 경우 depth 텍스쳐가 좋습니다). 우리는 여러장의 텍스쳐 좌표 세트를 Vertex 쉐이더 그리고 픽셀 쉐이더의 쉐도우 결과와 곱하여 구성합니다. 까다로운 부분은 장면의 오브젝트에 대해서 이러한 텍스쳐들을 관리하는 것입니다, 왜냐하면 모든 오브젝트는 거의 6개의 면을 필요로 하지 않기 때문입니다.
14.2.3 Biasing
앞서 언급했듯이, 보통 uniform 쉐도우맵에 사용되어지는 상수 bias는 PSM에 사용될 수 없습니다 왜냐하면 z 값과 텍셀 영역의 분포가 장면의 조명 위치와 점에 따라서 크게 달라지기 때문입니다.
만약 depth 텍스쳐를 사용할 계획이라면, z slop-scaled bias를 biasing을 위해서 시도해보세요. 이것은 종종 artifacts를 고치기에 충분합니다, 특히 아주 거리가 먼 오브젝트들이 카메라에 있지 않는 경우. 그러나 몇몇 카드는 depth 텍스쳐를 지원하지 않습니다 (DirectX 에서, depth 텍스쳐는 오직 NVIDA 카드에서만 지원합니다), 그래서 depth 텍스쳐는 cube map이 될 수 없습니다. 이러한 경우, 당신은 다른 것이 필요합니다, Bias 계싼에 더 일반적인 알고리즘. 또 다른 어려움은 z slope-scaled bias는 모방하고 변형하기 어려운 것입니다. 왜냐하면 그것은 추가 데이터를 - 현재 삼각형의 Vertex 좌표와 같은 - 픽셀 쉐이더로 전달하는 것을 요구하기 때문입니다, 몇가지 계싼을 더하여, 이것은 전혀 확실한 것이 아닙니다.
어쨌든, 왜 우리가 상수 bias를 더 사용할 수 없는지 봅시다. 2개의 경우를 고려합니다: 라이트 소스는 unit cube에 가깝습니다, 그리고 라이트 소스는 unit cube에서 멀리 떨어져있습니다. 그림 14-13을 보세요.
문제는 쉐도우맵으로의 z 값의 분포를 결정하는 Zf/Zn의 상관관계가 2 경우 많이 다르다는 것입니다. 그래서 상수 bias는 총 실제 월드와 post-projective 공간에서의 다르다는 것을 의미합니다: 상수 bias는 첫번째 조명 위치로 조정된 것은 두번째 조명에게 맞지 않을 것입니다, 그리고 반대도 마찬가집니다.
그동안에, Zf/Zn 는, 왜냐하면 라이트 소스는 unit cube에 가까울 수도 있고 멀 수도있기 때문입니다(심지어 무한에서도), 라이트의 상대 위치와 월드공간에서의 카메라에 따라서 많이 변합니다.
심지어 라이트 소스 위치가 고정된 경우도, 떄때로 우리는 적절한 상수 bias를 찾을 수 없습니다. Bias는 점의 위치에 종속되어 있습니다-왜냐하면 projective 변환이 가까운 오브젝트들을 크게 만들고 먼 오브젝트를 줄어들게 만들기 때문입니다- 그래서 bias는 카메라와 가까운 경우 작고 멀리 있는 오브젝트에 커야 합니다. 그림 14-14는 상수 bias를 사용한 경우 보통의 artifacts를 보여줍니다.

요약하면, 제안된 해결책은 월드공간에서 bias를 사용하는 것입니다(그리고 double projection matrix의 결과를 분석하지 않음) 그리고나서 post-projective 공간에서 월드공간으로 변환합니다. 계싼된 값은 double projection에 따라 다릅니다, 그리고 그것은 특정 라이트 그리고 카메라 위치에 대해 보정됩니다. 이러한 연산은 버택스 쉐이더에서 쉽게 완료됩니다. 더 나아가서, 월드 공간의 bias 값은 nonuniform 텍셀 영역의 분포에 의해 발생하는 artifacts를 다루기 위해서 월드공간에서의 텍셀 크기로 크기가 조정되어야 합니다.
Pbiased = (P orig + L(a + bLtexel ))M,
여기서 Porig 는 원본 포인트의 위치, L은 월드 공간에서의 라이트 벡터 방향, Ltexel은 월드공간에서의 텍셀 크기, M은 최종 쉐도우맵 매트릭스, 그리고 a와 b는 bias 계수입니다.
월드 공간에서의 텍셀 크기는 간단하 매트릭스 계산으로 근사될 수 있습니다. 먼저, 점을 쉐도우맵 공간으로 변환합니다, 그리고나서 이 점을 텍셀을 크기에의해 depth 값을 변화 없이 이동시킵니다. 다음으로, 월드 공간으로 다시 변환합니다 그리고 이 점과 원본점 사이의 거리를 제곱합니다. 이것으로 Ltexel이 주어집니다:
그리고 Sx와 Sy는 쉐도우맵 해상도입니다.
명백히, 우리는 모든 변환을 수행하는(좌표의 곱셈을 제외한) 한개의 매트릭스를 만들 수 있습니다:
여기서 M'는 변환, 이동, 다시 변환 그리고 빼기를 포함합니다.
이것은 다소 경험적인 해결책으로 보이지만 당신의 특정 요구에 따라 조정될 수 있습니다. 그림 14-14를 보세요.

이 계산을 수행하는 버택스 쉐이더 코드는 아마 리스트 14-2와 같을 것입니다.
Example 14-2. Calculating Bias in a Vertex Shader def c0, a, b, 0 ,0 // Calculating Ltexel dp4 r1.x, v0, c[LtexelMatrix_0] dp4 r1.y, v0, c[LtexelMatrix_1] dp4 r1.z, v0, c[LtexelMatrix_2] dp4 r1.w, v0, c[LtexelMatrix_3] // Transforming homogeneous coordinates // (in fact, we often can skip this step) rcp r1.w, r1.w mul r1.xy, r1.w, r1.xy // Now r1.x is an Ltexel mad r1.x, r1.x, c0.x, c0.y dp3 r1.x, r1, r1 // Move vertex in world space mad r1, v0, c[Lightdir], r1.x // Transform vertex into post-projective space // (we need z and w only) dp4 r[out].z, r1, c[M_2] dp4 r[out].w, r1, c[M_3]
r[out] 레지스터는 bias의 결과값을 가집니다: depth 값, 그리고 그에 대응하는 w는 삼각형 통해서 보간되어집니다. 주목할 점은 이 보간은 텍스쳐 좌표(x, y 그리고 대응하는 w)의 보간으로 부터 분리되어져야만 합니다, 이들의 w 좌표가 다르기 때문입니다. 이 bias된 값은 쉐도우맵 값과 비교할 때나 실제 쉐도우맵 렌더링에서 사용되어집니다 (쉐도우맵은 bias 값을 가지고 있습니다).
14.3 Tricks for Better Shadow Maps
쉐도우 볼륨에 비해 쉐도우 매핑이 가진 장점은 "shadowed" 그리고 "nonshadowed" 샘플 간의 컬러 변화를 만들 수 있다는 것입니다, 그래서 소프트 쉐도우 처럼 보이게 할 수 있습니다. 이런 쉐도우의 "부드러움"은 오클루더의 거리, 라이트 소스 크기, 기타 등등에 따라 다르지 않습니다, 그러나 여전히 월드 공간에서 작동합니다. 스텔실 쉐도우를 흐리게 하는 것은, 반면에, 더 어렵습니다, 비록 Assarsson et al. (2003) 이 큰 발전을 만들었지만요.
이 섹션은 필더링 방법과 쉐도우맵을 블러링하는 방법을 상수 범위 블러링 범위지만 여전히 보기 좋은 가짜의 부드러운 쉐도우를 만들기 위해서 다룹니다.
14.3.1 Filtering
쉐도우맵 필터링 방법의 대부분은 Percentage-closer filetering(PCF) 원리에 기반합니다. 방법들 중 오직 다른 것은 어떻게 하드웨어가 그것을 사용하게 해주는 것이냐 입니다. NVIDA depth 텍스쳐는 depth 값 비교를 한 후에 PCF 를 수행합니다; 다른 하드웨어에서는, 우리는 몇몇 샘플을 nearest 텍셀로 샘플링 한 다음에 그들의 결과를 평균을 계산해야 합니다(for true PCF). 보통은, depth 텍스쳐 필터링은 수동으로 4개의 샘플로 처리하는 PCF 기술보다 훨씬 더 효율적입니다.(PCF는 비슷한 품질을 만들기 위해서 8개의 샘플이 필요합니다.) 게다가, depth 텍스쳐 필터링을 사용하는 것은 PCF에서 금지되지 않았습니다, 그래서 우리는 쉐도우의 품질을 더 향상 시키기 위해서 여러개의 필터된 샘플을 얻을 수 있습니다.
PCF를 PSM과 사용하는 것은 표준 쉐도우맵을 사용하는 것과 다르지 않습니다: 이웃 텍셀으로 부터의 샘플들은 필터링에 사용되어집니다. GPU에서, 이것은 texture 좌표를 각각의 방향으로 한텍셀 이동시키면서 수행될 수 있습니다. 더 자세한 PCF의 논의는, 챕터 11, "Shadow Map Antialiasing."을 보세요.
PCF를 위한 4개의 샘플들을 사용한 pseudocode 코드는 리스트 14-3과 14-4와 같습니다.
이 트릭은 쉐도우의 품질을 향상시킵니다, 그러나 그들은 심각한 앨리어싱 문제를 숨기진 않습니다. 예를들어, 만약 많은 스크린 픽셀이 1개의 쉐도우맵 텍셀에 매핑되낟면, 큰 계단식(stair-stepping) artifacts가 보일 것입니다, 비록 그들이 다소 흐리더라도. 그림 14-16은 앨리어스된 쉐도우를 필터링 없이 보여줍니다, 그리고 그림 14-17은 어떻게 PCF가 쉐도우 품질을 향상시키는지와 완전히 앨리어싱 artifacts를 없앨 수 없는지를 보여줍니다.


Example 14-3. Vertex Shader Pseudocode for PCF def c0, sample1x, sample1Y, 0, 0 def c1, sample2x, sample2Y, 0, 0 def c2, sample3x, sample3Y, 0, 0 def c3, sample4x, sample4Y, 0, 0 // The simplest case: // def c0, 1 / shadowmapsizeX, 1 / shadowmapsizeY, 0, 0 // def c1, -1 / shadowmapsizeX, -1 / shadowmapsizeY, 0, 0 // def c2, -1 / shadowmapsizeX, 1/ shadowmapsizeY, 0, 0 // def c3, 1 / shadowmapsizeX, -1 / shadowmapsizeY, 0, 0 . . . // Point - vertex position in light space mad oT0, point.w, c0, point mad oT1, point.w, c1, point mad oT2, point.w, c2, point mad oT3, point.w, c3, point Example 14-4. Pixel Shader Pseudocode for PCF def c0, 0.25, 0.25, 0.25, 0.25 tex t0 tex t1 tex t2 tex t3 . . . // After depth comparison mul r0, t0, c0 mad r0, t1, c0, r0 mad r0, t2, c0, r0 mad r0, t3, c0, r0
14.3.2 Blurring
우리가 projective shadow에서 알수 있듯이, 최고의 블러링 결과는 종종 픽셀 쉐이더 블러에서 더 작은 해상도의 텍스쳐로 렌더링 되면서 얻어집니다, 그리고나서 이 결과 텍스쳐를 다시 블러 픽셀 쉐이더에 여러번 채웁니다 (핑퐁 렌더링으로 알려져있음). 쉐도우 매핑과 projective 쉐도우는 비슷한 기술입니다, 왜 이 방법을 사용할 수 없을까요? 답은 : 쉐도우맵은 블랙 그리고 화이트 색상의 그림이 아니기 때문입니다; 그것은 depth 값의 모음입니다, 그래서 "depth map을 흐리게 하는 것"은 말이 되지 않습니다.
실제로, 쉐도우맵의 컬러부분을 그리기(이것은 거의 무료임)를 몇몇의 오브젝들의 projective 텍스쳐로써 사용하자는 제안이 있습니다. 예를들어, 우리가 실외 랜드스케이프 장면을 가지고 있고 지면 쉐도우는 대부분을 눈에 띄기 때문에 우리가 지면에 대한 높은 품질의 블러링된 쉐도우맵을 가지있다고 가정합니다.
- Depth 쉐도우맵을 렌더링하기 전에, 컬러 버퍼를 1로 지웁니다 렌더링 하는 동안, 랜드스케이프를 제외한 모든 오브젝트에 대해 0을 컬러 버퍼에 씁니다; 랜드스케이프에는 1을 컬러에 그립니다. 전체 쉐도우맵을 그린후에, 우리는 랜드스케이프에 쉐도우가 없는 경우 1을 그리고 쉐도우가 있는 경우 0을 얻습니다. 그림 14-18을 보세요.

그림 14-18 작은 테스트 장면에서 원본 컬러 파트 - 그림(그림 14-18)을 여러 패스의 간단한 블러링 픽셀 쉐이더를 사용하여 더욱 흐리게 합니다. 예를들어, 간단한 2개의 패스의 가우시안 블러는 좋은 결과를 줍니다. (당신은 아마 블러링 반경을 멀리 떨어진 오브젝트에 대해서 조정하고 싶을 것입니다.) 이 단계 이후, 우리는 높은 품질의 블러링된 텍스쳐를 얻습니다, 그림 14-19에 보여집니다.

그림 14-19 작은 테스트 장면의 블러링 된 컬러 파트 - 장면이 쉐도우로 렌더링되는 동안, 랜드스케이프는 쉐도우맵 대신 블러링된 텍스쳐로 그려집니다, 그리고 모든 다른 오브젝트들은 쉐도우맵의 depth 부분으로 렌더링 됩니다. 그림 14-20을 보세요.

그림 14-20 블러링을 적용한 실제 장면
품질의 차이는 인상적입니다.
물론, 우리는 이 방법을 랜드스케이프 뿐만아니라, 셀프 세도잉이 필요없는 특정 오브젝트(계단, 벽, 지면의 평면 기타 등등)에도 사용할 수 있습니다. 다행히도, 이러한 영역의 쉐도우는 특별히 눈에 띄고 앨리어싱 문제도 가장 분명합니다. 왜냐하면 우리는 여러개의 컬러 채널을 갖고 있기 때문입니다, 우리는 한번에 여러개의 오브젝트의 쉐도우를 블러링 할 수 있습니다:
- depth 텍스쳐를 사용하는 것, 컬러 버퍼는 완전히 무료, 그래서 우리는 4개의 채널을 4개의 오브젝트에 사용할 수 있음.
- 부동 소수점 텍스쳐에서, 한 채널은 depth 정보를 저장하고, 우리는 3개의 채널을 블러링을 위해 가집니다.
- 고정 소수점 텍스쳐에서, depth는 보통 red와 green 채널에 저장되어집니다, 우리는 2개의 채널을 가집니다.
이것은 우리가 좋은 블러링된 쉐도우를 지면이나 계단, 벽, 기타등등에 사용하면서 다른 오브젝트들의(적절히 셀프쉐도잉이 되는) 모든 다른 쉐도우(PCF로 블러링된)를 사용하는 방법입니다.
14.4 Results
그림 14-21, 14-22, 14-23 그리고 14-24의 스크린샷은 NVIDIA GeForece4 Ti 4600에서 1600x1200 스크린 해상도와 100,000에서 500,000 개의 보여지는 폴리곤들로 캡쳐되었습니다. 모든 오브젝들은 쉐도우를 리얼타임 프레임 속도로(30보다 더 높은) 케스트 그리고 리시브 합니다.




14.5 References
Assarsson, U., M. Dougherty, M. Mounier, and T. Akenine-Möller. 2003. "An Optimized Soft Shadow Volume Algorithm with Real-Time Performance." In Proceedings of the SIGGRAPH/Eurographics Workshop on Graphics Hardware 2003.
Gartner, Bernd. 1999. "Smallest Enclosing Balls: Fast and Robust in C++." Web page. http://www.inf.ethz.ch/personal/gaertner/texts/own_work/esa99_final.pdf
Stamminger, Marc, and George Drettakis. 2002. "Perspective Shadow Maps." In Proceedings of ACM SIGGRAPH 2002.
The author would like to thank Peter Popov for his many helpful and productive discussions.
'Graphics > 참고자료' 카테고리의 다른 글
| [번역]Performance of Array vs. Linked-List on Modern Computers (2) | 2020.07.08 |
|---|---|
| [번역]Understanding numerical precision (0) | 2020.06.30 |
| [번역]Tile-Based Rendering (0) | 2020.06.25 |
| [번역]Life of a triangle - NVIDIA's logical pipeline (0) | 2020.06.21 |
| [번역][UE4]Rendering Wounds on Characters in UE4 (0) | 2020.06.12 |


