
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Wavefront
- shader
- deferred
- vulkan
- Graphics
- SGPR
- SIMD
- UE5
- texture
- Nanite
- RayTracing
- ShadowMap
- atmospheric
- rendering
- Shadow
- forward
- optimization
- unrealengine
- 번역
- hzb
- DirectX12
- GPU Driven Rendering
- ue4
- DX12
- scattering
- GPU
- VGPR
- Study
- wave
- scalar
- Today
- Total
RenderLog
[번역] INTRO TO GPU SCALARIZATION – PART 2 -SCALARIZE ALL THE LIGHTS 본문
[번역] INTRO TO GPU SCALARIZATION – PART 2 -SCALARIZE ALL THE LIGHTS
scahp 2020. 8. 8. 02:12개인 공부용으로 번역한 거라 잘못 번역된 내용이 있을 수 있습니다.
또한 원작자의 동의 없이 올려서 언제든 글이 내려갈 수 있습니다.
주의:
Note: 아래의 포스트들은 GCN에 특화될 것입니다, 나의 첫번째 확장으로 충분히 깔끔하게 하지 못했습니다, 그렇기 때문에 PSA가 글이 맨위에 있습니다! 만약 당신이 그것을 읽었고 그게 혼란스럽게 했다면 미안합니다.
이것은 나의 짧은 시리즈인 스칼라화의 2번째 파트입니다. 이것은 당신이 첫번째 파트를 읽었거나 Wavefront가 무엇인지, SGPR/VGPR, SALU/VALU, SMEM/VMEM이 무엇인지, 그리고 wave instrinsics에 대해서 알고 있고 스칼라화가 무엇인지 알고있다고 가정합니다.
단지 기억해둘점은, 이 미니-시리즈는 스칼라화를 처음 접하는 사람을 타겟으로 합니다, 그래서 획기적인 새로운 기술이 포함되진 않을 것입니다.
시작하기 전에, 만약 내가 추가한 gif의 속도가 당신에게 맞지 않는다면, this is the pptx 파일을 사용하세요. 이방식으로 당신은 단계들을 당신의 여가시간에 할 수 있습니다!
Part 1 – Introduction to concepts and simple example.
Part 2 – Scalarizing a forward+ light loop.
THE PROBLEM
꽤 오래동안 타일 그리고 클러스터드 데이터 구조는 라이팅 처리의 산업 표준이 되었습니다. 이 두 가지 경우에 우리는 라이트를 우리의 장면의 Cells에 할당합니다. - 스크린에 정렬된 타일 혹은 3D 클러스터들 - 그리고나서 각각의 픽셀에 대해서, 우리는 셀에 연관되어있는 라이트를 확인하고 쉐이딩을 수행합니다.
또다른 일반적인 추세는 포워드 쉐이딩을 사용하는 것입니다, 그러나 이것은 성능 문제를 불러옵니다: 동일한 Wave 내의 픽셀은 다른 라이트 세이트에 접근해야 할지도 모릅니다.
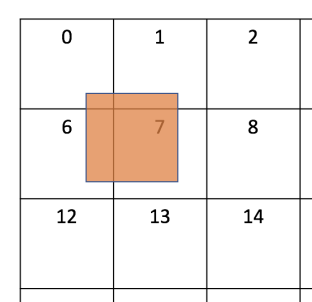
그것은 우리가 Wave 내에서 라이트 데이터 로드에 많은 분기를 가질 것이고 우리가 이전글로 부터 이것이 최선이 아니라는 것을 배웠습니다. ([0]을 보세요). 그러나! 우리는 스칼라화가 가능할것입니다!
샘플 라이트 반복문을 보세요, 스칼라화가 되지 않았음, 3개의 분기된 스레드 입니다:
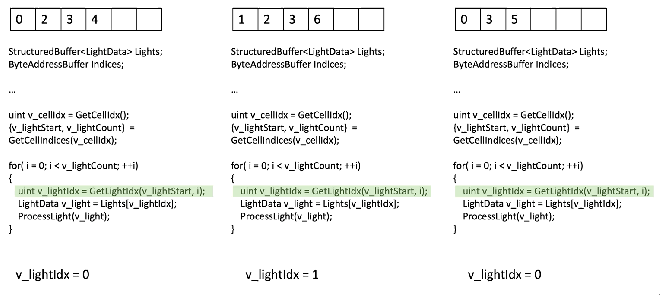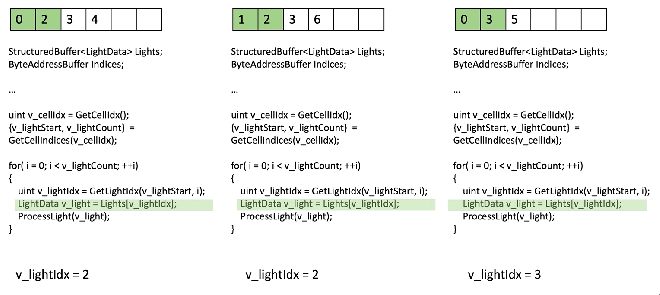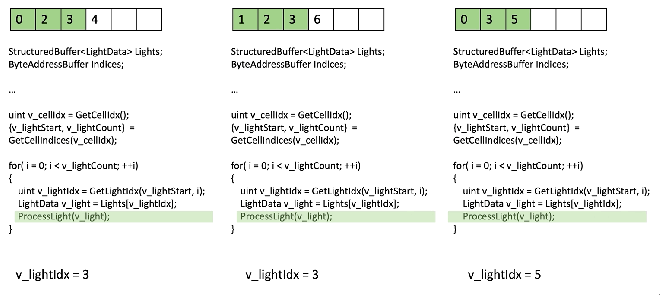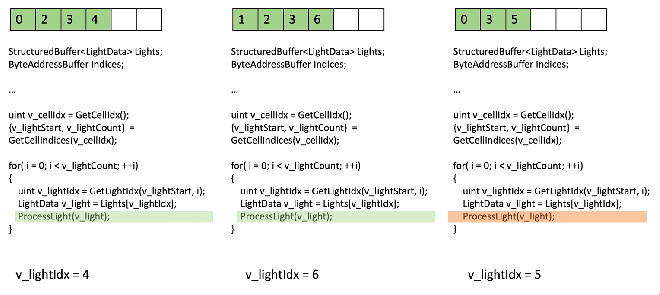
모든 것은 VGPR에 있고 그것은 vector load 일 것입니다! 좋지 않습니다.
일반적인 장면을 고려해봅시다, 우리는 아래와 같이 말할 수 있을 것입니다:
- Wave에 있는 픽셀은 같은 모두 cell에 접근할 가능성이 있습니다.
- 셀의 근처는 같은 내용을 담을 가능성이 있습니다.
이 두가지 고려는 Coherency! 라고 외칩니다.
STRATEGY #1 – LOOPING CLUSTERS AND LANE MASKING
어떻게 대부분의 픽셀이 같은 Cell에 접근하는지 알았습니다, 그리고 그것의 의미는 만약 분기가 있다면, Wave 범위에서 우리가 다른 많은 Cell에 접근하지는 않을 것이라는 겁니다. 그래서? 그래서 우리는 Cell 인덱스를 스칼라화 하고, 각각의 스레드에 대해, Wave로 모든 셀을 반복해서 접근할 것입니다.
먼저 ([Drobot 2017]에서) 어떻게 하는지 살펴보고 무슨일이 일어나고 있는지 분석할 것입니다:
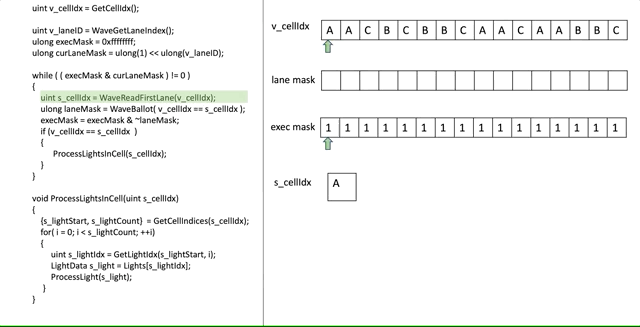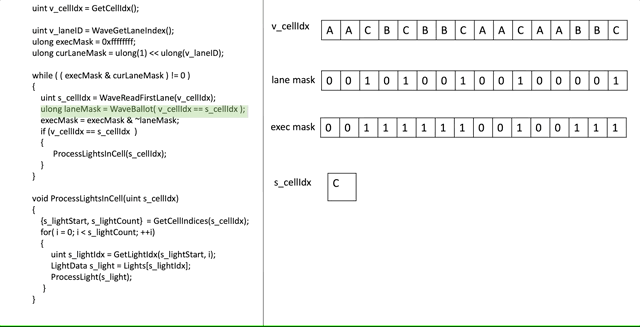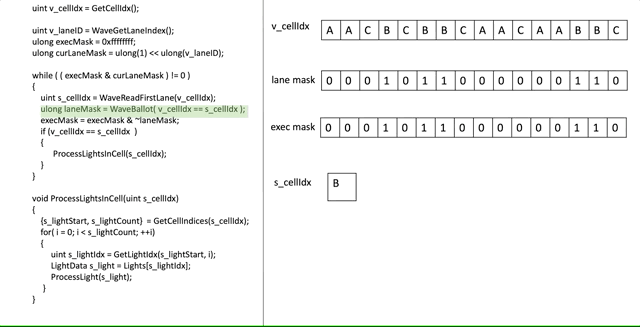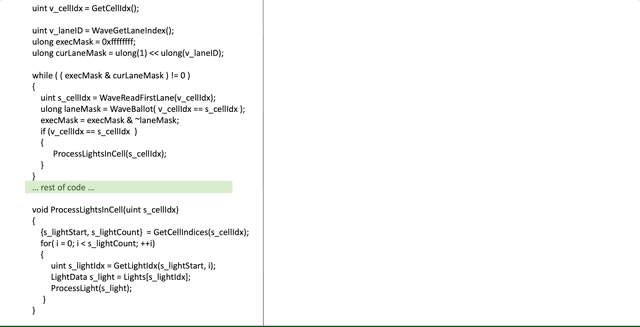
겁나나요? 약간 그럴 것입니다! 희망적이게도 스탭-바이-스탭 실행이 도움을 줍니다, 그러나 코드의 부분을 자세히 살펴봄으로써 더 깊게 파봅시다.
ulong execMask = 0xffffffff;이전 글에서 exe mask의 컨셉에 대해 언급했습니다. 여기서 우리는 어떤 스레드가 특정 cell을 처리해야할지 결정하기 위해서 우리자신의 exe mask를 만들고 있습니다. 물론, 우리는 프레임의 시작부분에 있기 때문에, 우리는 모든 스레드를 "살아있다"로 표시합니다, 따라서 0xffffffff 입니다.
uint v_laneID = WaveGetLaneIndex();
ulong curLaneMask = ulong(1) << ulong(v_laneID);이 비트는 간단합니다, 우리는 0번째 스레드가 모든 스레드를 위해서 mask를 만들고 있습니다, n번째 lane의 n번재 비트를 제외하구요. 즉, lane 3은 0000000…001000 마스크를 가질 것입니다.
while( ( execMask & curLaneMask ) != 0 )
이것이 우리의 반복문 조건입니다. 간단히 말해서, lane은 exe mask에 있는 비트가 unset 되면 중단 될것입니다. 우리가 scalar 방식으로 모든 cell을 순회할 것이라는 의미입니다. 그리고 현재 스레드는 cell이 처리되는 즉시 중단 할 것입니다.
uint s_cellIdx = WaveReadFirstLane(v_cellIdx);
ulong laneMask = WaveBallot(v_cellIdx == s_cellIdx);이것은 중요한 비트입니다. 우리는 먼저 cell의 인덱스를 첫번째 lane으로 부터 얻습니다, 이것은 SGPR에 있을 것입니다. 그리고나서, Ballot을 통해, 우리는 첫번째 활성 스레드의 cell로부터 라이트를 처리하가 필요한 다른 스레드를 우리에게 알려주는 mask를 만듭니다...
execMask = execMask & ~laneMask;not 연산을 한 laneMask의 논리 and 연산을 사용하여 우리는 그것을 만듭니다, 우리는 본질적으로 말하고 있습니다: "이 스레드들은 그들이 필요한 cell을 처리하려던 참이다, 그래서 우리는 그들의 처리를 완료할 것이다". 우리는 그들을 처리했기 때문에, 우리는 exe mask에서의 그들의 비트를 0으로 만듭니다. 그결과 그들은 다음 반복에서 루프를 탈출합니다.
if( s_cellIdx == v_cellIdx )
ProcessLightsInCell(s_cellIdx)그리고 마지막으로, 만약 실제로 현재 스레드가 첫번째 활성 스레드와 동일한 cell을 처리할 필요가 있다면, 우리는 그 cell을 처리합니다!
이제, cell의 주소가 scalar이기 때문에, cell의 내용은 scalar 로드를 통해서 SGPR에 로드 될 수 있습니다. 만세! 우리는 반복문을 스칼라화 했습니다!
이제 우리는 그것을 비트별로 살펴보았습니다, 다시한번 고수준의 언어로 정리해보겠습니다:
그것과 관련된 cell 처리될때까지, 각 스레드는 첫번째 활성 스레드의 cell 인덱스를 읽을 것입니다. 만약 이것이 그것자신이 소유한 cell 인덱스와 일치한다면, 그 스레드는 그 cell이 루프를 탈출하도록 하고, 활성상태를 중단 하고 남은 wave가 같은 프로세스를 완료하기를 기다립니다. 모든 스레드는 모든 cell을 같은 순서로 처리하므로, 프로세는 스칼라입니다.
만약 여전히 깔끔하지 않가면, 나는 gif를 단계별로 다시 따라가보길 제안합니다. 파워포인트를 사용해서 당신의 속도에 맞게 보세요 :)
더 나은가요? 아마, 그럴거에요.
여기서의 문제는 우리가 많은 추가 작업을 할 수 있는가 하는 점입니다.
우리의 coherency 가정을 기억하세요? 특히: “cell의 근처는 비슷한 내용을 가질 가능성이 있습니다”.
우리는 cell 레벨로 스칼라화를 하고 있기 때문에, 우리는 각 wave에서 특정 픽셀에 접근하는 cell의 전체 내용을 처리하고 있습니다. 그것은 예를들어 만약 42번 라이트가 특정 wave가 접근하는 3개의 cell에서 등장한다면, 우리는 3번 분리된 처리를 할 것입니다.
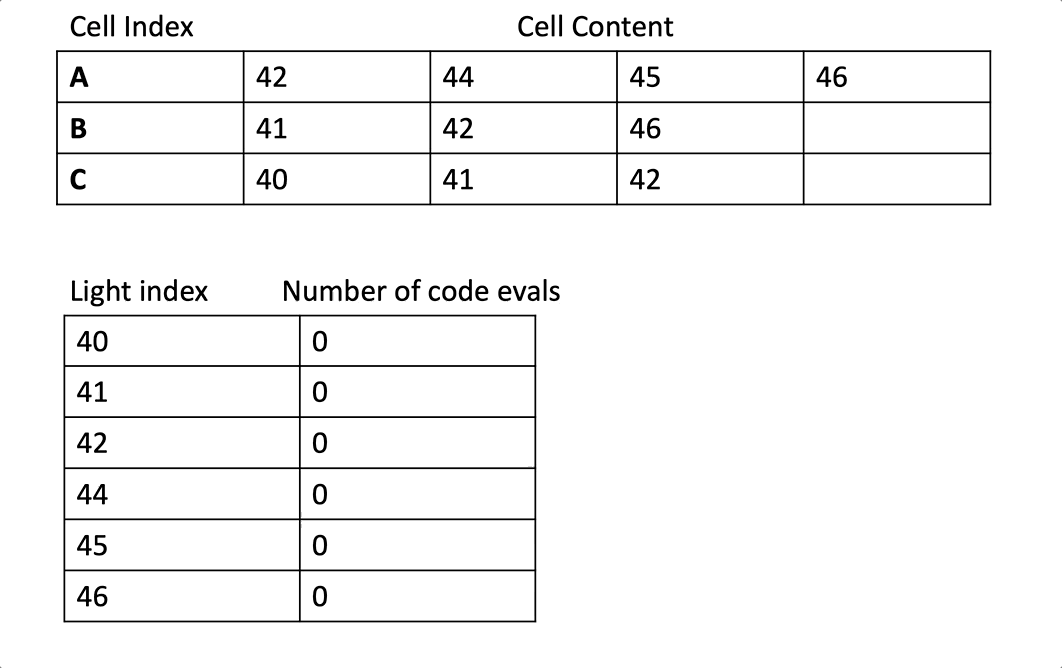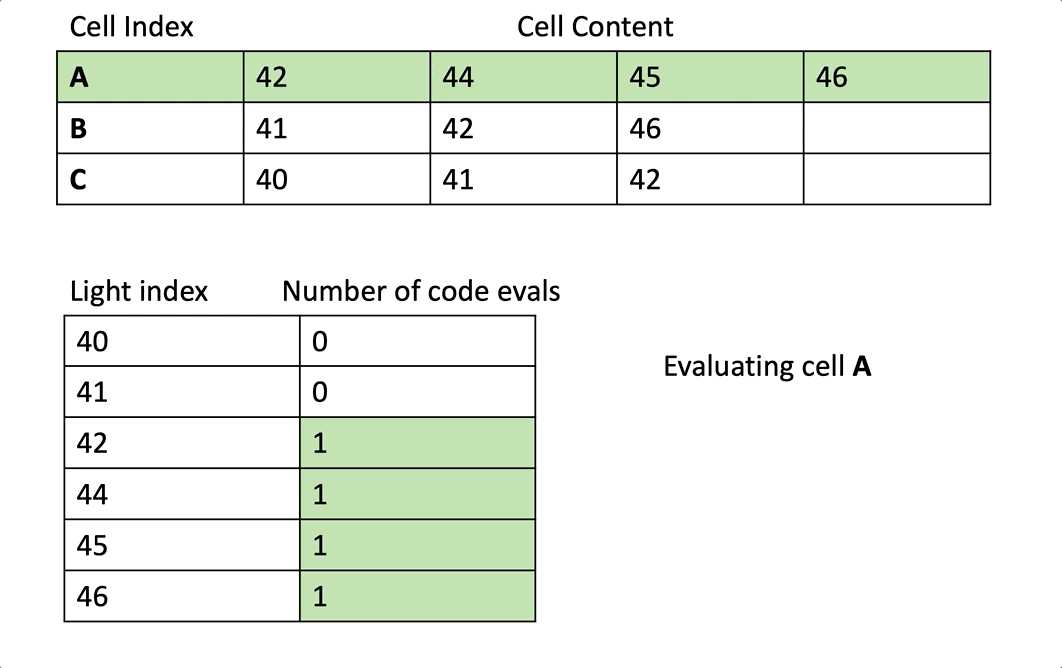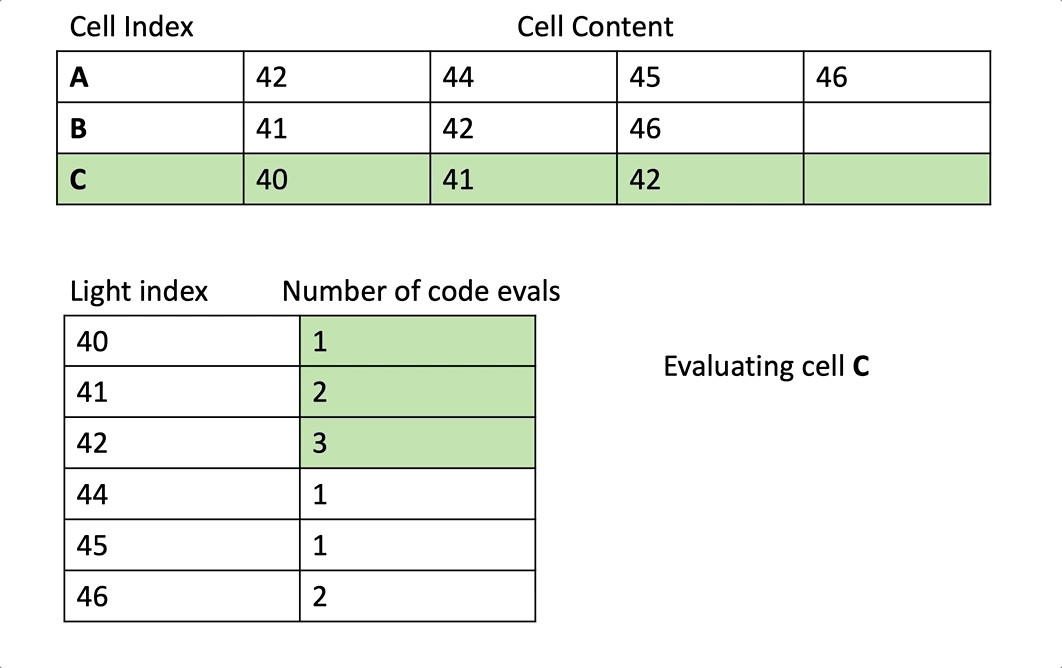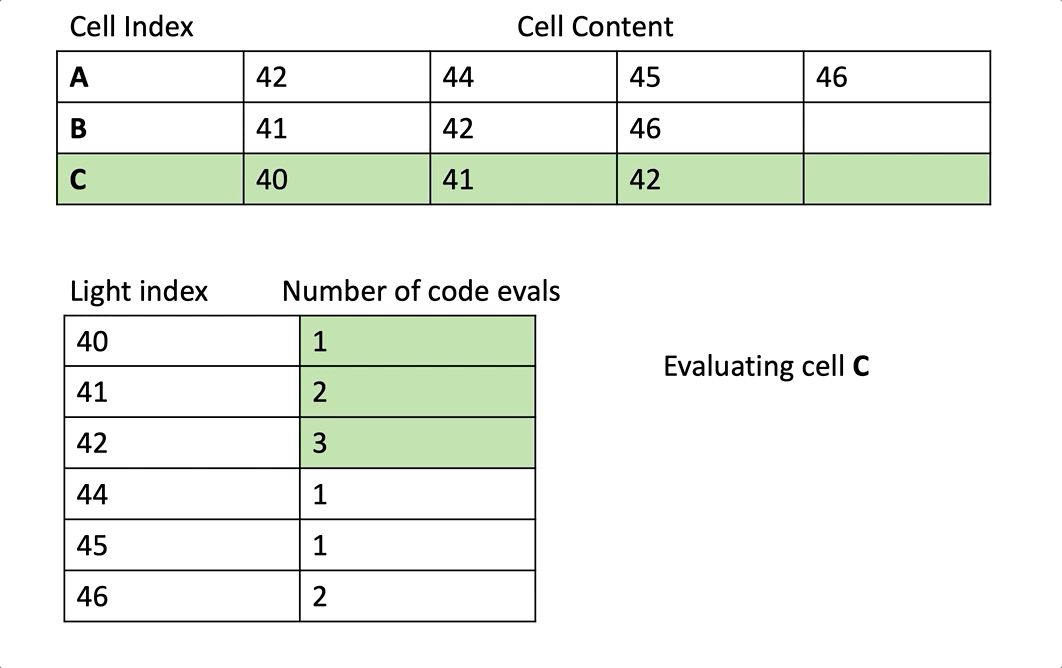
내가 의미하는 “3번의 분리된 처리”를 명확하게 하기 위해 노트1을 보세요
cell 당 보가 라이트 당 스칼라화를 한다면요?
이것은 [Drobot 2017]가 계속해서 보여줄 것이지만 더 많은 소스와 더 다양한 기술을 위해서 DOOM[Sousa et Geffroy 2016]으로 부터 예제를 따를 것입니다.
STRATEGY #2 – SCALARIZE SINGLE LIGHT INDICES
이전에 내가한 것 처럼, 나는 여기 코드 실행을 단계별로 보여주는 gif를 가져올것 입니다. 그리고나서 더 자세한 부분을 파볼 것입니다. 주의할점은 [Sousa et Geffroy 2016]는 코드를 제공하지 않는다는 점입니다, 그래서 이것은 내 구현한 것입니다, 부디 이것이 옳바르기를 바랍니다. :)
개념상 이것은 모든 cell의 내용을 단일 리스트로 만드는 것과 동일합니다. 그리고 모든 스레드가 그 리스트를 접근할 것입니다. 어떻게 이것을 이뤄 낼까요? 모든 단계에서, wave의 모든 스레드는 wave의 특정 스레드에서 처리가 필요한 모든것들 중 가장 낮은 인덱스로 처리되지 않은 요소를 처리합니다.
더 자세히 봅시다.
uint lightOffset = 0;
while(lightOffset < lightCount)lightOffset은 현재 스레드와 관련된 cell의 라이트 리스트와 연관된 인덱스입니다. 우리는 리스트에 있는 모든 라이트들이 처리 될때까지 반복할 것입니다.
uint v_lightIdx = GetLightIdx(v_lightStart, lightOffset);
uint s_lightIdx = WaveActiveMin(v_lightIdx);
이것은 어떤 라이트를 wave가, 전체적으로, 처리할 것인지우리가 선택하는 곳 입니다. 우리는 첫째로 처리되지 않은 라이트 인덱스를 각 스레드를 위해 고릅니다. 그리고나서 우리는 그들중 가장 작은 것을 선택합니다. 이것은 우리에게 스칼라 로드를 수행할 수 있게 해주어 SGPR에서의 인덱스를 줄 것입니다!
WaveActiveMin은 비활성 lane들을 무시한다는 것을 조심하세요 그리고 염두해두세요, 이것은 중요합니다, 만약 당신이 중요한 디테일을 위해서 이것을 실제로 구현할 것이라면 노트2번을 보세요.
if(s_lightIdx == v_lightIdx)
{
v_lightOffset++;
LightData s_light = Lights[s_lightIdx];
ProcessLight(s_light);
}
명백히 우리는 필요한 경우만 라이트로 쉐이딩을 하고싶습니다! 만약 현재 스레드의 첫번째 처리되지 않은 라이트가 전체 wave에서 가장 작은 인덱스와 같다면, 우리는 계속해서 그런 라이트를 SGPR에서 처리할 것입니다.
처리된 라이트를 가진 모든 스레드들은 그들의 리스트에서 그들의 v_lightOffset을 증가 시키므로써 함께 전진할 것입니다. 이런 방법으로 s_lightIdx는 다시 처리되지 않을 것입니다.
만약 특정 스레드를 위한 라이트 인덱스가 wave에서 최소가 아니라면, 우리는 루프의 다음 순회를 위해 동일한 요소를 계속해서 가리킵니다. 그리고 우리는 쉐이딩과 로드를 넘어서 분기합니다.
예! 우리는 루프를 스칼라화 했고 각각의 라이트는 한번만 처리됩니다! 성공... 그렇죠?
그렇습니다! 그러나 우리가 더 잘할 수 있는 경우가 있습니다.
STRATEGY #2 BIS – ADDING A FAST PATH
우리가 이전 섹션에서 널리 사용한 WaveActiveMin()은 불행히도 싼 연산이 아닙니다.
그것은 꽤 많은 lane swizzles과 min 연산이 매핑합니다.
우리의 Coherency 가정 중 하나를 기억하나요? Wave에 있는 픽셀들은 모두 같은 cell에 접근할 가능성이 있습니다.
만약 모든 픽셀이 마침내 같은 cell에 접근한다면? 우리는 이경우에 더 빠르게 할 수 있습니다.
uint v_cellIdx = GetCellIdx();
uint s_firstLaneCellIdx = WaveReadFirstLane(v_cellIdx);
// A mask marking threads that process
// the same cell as the first active thread.
ulong laneMask = WaveBallot(v_cellIdx == s_lane0CellIdx);
// True if all the lanes need to process the same cell
bool fastPath = (laneMask == ~0);
if(fastPath)
{
// This will load lights in SGPRs since cell address is scalar!
ProcessLightsInCell(s_firstLaneCellIdx)
}
else
{
Slower-scalarization-path
}여기에서, 이제 우리는 우리의 반복문 스칼라화를 가집니다. 그리고 심지어 아주 일반적인 경우에 대해 아주 빠른 경로를 가집니다.
다음은 무엇을까요? 우리는 몇가지 예제를 함께 살펴보았습니다, 나는 [Drobot 2017]의 남은 부분을 해보길 강하게 추천합니다, 그것은 진짜 굉장한 프리젠테이션입니다 (그리고 만약 당신이 xbox 개발자로 등록되어있따면, XFest 아카이브를 통해 확인해보세요). 접근방식의 구현은 Matt Pettineo 의 the excellent deferred texturing sample 에서 찾을 수 있습니다.
당신이 바라는 모든 것을얻을 수 있습니다! 스칼라화의 기회를 당신의 코드에서 찾아보세요!
그게 전부입니다! 이것이 도움이 되었으면 합니다, 만약 충분히 명확하지 않은 것이 있다면 제 트위터나 코멘트를 통해서 부디 저에게 알려주세요.
'그럼 다음 번 까지!
– Francesco (@FCifaCiar)
NOTES
[0] – 타일드 디퍼드는 같은 문제가 발생하지 않습니다 왜냐하면 우리가 wave와 tile을 정렬할 수 있을 것이기 때문에 Coherent 읽기가 가능합니다.
그러나 클러스터드 디퍼드는 여전히 분기가 나타납니다. 왜냐하면 Wave의 스레드들은 z 축에서 다른 클러스터에 접근할 수 있기 때문입니다.
[1] – 염두해둘 점은 "evaluate"와 "process"에서 나는 스레드에 비활성인 시간을 포함합니다, 그러나 같은 코드 경로에서 Wave에서 다른 스레드는 활성화 상태라서 우리는 모든 코드를 거쳐야 합니다. (파트1에서 Wave에서 스레드가 lockstep으로 진행한다는 점을 기억해주세요). 걱정마세요, 동일한 라이트로 여러번 쉐이딩 되지 않을 것입니다.
[2] – 픽셀 쉐이더는 항상 2x2의 쉐이딩 quad를 gradient 연산을 위해서 실행합니다(ddx, ddy, mip selection 등등). 이것을 하려면, 쉐이더 엔트리에서 lane이 비활성화 되어있지만 인접 2x2 quad lane은 활성화 상태면, 이것은 "whole quad mode" (WQM)라 불리는 것이 활성화 됩니다.
이 모드는 필요할 것이지지만 비활성화 된 lane이 "Helper lanes" 역할을 할것이라 가정합니다.
이제, Helper lanes은 다른 lane 처럼 코드를 계속해서 실행할 것입니다. 그러나 마지막에 결과는 버려질 것입니다. 그래서, 우리는 그것들에 대한 라이트 인덱스를 가질 것입니다, 그러나 WaveActiveMin()은 기술적으로 그들을 비활성화된 것으로 보지 않을 것입니다.
우리에게 이게 무슨 의미죠? 자, Helper lane이 다른 활성 lane의 어디에서 있지 않은 라이트 인덱스를 가지고 있다고 가정합시다, WaveActiveMin은 결코 s_lightIdx를 그런 인덱스로 설정하지 않을 것이기 때문에, Helper lane은 결코 아래의 내용을 통과할 수 없을 것입니다:
if(s_lightIdx == v_lightIdx)
{
v_lightOffset++;
......그러므로 그들은 영원히 반복문에 갇히게 되어 Hang을 유발합니다! 이것을 피하기 위해서, 다음과 같이 변경합니다
if(s_lightIdx >= v_lightIdx)비슷하게, 만약 Helper lane이 실행중인 유일한 lane이라면, WaveActiveMin은 -1을 리턴할 것입니다!
나는 이 조정을 단계별 실행에서 제거하였습니다. 왜냐하면 그것이 약간 더 분석하기 볶잡하게 만들 수 있어서 입니다. 이제 당신이 알듯이, 알고리즘을 구현할 때 이러한 세부사항을 기억하세요, 그렇지 않으면 당신은 성가신 GPU Hang을 만날 수 있습니다.
'Graphics > 참고자료' 카테고리의 다른 글
| [번역] Effective Water Simulation from Physical Models (0) | 2020.09.22 |
|---|---|
| [번역]Real-Time Atmospheric Scattering (0) | 2020.08.22 |
| [번역] Accurate Atmospheric Scattering (0) | 2020.08.07 |
| [번역] INTRO TO GPU SCALARIZATION – PART 1 (0) | 2020.07.20 |
| [번역][Nvidia White Paper] Cascaded ShadowMaps (0) | 2020.07.17 |



