
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- GPU Driven Rendering
- scalar
- rendering
- RayTracing
- vulkan
- optimization
- Graphics
- scattering
- SIMD
- VGPR
- DirectX12
- DX12
- ue4
- 번역
- shader
- Study
- UE5
- ShadowMap
- Shadow
- hzb
- deferred
- unrealengine
- Nanite
- Wavefront
- SGPR
- atmospheric
- texture
- wave
- GPU
- forward
- Today
- Total
RenderLog
[번역]Life of a triangle - NVIDIA's logical pipeline 본문
개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
출처 : https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
By Christoph Kubisch, posted Mar 16 2015 at 12:52PM
Tags: GameWorks, GameWorks Expert Developer, DX12, DX11

획기적인 Femi 아키텍쳐가 발매된지 거의 5년 가까이 지났습니다, 그래픽스 아키텍스쳐의 아래에 있는 원칙을 새로이 할 시간입니다. Femi 는 완전히 확장가능한 그래픽스 엔진을 구현한 첫번째 NVIDIA GPU 였고 그것의 코어 아키텍스쳐는 Maxwell 뿐만 아니라 Kelper 에서 찾을 수 있습니다. 아래의 아티클과 특히 아래의 "compressed pipeline knowledge" 이미지는 다양한 Whitepaper나 GPU 아키텍쳐에 대한 GTC 튜토리얼 같은 공공자료를 기반으로하는 입문서로 제공되어야만 합니다. 이 글을 GPU의 작동방식에 대해 그래픽스의 관점에 중점을 둡니다만 어떻게 쉐이더 코드가 실행되어지는 가와 같은 몇몇의 기본 원리들은 Compute와 동일합니다.
- Fermi Whitepaper
- Kepler Whitepaper
- Maxwell Whitepaper
- Fast Tessellated Rendering on Fermi GF100
- Programming Guidelines and GPU Architecture Reasons Behind Them
Pipeline Architecture Image

GPU는 수퍼 병렬 작업 배포자들이다
왜 모든것이 복잡합니까? 그래픽스에서 우리는 많은 가변 작업량의 데이터의 증폭을 다뤄야만 합니다. 각각의 드로우콜은 다른 양의 삼각형을 생성 할것입니다. 클리핑 이후의 버택스들의 양은 우리의 삼각형이 원래 만들었던 것과 다릅니다. Back-face와 depth 컬링 이후에, 모든 삼각형이 스크린위의 픽셀을 만들진 않습니다. 삼각형의 화면크기는 수백만의 픽셀이 필요하거나 혹은 전혀 필요하지 않다는 것을 의미할 수 있습니다.
결과적으로 현재 GPU는 그들의 프리티브들(삼각형, 선, 점)이 물리 파이프라인이 아닌 논리 파이프라인을 따르도록 합니다. G80의 통합 아키텍쳐(DX9 하드웨어, ps3, xbox360을 생각하자) 이전에는, 파이프라인이 다른 스테이지들과 칩(Chip)에 표현되었으며 작업들은 하나씩 이들을 지나 실행되었을 것입니다. G80은 본질적으로 몇몇 유닛을 버택스와 프래그먼트 쉐이더 계산에 재사용 되어졌습니다, 부하에 따라, 그러나 그것은 여전히 프리미티브/레스터라이제이션 기타 등등에 대해서 연속적인 프로세스를 갖고 있었습니다. Femi에서는 파이프라인이 완전히 병렬이 되었습니다. 그것은 Chip이 Chip에 있는 여러 엔진들을 재사용하여 로지컬 파이프라인(삼각형하나가 거치는 단계들)을 구현하는 것을 의미합니다.
우리가 2개의 삼각형 A와 B를 갖고 있다고 해봅시다. 그들의 일부는 다른 로지컬 파이프라인 단계에 있을 수 있습니다. A는 이미 변환되어졌고 레이터라이즈가 필요합니다. 그것의 몇몇 픽셀은 픽셀 쉐이더 명령어를 이미 수행하고 있을 수 있습니다, 반면에 다른 것은 Depth-buffer(Z-cull)에 의해서 제거되어졌을 수 있습니다, 다른것들은 이미 framebuffer에 쓰여지고 있을 수 있습니다, 그리고 몇몇은 기다리고 있을 것입니다. 그리고 이 과정들 다음에, 우리는 삼각형 B의 버택스들을 가져올 수 있습니다. 따라서 각 삼각형이 로지컬 단계들을 통과해야 하지만, 많은 삼각형들은 그들의 Lifetime 단계의 다른 단계에서 처리되어지고 있을 수 있습니다. 작업(화면에 삼각형의 드로우콜 처리)은 많은 작은 테스크와 하위작업들로 나뉩니다. 그것들은 병렬로 수행됩니다. 각각의 테스크는 사용가능한 리소스로 예약되어집니다, 이것은 특정 종류(버택스 쉐이딩은 픽셀 쉐이딩과 유사함)로 제한되지 않습니다.
펼쳐져있는 강을 생각해봅시다. 병렬 파이프라인 스트림들, 서로 독립된, 모두 자신의 타임라인을 소유한, 몇몇은 아마 다른것들 보다 더 많이 분기할 것입니다. 만약 우리가 삼각형 혹은 현재 작업중인 드로우콜을 기준으로 GPU의 단위를 색상으로 구분하면, 그것은 여러 색상으로 반짝거릴 것입니다 :)
GPU architecture

Femi NVIDIA 는 유사한 원리의 아키텍쳐를 가지고 있기 때문에. 모든 작업을 관리하는 Giga Thread Engine 이 여전히 있습니다. GPU는 여러개의 GPCs (Graphics Processing Cluster) 로 분리 되어집니다, 각각은 여러개의 SMs (Streaming Multiprocessor) 와 한개의 Raster Engine 을 가집니다. 이 프로세들은 수많은 내부연결들이 있습니다, 가장 눈에 띄는 것은 GPCs나 다른 ROP (Render output unit) 서브시스템들 같은 것들 사이의 작업을 이주 시켜주는 Crossbar 가 있습니다.
프로그래머가 생각하는 작업(쉐이더 프로그램 실행)은 SMs에서 실행되니다. 그것은 스레드에서 수학연산을 하는 많은 Cores를 포함합니다. 한개의 스레드는 버택스 혹은 픽셀 쉐이더의 호출일 수 있습니다. 이러한 Core들과 다른 유닛들은 32개의 스레드 그룹을 Warp로 관리하고 수행될 명령어를 Dispatch Units에 전달하는 Warp Schedulers 로 수행되어집니다. 코드로직은 스케쥴러에 의해서 처리되며 특정 코어 자체의 내부에서 처리되지 않습니다. 그것은 Dispatcher로 부터 "sum register 4234 와 register 4235 그리고 store in 4230" 과 같은 것을 보여줍니다. 코어 그 자체는 코어가 똑똑한 CPU에 비교해서 바보입니다. GPU는 똑똑함을 더 높은 레벨로 올려줍니다, 그것은 전체 작업이 한 세트로(혹은 당신이 원하면 여러개로)를 수행합니다.
얼마나 많은 유닛이 실제로 GPU에 있는지는 Chip의 구성자체에 달렸습니다. 위의 GM204에 보는것 처럼 4 개의 GPCs 는 각각 4 개의 SMs를 가지고 있습니다, 그러나 Tegra X1 은 Maxwell 디자인의 1 GPC와 2개의 SMs가 있습니다. SM 디자인 자체(코어의 수, 명령 유닛들, 스케쥴러...) 는 세대에서 세대로(첫번째 이미지를 보세요) 시간이 감에 따라서 변화했으며 Chip이 하이엔드 데스크탑에서 노트북, 모바일까지 더 효율적으로 확장 가능하도록 해줬습니다.
The logical pipeline
간단하게 하기위해서 여러 세부사항이 제거되었습니다. 우리는 드로우콜이 이미 데이터로 채워지고 GPU의 DRAM에 있으며 Vertex와 Pixel (GL: fragmentshader) 쉐이더에서만 사용되는 몇몇 인덱스와 버택스 버퍼를 참조한다고 가정합니다.
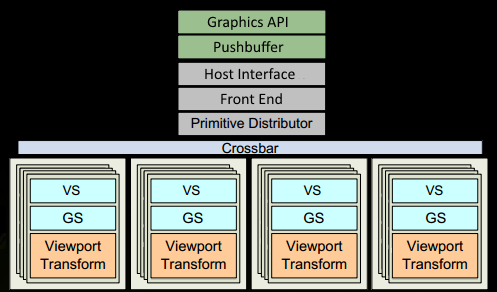
1. 프로그램은 Drawcall을 그래픽스 API (DX or GL) 에서 만듭니다. 이것은 드라이버에 몇몇 지점에 도착합니다. 그 지점에서 "적법한" 것들인지 간단한 확인과 PushBuffer 내부에서 GPU가 읽을 수 있는 커맨드를 추가합니다. 수 많은 병목이 CPU 측에서 일어날 수 있습니다, 그리고 그것은 왜 프로그래머가 API를 잘써야하는지 이유이기도 합니다, 그리고 기술들은 오늘날은 GPU에 영향을 줍니다.
2. 잠시후 혹은 "flush"를 호출한 후, 드라이버는 pushbuffer 를 작업들로 충분히 채우고 GPU 에서 처리될 수 있도록 보냅니다 (OS가 관여 함). GPU의 Host Interface 는 Front End 를 통해 처리될 커맨드들을 선택합니다.
3. 우리는 우리의 작업을 인덱스버퍼의 인덱스 처리와 여러개의 GPUs에게 보낼 삼각형을 생성 작업 배치(batches) 생성 함으로써 Prmitive Distributor 에서 분배하기 시작합니다.

1. GPC에서는, SMs의 특정 Poly Morph Engine이 Triangle indices 에서 버택스데이터를 가져옵니다 (Vertex Fetch).
2. 데이터를 가져온 후, 32개의 스레드들의 Warps는 SM 내부에서 스케쥴링 되어지고 Vertices에서 처리됩니다.
3. SM의 warp 스케쥴러는 전체 warp에 대한 명령들을 순서대로 제출합니다. 스레드들은 각각의 명령을 lock-step으로 실행하고 만약 실행 되지 않아야 한다면 개개별로 실행하지 않도록 설정(Mask-out) 할 수 있습니다. Masking이 필요한 여러가지 이유가 있을 수 있습니다. 예를들어 현재 명령은 "if (true)" 분기이고 스레드 특정 데이터는 "false"로 평가합니다, 또는 반복문의 끝나는 기준에 한 스레드는 도달했고 다른스레드는 도달하지 않았을 수 있습니다. 그러므로 쉐이더 내에서 수많은 분기는 Warp 내의 모든 스레드에 대해 시간 소비를 굉장히 증가시킬 수 있습니다. 스레드들은 한개의 Warp 처럼 개별적으로 진행될 수 없습니다! 그러나 Warps는 서로 독립적입니다.
4. Warp의 명령은 한번에 완료되어지거나 여러번의 처리가 필요합니다. 예를들어 SM은 보통 load/store 를 할때 단위가 기본 수학연산을 할때 보다 적습니다.
2. 몇몇 명령들이 다른 것들 보다 완료하는데 더 많이 걸리면, 특히 메모리 로드, Warp 스케쥴러는 간단히 메모리를 기다리지 않는 다른 Warp로 전환합니다. 이것은 GPU가 어떻게 메모리 읽기 지연 극복하는지의 핵심 개념입니다, 그들은 간단히 활성된 스레들의 그룹을 전환합니다. 전환을 빠르게 하기 위해서, 모든 스케쥴러로 관리되는 스레드들은 Register-file에 그들 자신의 레지스터들을 가집니다. 더 많은 레지스터가 쉐이더에 필요하면, 스레드/Warp 공간이 더 적어집니다. 우리가 전환 가능한 Warps가 더 적어질수록, 우리가 명령들이 완료되기를 기다리는 동안(주로 메모리 가져오기) 할 수 있는 작업들이 덜 유용해집니다.
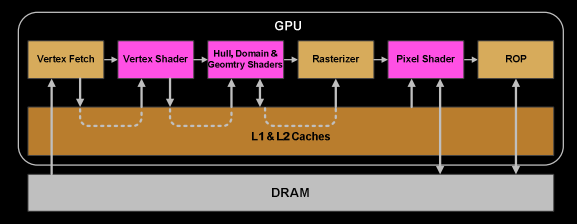
1. Warp가 버택스 쉐이더의 모든 명령들을 완료하면, 그 결과에 Viewport Transform 에 처리합니다. Triangle은 Clipspace volume에 의해서 잘리며 Rasterization을 준비합니다. 우리는 L1과 L2 캐시를 모든 cross-task 통신 데이터에 사용합니다.
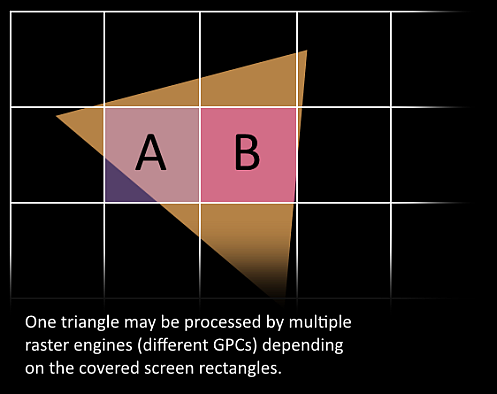
1. 이제 재미있는 부분입니다, 우리의 이제 막 Triangle은 잘게 나뉘어지려고 하고 현재 위치하는 GPC를 떠날 가능성이 있습니다. Triangle의 바운드 박스는 어떤 Raster engine이 작업에 필요한지를 결정하는데 사용됩니다, 각각의 engine은 여러개의 화면의 타일을 다룹니다. 그것은 삼각형을 Work Distribution CrossBar로 하나 혹은 여러개의 GPCs 로 보냅니다. 우리는 우리의 삼각형을 수많은 작업들로 효과적으로 나눕니다.

1. Targt SM에서 Attribute Setup 은 보간된 것들(예를들어 버택스 쉐이더에서 생성된 출력)은 픽셀쉐이더 친화적인 형식인 것을 보장합니다.
2. GPC 의 Raster Engine은 수신한 삼각형으로 작업하여 픽셀의 정보를 자신이 맡은 섹션에 생성합니다. (후면컬링과 Z-cull 도 처리함)
3. 다시 우리는 32 pixel thread 를 일괄 처리합니다, 혹은 8번의 2x2 픽셀 Quad라 하기 더 좋습니다, 이것은 우리가 픽셀쉐이더에서 작업하는 가장 작은 단위입니다. 2x2 Quad는 우리가 텍스쳐 밉맵 필터링과 같은 것을 위한 변화율 계산하는 것을 가능케 해줍니다 (Quad 에서 텍스쳐 좌표의 큰변화는 더 높은 mip을 사용하도록 함). 이런 Sample 위치가 실제로 삼각형 위에 있지 않은 2x2 Quad 의 스레드는, 제거되어집니다(gl_HelperInvocation). Local SM의 warp 스케쥴러중 하나는 픽셀 쉐이더 작업을 관리할 것입니다.
4. 같은 warp 스케쥴러 명령은, 버택스 쉐이더의 Logical 단계에 있는, 이제 픽셀 쉐이더 스레드에서 수행되어집니다. Lock-step 처리는 특히 편리합니다. 왜냐하면 모든 스레드는 같은 명령점 까지 그들의 데이터가 계산되어지는 것을 보장되기 때문에, 우리는 Pixel Quad 내에서의 값 접근에 거의 비용이 들지 않기 때문입니다 (NV_shader_thread_group).

1. 아직 멀었나요? 거의, 우리의 픽셀쉐이더가 렌더타겟에 그릴 컬러 계산과 Depth value 계산을 완료하였습니다. 이 지점에서 우리는 ROP(Render output unit) 서브시스템 중 하나에 데이터를 넘기기 전에 원래의 API 삼각형 순서를 고려해야 합니다. 그리고 ROP 서브시스템은 여러개의 ROP 유닛을 가지고 있습니다, 여기서 Depth-testing, Framebuffer와 블랜딩 기타 등등은 수행되어집니다. 이러한 연산들은 우리가 2개의 삼각형이 같은 픽셀을 처리 할때 한 삼각형의 컬러와 또 다른 삼각형의 depth value를 가지지 않도록 한번에 하나씩(atomically) 처리할 필요가 있습니다 (한번에 하나의 color/depth 가 설정되어야 함). NVIDIA 는 보통 메모리 압축을 적용합니다, 메모리 대역폭 요구를 줄이기 위해, 이것은 "효과적"으로 대역폭을 증가시킵니다(GTX 980 pdf 보세요).
끝났습니다, 우리는 우리는 렌더타겟에 몇개의 픽셀을 썼습니다. 나는 이 정보가 GPU내에서의 작업과 데이터 흐름을 조금 더 이해하는데 도움이 되길 바랍니다. 또한 또다른 부작용에 대한 이해로 왜 CPU와의 동기화가 큰 문제가 될 수 있는지에 대해서도 도움이 될 것입니다. 그것은 모든 것들이 완료되기를 기다려야만 하고 새로운 작업이 제출되지 않아야 합니다(모든 유닛이 대기 상태가 되는것), 새로운 작업을 보낼때를 의미, 모든 것이 완전히 로드되는데 다시 시간이 걸립니다, 특히 큰 GPU에서요.
아래의 이미지에서 우리가 CAD 모델을 렌더한 것을 볼 수 있고 서로 다른 SMs와 warp id 들로 색상을 준 것을 이미지에 반영하였습니다(NV_shader_thread_group). 작업의 분배가 프레임마다 다를 것이므로, 일관된 프레임(Frame-coherent)의 결과가 아닐 수 있습니다. 이 장면은 여러 드로우콜들로 그려졌습니다, 그것 중 여러개가 병렬로 처리되어졌을 것입니다 (NSIGHT 를 사용하면 당신은 병렬 드로우콜 역시 볼 수 있습니다).

Further reading
- A trip through the graphics-pipeline by Fabian Giesen
- Performance Optimization Guidelines and the GPU Architecture behind them by Paulius Micikevicius
- Pomegranate: A Fully Scalable Graphics Architecture describes the concept of parallel stages and work distribution between them.
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] Perspective Shadow Maps: Care and Feeding (0) | 2020.06.28 |
|---|---|
| [번역]Tile-Based Rendering (0) | 2020.06.25 |
| [번역][UE4]Rendering Wounds on Characters in UE4 (0) | 2020.06.12 |
| [번역]Gaussian Smoothing (0) | 2020.06.06 |
| [번역][Nvidia White Paper] Volume Light (0) | 2020.05.28 |



