
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- texture
- vulkan
- Wavefront
- 번역
- scalar
- unrealengine
- Graphics
- DX12
- forward
- rendering
- VGPR
- atmospheric
- RayTracing
- wave
- shader
- SGPR
- SIMD
- GPU Driven Rendering
- GPU
- scattering
- Nanite
- DirectX12
- Shadow
- Study
- UE5
- ue4
- optimization
- ShadowMap
- hzb
- deferred
- Today
- Total
RenderLog
[UE5] Nanite (2/5) 본문
[UE5] Nanite (2/5)
최초 작성 : 2024-03-21
마지막 수정 : 2024-03-21
최재호
목차
1. 환경
2. 목표
3. 내용
3.1. TwoPassOcclusionCulling 의 컬링파트
3.2. FRenderer 생성 및 InitArgs 코드 분석
3.3. Main/Post Culling 전체 코드 레이아웃
3.3.1. AddPassInitNodesAndClusterBatchesUAV
3.3.2. AddPass_InstanceHierarchyAndClusterCull 전체 레이아웃
3.3.2.1. FInstanceCull_CS (MainPass)
3.3.2.2. AddPass_NodeAndClusterCull (MainPass) 전체 레이아웃
3.3.2.2.1. LoadCandidateNodeDataToGroup
3.3.2.2.2. ProcessNodeBatch
3.3.2.2.3. ProcessClusterBatch
3.3.2.3. CalculateSafeRasterizerArgs
4. 레퍼런스
1. 환경
Unreal Engine 5.3.2 (release branch 072300df18a94f18077ca20a14224b5d99fee872)
개인적으로 분석한 내용이라 틀린 점이 있을 수 있습니다. 그런 부분은 알려주시면 감사하겠습니다.
이번 글은 한 번에 많은 길이의 코드를 분석하는 부분이 종종 등장합니다. 그래서 글을 2개 띄우고 한쪽은 설명 부분을 한쪽은 코드 이미지를 최대화해서 보는 것을 추천합니다.
2. 목표
Nanite 에 들어간 핵심 기술들을 파악하고 BasePass 렌더링 과정을 코드레벨로 이해해 봅시다.
이번 글에서는 TwoPassOcclusionCulling 의 MainPass 중 인스턴스와 클러스터 컬링에 대한 부분을 확인해봅시다. MainPass 는 이전 프레임에 생성된 HZB 에 대해서 인스턴스와 클러스터 컬링을 수행합니다.
아마 이번 글에서 다루는 내용이 전체 Nanite 내용 중 가장 복잡하고 내용이 많을 것입니다. 하지만 이 부분만 넘어가면 그 이후로는 편하다는 뜻도 됩니다.
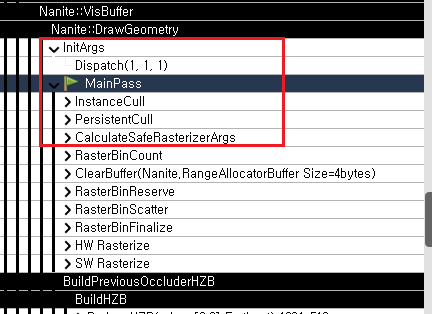
이전 글에서 이야기 했던 것 처럼 이 글은 총 5개로 구성될 예정입니다.
1. Nanite 1/5 : Nanite 에서 사용하는 주요 기술과 MeshDrawCommand 생성 및 VisibilityBuffer 초기화 과정 리뷰
2. Nanite 2/5 : TwoPassOcclusionCulling 의 전체 레이아웃을 확인하고 MainPass 의 노드 및 클러스터 컬링 리뷰
3. Nanite 3/5 : SW, HW 레스터라이저와 PostPass 리뷰
4. Nanite 4/5 : Visibility Buffer 로 부터 Depth/Stencil 텍스쳐를 생성하는 부분 리뷰
5. Nanite 5/5 : Visibility Buffer 로 부터 G-Buffer 생성하는 MaterialPass 리뷰
3. 내용
3.1. TwoPassOcclusionCulling 의 컬링 파트
3.2. FRenderer 생성 및 InitArgs 코드 분석
1. TwoPassOcclusionCulling 과 Visibility Buffer Rendering 을 위해 필요한 정보를 담고 있는 FRenderer 를 생성합니다.
2. GPU 에서 사용할 수 있도록 렌더링 관련 비트 플래그를 설정합니다.
3. PageConstants.X 에는 InstanceSceneDataSOAStride 가 들어가는데, 실제 이 값을 사용하는 곳이 없기 때문에 더 깊게 보지 않겠습니다. PageConstants.Y 에는 MaxStreamingPages 가 들어갑니다. 이 값은 렌더링에 필요한 Cluster 를 실시간으로 스트리밍 할 때 사용할 최대 페이지 수로 보입니다.
4. QueueState 버퍼를 생성합니다. QueueState 는 FQueueState 구조체로 쉐이더에 선언 되어있습니다. 멤버로 uint TotalClusters, FQueuePassState PassState[2] 가 있습니다. PassState 는 2개의 요소를 가진 배열인데, 0번 인덱스에는 MainPass, 1번 인덱스에는 PostPass 에 대한 정보가 기록됩니다. 이 정보는 Node 와 Cluster 를 특정 버퍼에 기록하고 읽을 버퍼의 Offset 정보가 있습니다. QueueState 는 Node 와 Cluster 의 기록/읽기 위치에 대한 정보를 가지고 있기 때문에 상당히 중요한 데이터 입니다. 추가로 MainPass, PostPass 용어는 TwoPassOcclusionCulling 의 첫번째, 두번째 패스를 말합니다.
5. VisibleClustersSWHW 는 Culling 과정 이후 Visible Cluster 를 기록하는 버퍼입니다. FVisibleCluster 를 Packing 하여 저장 합니다. FVisibleCluster 에는 ViewId, InstanceId, ClusterIndex 등과 같이 Cluster 에 대한 정보를 갖고 있습니다. VisibleClustersSWHW 에서 SW 는 Software rasterize, HW 는 Hardware rasterize 를 의미합니다. SW 로 그려질 VisibleCluster 는 VisibleClustersSWHW 의 Offset 0 에서 부터 차례로 기록되며, HW 로 그려질 VisibleCluster 는 VisibleClustersSWHW 의 맨 뒤에서부터 역으로 기록되며 자라납니다.
6. MainRasterizeArgsSWHW 는 Rasterize 에 사용할 Indirect draw argument 정보를 담습니다. NANITE_RASTERIZER_ARG_COUNT(8) 인데, SW 를 위해서 3개를 사용하고 1개는 패딩, HW 를 위해서 4~7 인덱스를 사용합니다.
7. SafeMainRasterizeArgsSWHW 는 생성한 SW/HW Rasterize Indirect draw argument 정보가 허용 범위를 넘어서지 않도록 처리된 결과를 저장하는 버퍼입니다. 추후에 쉐이더의 CalculateSafeRasterizerArgs 에서 생성됩니다. 이 글의 가장 마지막에서 볼 것입니다.
8. 현재는 TwoPassOcclusionCulling 을 사용하기 때문에 조건문 내에 무조건 들어옵니다. PostRasterizeArgsSWHW 와 SafePostRasterzeArgsSWHW 는 7에서 Main 과 동일한 이유로 생성된 버퍼입니다. OccludedInstances 는 HZB 테스트에서 Occluded 된 경우 ViewId 와 InstanceId 를 기록하는데 사용됩니다. OccludedInstancesArgs[0] 에는 Occluded 된 인스턴스를 64 개의 단위로 그룹을 만든 경우 총 몇개의 그룹인지? OccludedInstancesArgs[3] 에는 Occluded 된 총 인스턴스 수가 기록됩니다. 이렇게 64개의 그룹으로 묶는 이유는 OccludedInstance 는 PostPass 의 InstanceCull 과정에서 한번 더 Visibility 검사를 수행하는데, 이 때 쉐이더의 thread 가 WorkGroup 당 64 개 이기 때문입니다. 그리고 64 는 한 개의 Wavefront 가 동시에 돌릴 수 있는 thread 의 최대 개수입니다.
9. ClusterCountSWHW 도 CalculateSafeRasterizerArgs 과정에서 채워지며, NumClustersSW, NumClustersHW 정보가 각각 기록됩니다.
10. 화면에 렌더링 되어야 하는데 없는 클러스터 데이터를 로드하기 위한 요청을 담을 버퍼이며, GPU 측 RequestPageRange 함수에서 채워집니다.

이제 FRenderer 를 만들고 나면 FRenderer 의 멤버함수인 DrawGeometry 를 호출해서 이 함수 내에서 모든 TwoPassOcclusionCulling 작업이 징해되도록 합니다. DrawGeometry 내부로 들어가봅시다.
1. Nanite View 버퍼를 만들어 GPU 에 전달할 준비를 합니다. Nanite 는 여러 View 에 대해서 동시에 렌더링 가능합니다.
2. OptionalInstanceDraws 를 사용하지 않는다고 가정하므로, NumInstancePreCull 에는 GPUScene 에 할당된 InstanceId 수를 저장합니다.
3. CullingParameters 에 Culling 에 필요한 데이터를 채웁니다. NaniteView 정보와 PrevHZB, MaxCandidateClusters, MaxVisibleClusters, RenderFlags 등등 입니다. 여기서 주목할 점은 MainPass 에서는 PrevHZB 가 들어가며, PostPass 에서는 MainPass 를 통해 Rasterize 된 DepthBuffer 기준으로 생성된 HZB 가 들어간다는 점입니다. 나머지는 Culling 과정을 수행할 때 차차 알아봅시다.
4. 그림1 에서 FRenderer 를 만들 때 생성한 버퍼들을 초기화 합니다. Node 와 Cluster 의 읽기/쓰기 Offset 을 담는 중요한 버퍼인 QueueState 와 Main/PostRasterizeArgsSWHW, OccludedInstancesArgs 등등 이 보입니다.
5. Compute Shader 를 수행하여 초기화를 시작합니다.

계속해서 FInitArgs_CS 쉐이더 코드를 확인해봅시다.
1. ComputeShader 에서는 InitArgs 함수에 진입하였습니다. 우리는 Mesh or Primitive Shader 를 사용하지 않는다고 가정하기 때문에 GetHWClusterCounterIndex 는 5 를 리턴합니다. 이 인덱스 는 MainPost/RasterizeArgsSWHW 의 HWClusterCount 의 초기화에 사용됩니다.
2. QueueState 에 Offset 정보들을 0 으로 초기화 합니다.
3. DrawnClusterCounts 에는 지금까지 렌더링된 Cluster 수를 저장합니다. 이번 예제에서는 이 데이터는 사용하지 않습니다. WriteRasterizerArgsSWHW 함수를 호출해서 MainPassRasterizeArgsSWHW 를 초기화 합니다. SW, HW 클러스터를 모두 0으로 초기화 해줍니다.
4. TwoPassOcclusionCulling 을 사용하기 때문에 OCCLUSION_CULLING 은 1 입니다. 먼저 OccludedInstancesArgs 를 초기화 합니다. 그리고 WriteRasterizerArgsSWHW 로 PostPassRasterizeArgsSWHW 를 초기화 합니다. SW, HW 클러스터를 모두 0으로 초기화 해줍니다.
5. DRAW_PASS_INDEX 는 여기서는 항상 0 입니다.

InitArgs 이후에 바로 MainPass Culling 코드가 등장합니다. 이 MainPass 는 PostPass 와 거의 동일한 코드를 사용하기 때문에 Main/Post Culling 패스는 같이 볼 수 있습니다.
3.3. Main/Post Culling 전체 코드 레이아웃
먼저 MainPass Culling 의 CPU 측 코드를 확인해봅시다.
1. MainAndPostNodesAndClusterBatchesBuffer 를 생성합니다. 이 버퍼는 명세가 바뀌지 않는 이상 한번 만들어두고 계속 재활용 합니다. 버퍼의 총 크기는 4 byte * (MaxClusterBatches * 2 + MaxNodes * (2 + 3)) 크기로 생성합니다.
- 각 요소를 분석해보면, MaxClusterBatches * 2 는 ClusterBatch 에 클러스터의 개수를 기록하기 위한 버퍼를 위한 공간입니다. * 2 인 이유는 Main/Post 모두에 사용하기 때문입니다.
- MaxNodes * (2 + 3) 는 MainPass 에서 Node 저장시에는 uint 2개, Post 에서는 uint 3개를 사용하기 때문입니다.
- (그림11 버퍼 레이아웃 그림 참고)
2. MainAndPostCandididateClustersBuffer 를 생성합니다. 이 버퍼에는 FVisibleCluster 를 패킹해서 저장합니다. 이 때 패킹된 VisibleCluster 의 크기는 8 입니다(GetCandidateClusterSize() 함수 참고). 그래서 GetMaxCandidateClusters() * 2 * 4 가 됩니다. MainPass 의 CandidateCluster 의 경우 인덱스 0 부터, PostPass 의 경우는 뒤에서 부터 인덱스가 자라납니다.
3. Nanite 의 핵심 기능에 집중하기 위해서 Nanite 테셀레이션 기능은 이번 리뷰에서는 제외하고 진행합니다. AddPass_PrimitiveFilter 함수는 추가로 필터링 할 프리미티브들을 등록할 버퍼를 생성합니다만 중요한 내용은 아니므로 넘어가겠습니다.
4. AddPass_InstanceHierarchyAndClusterCull 에서는 드디어 MainPass 를 진행합니다.
5. 4번 과정에서 살아남은 클러스터를 기반으로 레스터라이즈를 진행합니다.
6. TwoPassOcclusionCulling 을 진행하고 있기 때문에 조건문 안으로 진입합니다.
7. MainPass 에서 레스터라이즈 한 결과로 생성된 DepthBuffer 를 사용하여 HZB 를 생성합니다. (MainPass 에서는 이전 프레임의 HZB 를 기준으로 컬링 후 레스터라이즈 진행)
8. 새로 생성한 이번 프레임 기준 HZB 를 사용하여 컬링을 수행합니다. 그리고 컬링 후 살아남은 클러스터에 레지스터라이즈를 진행합니다.
9. NANITE_RENDER_FLAG_HAS_PREV_DRAW_DATA 관련 내용은 보지 않을 것이기 때문에 무시하며, DrawPassIndex 는 항상 0으로 둡니다.

3.3.1. AddPassInitNodesAndClusterBatchesUAV
그럼 이제 Main/Post Culling 의 전체 코드 레이아웃에서 본 코드들의 세부사항을 뜯어보도록 합시다.
1. 먼저 AddPassInitNodesAndClusterBatchesUAV 함수로 진입합니다. 이 함수는 MainAndPostNodesAndClusterBatches 버퍼 생성 시 딱 한번 실행됩니다.
2. OutMainAndPostNodesAndClusterBatches 에 생성한 버퍼를 바인딩하고 MaxCandidateClusters 와 MaxNodes 수를 설정하고 Compute Shader 를 실행합니다. 4번 항목에서 볼 InitCandidateNodes 를 사용하여 Node 관련 내용을 초기화 합니다. GetGroupCountWrapped 를 사용하여 MaxNodes 가 64 개당 1개의 WorkGroup 으로 묶일 수 있도록 WorkGroup 을 조정하여 실행합니다.
3. 이전과 같은 데이터를 바인딩하고 Compute Shader 를 실행합니다. 이번에는 12번 항목에서 볼 InitClusterBatches 를 실행하여 Cluster 관련 내용을 초기화 합니다. 마찬가지로 WorkGroup 이 64 개의 Thread 를 가질 수 있도록 GetGroupCountWrapped 를 사용합니다.
4. InitCandidateNodes 의 Compute shader 는 WorkGroup 당 64 개의 thread 를 다룹니다.
5. Shader 실행시 전달받은 데이터를 GetUnWrappedDispatchThreadId 함수에 넘겨서 사용하여 Node 인덱스로 변환합니다. 이 인덱스는 0 ~ (MaxNodes-1) 입니다. 내부에서는 ClearCandidateNode 를 두 번 호출하는데 각각은 Main/Post 패스에 대해서 호출하는 것 입니다.
6. ClearCandidateNode 내부 구현도 한번 봅시다.
7. StoreCandidateNodeData 함수를 호출하여 MainAndPostNodesAndClusterBatches 버퍼의 NodeIndex 위치를 0xFFFFFFFF 로 초기화 합니다. 계속해서 내부로 들어가봅시다.
8. StoreCandidateNodeData 함수 내부에서 인덱스 계산도 확인해봅시다.
9. Main/Post 여부에 따라서 Node 정보를 저장할 Offset을 만듭니다. 그리고 MainAndPostNodesAndClusterBatches 에 전달 받은 초기화 값을 저장합니다. 이 때 Main 의 경우 8 byte, Post 의 경우 12 byte 입니다. Main의 경우 uint 2 개, Post의 경우 uint 3 개를 사용하기 때문입니다.
10. Shader 에 정의된 CandidateNode 와 CandidateCluster 의 크기입니다. 바로 전에 확인 한 것 처럼 노드의 경우 Main 은 uint 2 개, Post 는 uint 3 개 크기인 것을 알 수 있습니다. 그리고 CandidateClusterSize 는 8 byte 인 것을 확인할 수 있습니다.
11. 여기서는 9번 과정에서 Offset 을 만들 때 사용한 함수들에 대해서 알아봅시다. 그때 사용한 함수는GetNodesAndBatchesOffset(bPostPass) + GetCandidateNodesOffset() 입니다. GetNodesAndBatchesOffset 는 Node 를 저장할 오프셋을 얻어오는 함수입니다. MainPass 의 Node 는 바로 0 Offset 에 저장되지 않습니다. MaxCandidateClusterBatch 다음 위치에서 저장을 시작합니다. PostPass 의 경우는 (GetCandidateNodesOffset() + MaxNodes * GetCandidateNodeSize(false)) + GetCandidateNodesOffset() 위치에서 저장을 시작합니다. PostPass 에서는 MainPass 에서 저장된 CandidateCluster 와 CandidateNode 의 저장 공간을 고려하고 그 뒤에 PostPass 에서 사용할CandidateClusterBatch Offset 을 두기 위해서 이렇게 합니다. 이 부분은 앞으로 코드를 보며 종종 나오기 때문에 여기서 확실히 정리하면 좋습니다. 앞서 설명한 버퍼의 전체 레이아웃은 그림11 에 추가했습니다.
12. 다음은 InitClusterBatches Compute Shader 를 수행하여 Cluster 를 저장할 공간을 초기화 합니다.
13. Node 와 마찬가지로 GetUnWrappedDispatchThreadId 함수에 WorkGroup 과 ThreadId 를 전달하여 Cluster 의 인덱스로 변환합니다. 그리고 ClearClusterBatch 함수를 Main/Post 함수에 대해서 각각 호출합니다.
14. ClearClusterBatch 함수 내부로 들어가서 Offset 계산을 봅시다. 이런 과정을 한번 해두는 것이 MainAndPostNodesAndClusterBatches 의 메모리 레이아웃을 이해하는데 도움이 될 것입니다.
15. Offset 생성을 먼저 확인해보면, GetClusterBatchesOffset 은 11번 코드를 보면 0이라는 것을 알 수 있습니다. 왜냐하면 Main/Post 의 ClusterBatch 정보가 Node 정보보다 앞쪽에 배치되기 때문입니다. GetNodesAndBatchesOffset 은 바로 위에서 확인했기 때문에 추가 설명하지 않겠습니다. 이렇게 ClusterBatch 정보도 ClusterIndex 별로 모두 초기화 하였습니다.

3.3.2. AddPass_InstanceHierarchyAndClusterCull 전체 레이아웃
이제 컬링을 수행할 준비를 마쳤습니다. 컬링 과정도 여러 단계로 쪼개져 있기 때문에 전체 레이아웃을 먼저 파악해봅시다. 이 코드의 내용은 Nanite(1/5) 의 그림1의 InstanceCulling, Persistent Hierarchy/Cluster Culling 과 컬링 결과를 기반으로 레스터라이즈를 수행할 Indirect command argument 를 생성합니다.
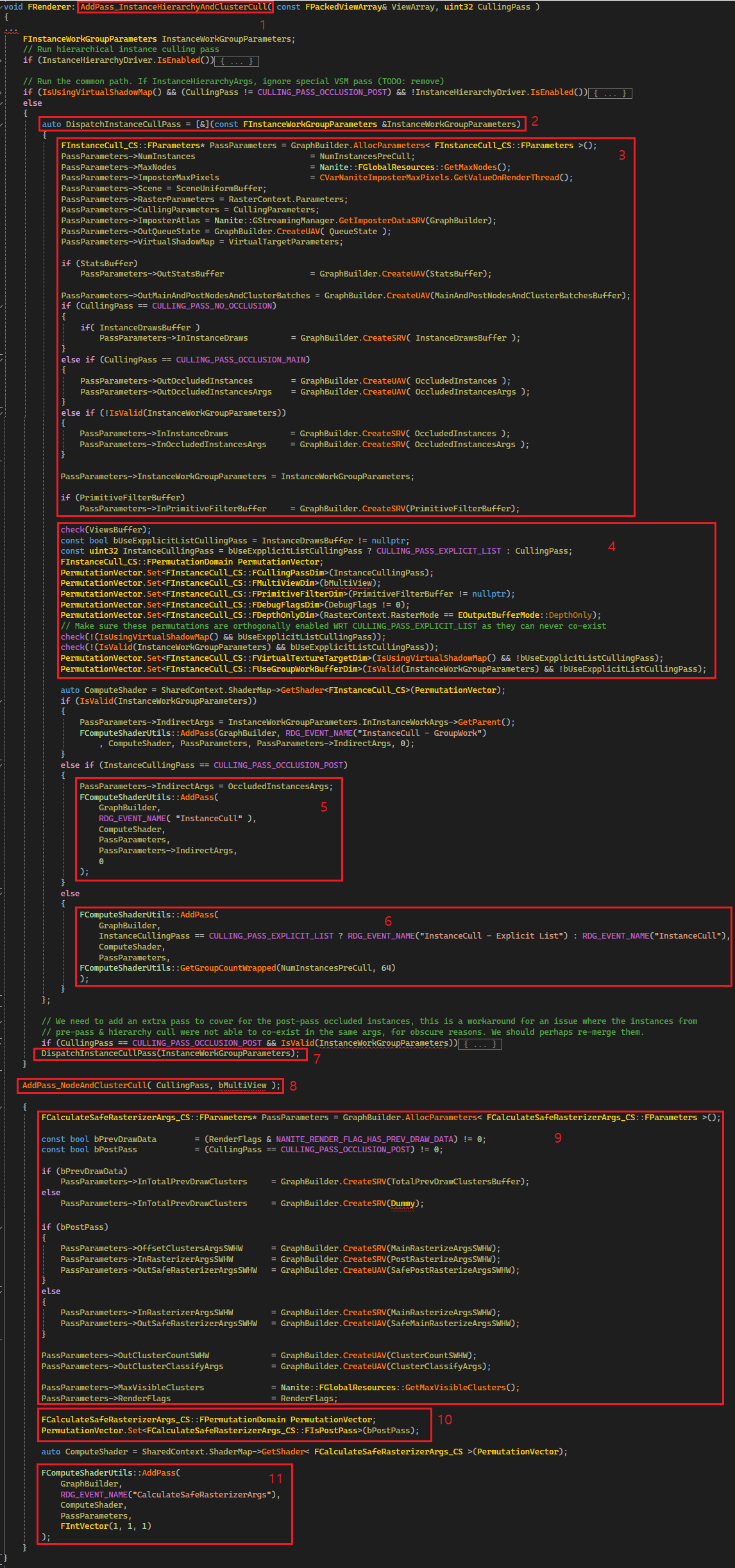
1. AddPass_InstanceHierarchyAndClusterCull 함수로 진입합니다.
2. DispatchInstanceCullPass 라는 람다함수를 만드는데 여기서 InstanceCulling 을 수행합니다. 함수 내부를 확인해봅시다.
3. FInstanceCull_CS::FParameter 에 쉐이더에서 필요한 정보를 채웁니다. 총 인스턴스 수, 그리고 OccludedInstances, OccludedInstancesArgs 그리고 기타 정보를 채웁니다. 컬링 과정에서 이전 프레임의 HZB 도 들어가는데, CullingParameters 에 미리 바인딩 해뒀기 때문에 해당 부분은 보이지 않습니다. 참고로, OccludedInstances 에는 ViewId, InstanceId 가 기록되며, OccludedInstancesArgs 에는 [0] 에는 64 개를 한 그룹으로 했을 때 그룹의 총 개수, [3] 에는 Occluded 된 인스턴수가 기록됩니다. 이 때, Occluded 된 정보들은 이전 프레임의 HZB 를 기반으로 결정된 것이기 때문에 현재 프레임을 기반으로 HZB 가 만들어지면 한번 더 체크합니다. (이전 프레임에 없었다가 이번 프레임에 새로 등장한 인스턴스를 위해서)
4. 필요한 Shader permutation 정보를 설정합니다.
5. PostPass 의 경우 OccludedInstanceArgs 를 Indirect command argument 로 사용하여 InstanceCulling 을 수행합니다. 이전 프레임에 없었다가 새로 보이는 인스턴스 재확인 과정이며, 그림1의 PostPass 의 InstanceCulling 에 해당합니다.
6. MainPass 의 InstanceCulling 입니다. 여기서는 현재 할당되어있는 인스턴스 개수를 64 개의 그룹으로 묶어서 WorkGroup 을 생성합니다. 아마도 Compute Shader 에서는 64 개의 thread 가 culling 을 위해 배칭될 것으로 예상됩니다.
7. 바로 위에서 확인한 람다함수를 실제로 호출합니다. 이 때 전달된 InstanceWorkGroupParameters 는 기본 설정에서는 유효하지 않기 때문에 관련해서 추적하지는 않을 것입니다.
8. AddPass_NodeAndClusterCull 함수를 호출합니다. 이 함수가 바로 Nanite(1/5) 의 그림1 의 Persistent Hierarchy/Cluster culling 입니다. 여기까지 오면 컬링에서 살아남은 Instance 의 Root node 정보들이 수집한 상태입니다. 그리고 해당 Node 를 순회하여 Visible Cluster 를 선별합니다. Nanite 코드 중에 이 부분이 가장 재미있던 것 같습니다. 해당 부분은 Compute Shader 를 thread pool 처럼 활용하여 노드 순회와 클러스터 컬링을 순회합니다.
9. 컬링을 마치고 얻어진 Cluster 들을 레스터라이즈 시켜야 하기 때문에 레지스터라이즈를 위해 필요한 버퍼들을 설정합니다.
10. Main/Post 패스 여부에 대한 Permutation 을 설정합니다.
11. CalculateSafeRasterizerArgs ComputeShader 를 실행합니다.
3.3.2.1. FInstanceCull_CS (MainPass)
InstanceCulling 의 Compute Shader 에 바로 진입해봅시다.
1. 64 개의 인스턴스를 배치로 수행합니다.
2. GroupId 와 ThreadIndex 로 부터 DispatchIndex 를 얻어옵니다. 이 값은 “0 ~ 인스턴스 개수” 범위이며, InstanceId 와 매칭됩니다.
3. Main/Post Pass 여부 플래그를 생성합니다.
4. MainPass 의 경우 전체 인스턴스 개수인 NumInstances 가 컬링 테스트 할 인스턴스 수가 되며, PostPass 에서는 Occluded 된 인스턴스를 재 확인하는 과정이기 때문에 OccludedInstancesArgs[3] 에서 컬링 테스트 할 인스턴스 수를 얻습니다. 이전에 이야기 한 것 처럼 OccludedInstancesArgs[3] 에는 총 Occluded 된 인스턴스의 수가 들어갑니다.
5. 처리하려는 InstanceId 가 최대 범위를 넘어가는지 확인합니다.
6. MainPass 의 경우는 DispatchIndex 가 바로 InstanceId 입니다. 하지만 Occluded 된 인스턴스의 경우는 Id 를 OccludedInstances 버퍼에서 얻어와야 할 것입니다. InInstanceDraws 버퍼가 PostPass 에서는 바로 OccludedInstances 입니다.
7. LoadInstancePrimitiveIdAndFlags 함수는 InstanceId 로 부터 PrimitiveId 와 InstanceFlags 정보를 얻어옵니다. 바로 옆에 있는 초록색 네모에 함수 내부가 있습니다.
8. InstanceId 로 부터 Instance 정보를 얻어옵니다. FInstanceSceneData 에 대한 자세한 내용은 레퍼런스5 에 있습니다.
9. FPrimitiveSeneData 를 얻어옵니다. 이것에 대한 자세한 내용 또한 레퍼런스6 에 있습니다.
10. Filtering 할 프리미티브 인지 확인하고 그렇다면 바로 컬링 해버립니다. PostPass 에서 재확인 할 필요도 없기 때문에 더이상의 처리를 하지 않습니다.
11. IsPrimitiveShown 함수에서는 PrimitiveData.Flag 와 RenderFlag 를 사용하여 프리미티브가 Visibility 를 체크합니다. 그림8 에서 내부를 확인해봅시다.
12. 현재 인스턴스를 각각의 View 에 대해서 테스트합니다. 우리는 일단 View 가 1개로 가정하고 계속 코드를 봅시다.
13. FInstanceDynamicData 를 만듭니다. 이 것은 현재 처리 중인 인스턴스를 현재 View 에 맞게 Transform 시킨 정보를 캐싱 합니다. 코드 바로 우측 상단 초록색 네모에 함수의 내부가 있습니다.
14. HZB 에 컬링을 수행하기 위해서 FBoxCull 객체를 생성합니다. View 와 BoundBox 와 Location 정보 등이 설정됩니다. PostPass 의 경우는 MainPass 에서 이미 수행했고 변하지 않는 컬링 정보인 FrustumCull, GlobalClipPlaneCull 을 수행하지 않도록 설정합니다.
15. DistanceCulling 을 수행합니다. WPO 를 사용하고 있다면 bHasMoved 를 true 로 설정합니다. (GetGPUSceneFrameNumber() == InstanceData.LastUpdateSceneFrameNumber) 이 경우도 bHasMoved 로 설정되는데, GPUScene 에 인스턴스 데이터가 업데이트 된 경우에 true 가 되며 이때 이동했다고 판정합니다. 그림9 에서 함수 내부를 확인해봅시다.
16. GlobalClipPlaneCull 을 수행합니다. GlobalClipPlaneCull 의 세부사항은 분량 조절을 위해 여기서 다루지 않겠습니다.
17. 아직도 Visible 상태라면 FrustumCull 과 HZB Culling 을 수행합니다. 이 부분 또한 분량 조절을 위해 여기서 다루지 않겠습니다.
18. MainPass 의 경우 Occluded 되었다면, WriteOccludedInstance 함수를 사용하여 해당 인스턴스가 Occluded 되었다고 설정합니다. 그리고 PostPass 에서 Occluded 인스턴스에 대해서 현재 프레임의 HZB 를 사용하여 다시 컬링을 수행할 것입니다.
19. 이 부분은 임포스터로 렌더링할지 여부를 결정하는 부분입니다. 임포스터로 렌더링 할 정도로 크기가 작다면, DrawImposter 로 임포스터로 렌더링 될 수 있도록하고 Visible 을 false 로 설정하는 것을 볼 수 있습니다. 임포스터의 렌더링 과정까지 보면 코드를 볼 범위가 너무 커질 것 같아서 생략합니다.
20. 인스턴스가 Visible 이고, Occluded 되지도 않았다면 QueueState 에 인스턴스의 Root Node 를 기록합니다.
21. 각 스레드의 VGPR 변수 NodeOffset 에 Node 를 기록할 Offset 을 담습니다. QueueState 의 MainPass 는 QueueStateIndex 0 번 인덱스, PostPass 는 1 번 인덱스에 Node 읽기/쓰기에 대한 Offset 정보 및 총 Node 수를 담습니다. WaveInterlockedAddScalar, WaveInterlockedAddScalar_ 두 함수도 앞으로 자주보게 될 함수입니다. 이 함수는 Wave intrinsic 을 사용하여 64 개의 thread가 각자의 위치의 NodeOffset 를 Atomic 연산 1회만으로 동시에 받을 수 있게 해줍니다. 각각의 Wave 함수가 하는 일을 알아봅시다.
- WaveInterlockedAddScalar(NodeCount, 1) 는 Active thread 의 개수 당 1 씩 NodeCount 를 증가시킵니다. 즉 Active thread 가 64 개 중 10 개라면 NodeCount 는 10이 증가합니다.
- WaveInterlockedAddScalar_(NodeWriteOffset, 1, NodeOffset) 은 Active thread 의 개수 당 1 씩 NodeWriteOffset 을 증가 시킵니다. 그리고 NodeWriteOffset + Active thread index(64 개 범위에서) 를 더해서 돌려줍니다. 만약 NodeWriteOffset 이 15 였고, Active thread 가 10 였다고 합시다. 그러면 각각의 Active thread 0~9 는 NodeOffset 에 15, 16, 17…24 를 담아서 돌려받습니다.
- Wave intrinsic 에 대한 자세한 내용은 레퍼런스7 링크에서 알아 볼 수 있습니다.
22. 현재 처리중인 Node 가 최대 Node 개수를 초과하지 않았는지 확인합니다. 그렇지 않다면 FCandidateNode 객체에 인스턴스 정보를 담습니다. 그리고 StoreCandidateNode 함수를 사용하여 MainAndPostNodesAndClusterBatches 버퍼에 저장합니다. 그림10 에서 내부를 확인해봅시다.

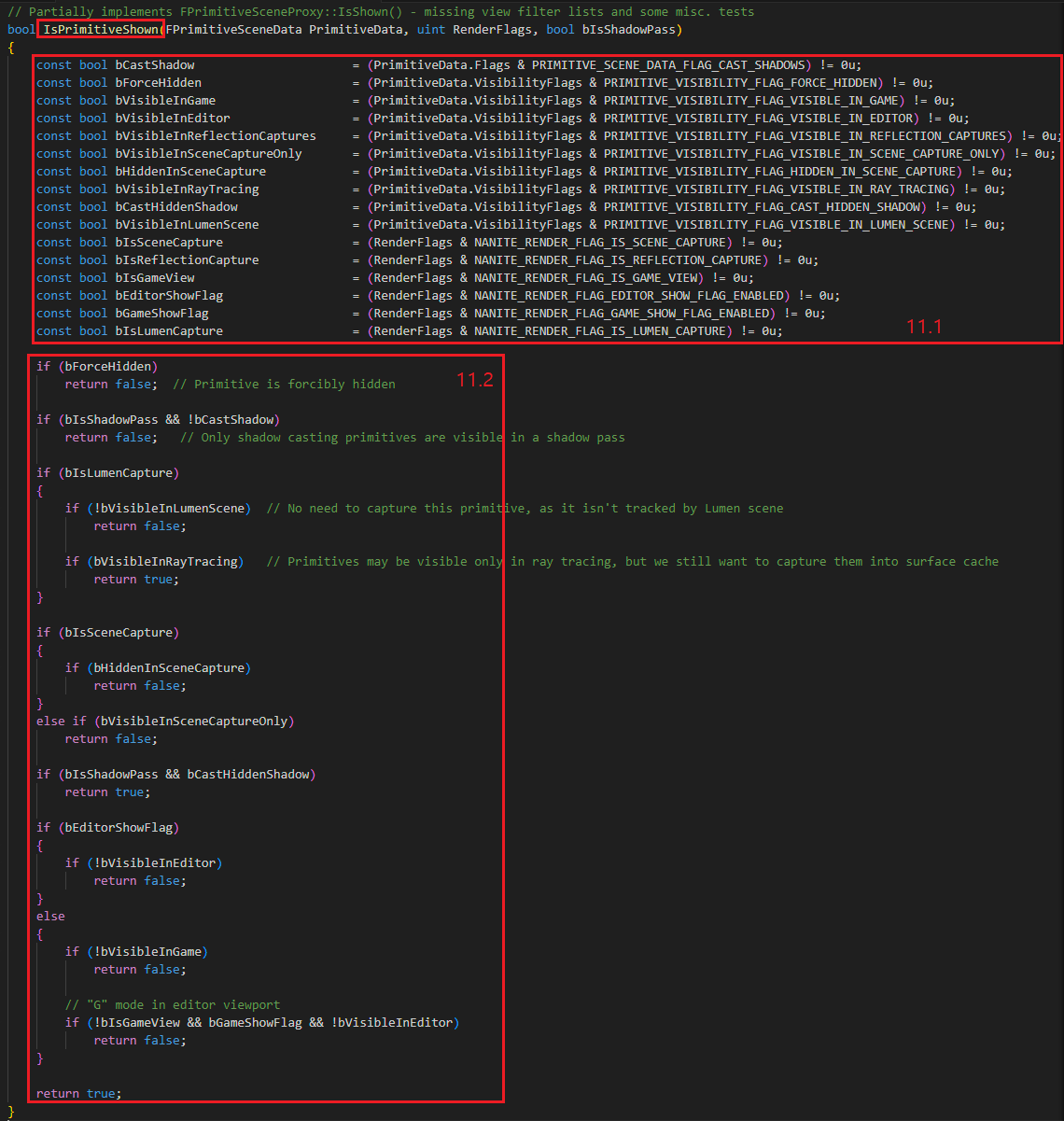
IsPrimitiveShown 함수 내부 입니다.
11.1. Flag 를 사용하여 bool 상태 변수를 생성합니다.
11.2. 생성한 bool 상태 변수를 기반으로 Visible 여부를 리턴합니다.
Distance 함수 내부를 확인해봅시다.
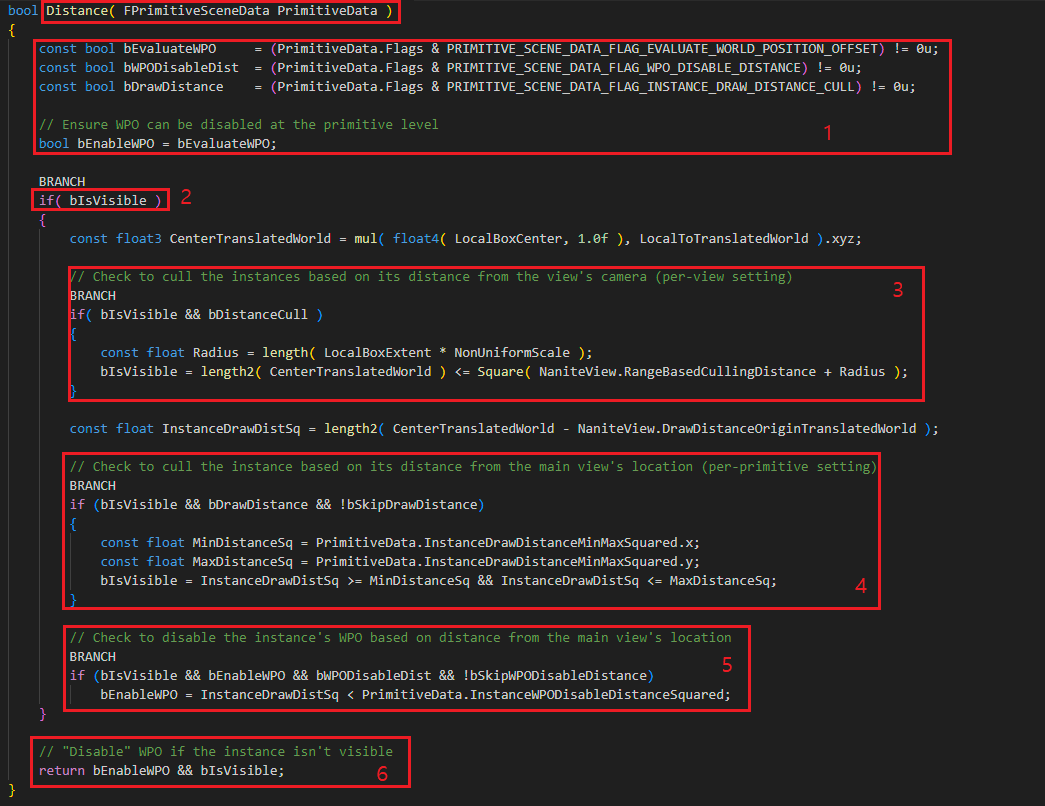
15.1. DistanceCull 의 내부로 들어가봅시다.
15.2. WPO 를 사용하는지? WPO 를 거리에 따라서 끄는 기능을 사용하는지? 거리에 따라 Draw 여부를 결정하는지? 에 대한 플래그를 확인합니다.
15.3. 현재 인스턴스가 Visible 이면 Distance Culling 을 수행합니다.
15.4. View 당 설정되는 값 기반으로 Camera(View) 에서 일정거리 이상 떨어진 인스턴스를 컬링합니다.
15.5. 인스턴스 당 설정되는 값 기반으로 Camera(View) 의 위치를 기반으로 인스턴스가 충분히 멀다면 컬링을 수행 합니다.
15.6. WPO Disable 기능을 사용하는 경우 충분히 거리가 멀다면 WPO 를 꺼줍니다.
15.7. 리턴값은 WPO 를 사용하고 Visible 이면 true 입니다. Invisible 이면 WPO 를 사용하지 않는 것으로 합니다.
StoreCandidateNode 함수의 내부를 확인해봅시다.
22.1. StoreCandidateNode 의 인덱스 계산을 한번 확인해봅시다. 여기서는 FCandidateNode 를 패킹하여 StoreCandidateNodeData 에 전달합니다.
22.2. GetNodesAndBatchesOffset 과 GetCandidateNodesOffset 함수를 사용하여 Main/Post 패스에 맞는 버퍼 Offset 을 저장합니다. MainAndPostNodesAndClusterBatches 버퍼에 Cluster 저장 공간을 사용하게 됩니다.
22.3. CandidateNode 의 인덱스 계산에 필요한 함수들입니다.


3.3.2.2. AddPass_NodeAndClusterCull (MainPass) 전체 레이아웃
이제 Nanite(1/5) 의 그림1 에 나온 Persistent Hierarchy/Cluster Culling 단계입니다. 이 과정 또한 여러 단계로 나뉘기 때문에 전체 레이아웃을 한번 확인해보고 세부 사항을 보도록 합시다.
1. 우리가 보는 코드는 NanitePersistentThreadsCulling 을 사용합니다. 이 Compute Shader 는 이름에서 알 수 있듯이 생성한 Thread 를 계속해서 유지한 채로 스레드 풀을 유지하면서 작업할 일감이 담긴 큐가 바닥날 때까지 계속 작업을 수행합니다.
2. AddPass_NodeAndClusterCull 함수 내부로 들어가봅시다.
3. 앞서 데이터를 채워넣었던 QueueState 와 MainAndPostNodesAndClusterBatchesBuffer 를 바인딩 합니다. MainPass 를 막 마친 상태라면 MainAndPostNodesAndClusterBatchesBuffer 에는 현재 Node 루트 정보만 담겨있을 것입니다. MainAndPostCandididateClusters 에는 PackedVisibleCluster 를 저장 할 버퍼로 Culling 을 모두 마친 Visible Cluster 가 저장됩니다.
4. 이번 패스에서 사용할 VisibleClustersArgsSWHW 를 바인딩하는데, MainPass 에서는 MainRasterizeArgsSWHW 를 바인딩 합니다. 이 버퍼는 NANITE_RASTERIZER_ARG_COUNT(8) 크기로 만들었었습니다. SW 를 위해서 3 개를 사용하고 1개는 패딩, HW 를 위해서 4~7 인덱스를 사용합니다.
- RasterizerArgsSWHW[0~3] = (NumClustersSW, 1, 1, 0)
- RasterizerArgsSWHW[4~7] = (Max Cluster Triangle (128개), NumClustersHW, 0, 0) // Mesh or Primitive shader 가 아닌 경우
5. 계속해서 PostPass 의 경우 VisibleClustersArgsSWHW 바인딩에 관한 코드입니다. 여기서는 바인딩 하는 버퍼를 MainPass 와는 조금 다르게 합니다. OffsetClustersArgsSWHW 에 MainRasterizeArgsSWHW 를 넣고, VisibleClustersArgsSWHW 에는 PostRasterizeArgsSWHW 를 바인딩 합니다. PostPass 에서는 ClusterStore 를 수행할 때, MainPass 의 기록 뒤쪽에 붙여서 기록하기 위해서 MainRasterizeArgsSWHW 에서 사용한 SW, HW Cluster 의 수를 활용합니다. 그래서 OffsetClustersArgsSWHW 에 MainRasterizeArgsSWHW 를 바인딩 합니다.
6. VisibleClustersSWHW 를 바인딩합니다. 이 버퍼는 컬링 과정을 마치고 렌더링 할 클러스터를 담습니다. FVisibleCluster 를 PackedVisibleCluster 로 만들어서 저장하며, VSM 이 아닌 경우 8 byte, VSM 은 12 byte 입니다. FVisibleClusters 의 주요 정보는 ViewId, InstanceId, ClusterIndex 입니다. SW 는 인덱스 0 부터 자라나며, HW FVisibleCluster 는 인덱스가 맨 마지막 인덱스에서 거꾸로 자라납니다. GPU 에서 클러스터 데이터를 스트리밍 요청하기 위한 StreamingRequests 버퍼도 여기서 바인딩 합니다.
7. NodeAndClusterCull 을 하기 위해 필요한 Permutation 정보를 설정합니다.
8. NodeAndClusterCull 을 수행합니다. 주목할 부분은 GRHIPersistentThreadGroupCount 인데, DX12 에서는 1440 입니다. 이 값은 플랫폼 마다 조금씩 다르며, 1440 개의 WorkGroup 이 ThreadPool 처럼 동작하게 됩니다.
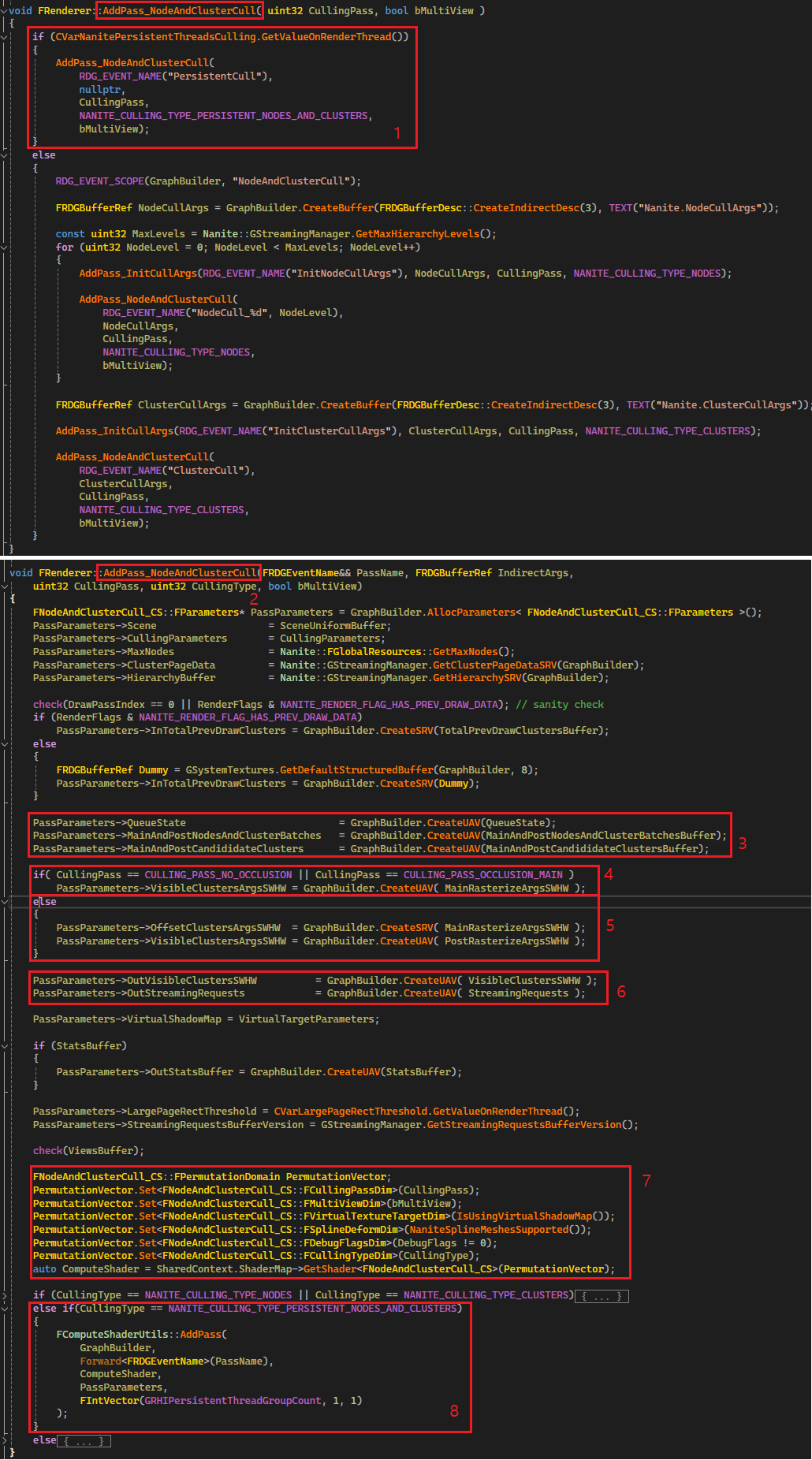
이제 Persistent Hierarchy / Cluster Culling 의 CPU 측 코드 확인을 마쳤습니다. 계속해서 Compute Shader 쪽의 전체 레이아웃을 확인해봅시다.
1. NodeAndClusterCull 은 WorkGroup 당 NANITE_PERSISTENT_CLUSTER_CULLING_GROUP_SIZE(64) 개의 thread 를 수행 합니다. GroupIndex : SV_GroupIndex 는 64개의 thread 에 0~63 의 인덱스를 각각 전달합니다.
2. 우리가 볼 Culling 방식은 PersistentNodeAndClusterCull 입니다. 해당 함수로 들어갑니다. SV_GroupIndex 인 GroupIndex 변수도 같이 전달합니다.
3. PersistentNodeAndClusterCull 내부로 진입합니다.
4. 초기화 값을 설정합니다.
- bProcessNodes 는 Node 에 대한 처리를 진행 중인지 여부입니다. 여기서는 처리할 노드가 있다면 Node 를 먼저 처리하기 때문에 초기값은 true 로 설정됩니다.
- NodeBatchReadyOffset 은 NANITE_MAX_BVH_NODES_PER_GROUP 으로 초기화 되는데 이 값은 16 입니다.
- NodeBatchStartIndex 는 0으로 초기화 되는데, 추후 QueueState 로 부터 처리할 Node 정보를 가져올 때 현재 WorkGroup 이 읽어야 할 NodeReadOffset 를 담습니다. (WorkGroup 내 thread 는 동일한 값을 가짐)
- ClusterBatchStartIndex 는 추후 Node 처리가 완료 되고 클러스터를 처리할 때 사용합니다. 이 값은 QueueState 로 부터 처리할 Cluster 정보를 가져올 때 현재 WorkGroup 이 읽어야 할 ClusterBatchReadOffset 을 담는데 사용합니다. (WorkGroup 내 thread 는 동일한 값을 가짐)
5. 이제 Node Hierarchy / Cluster Culling 이 마칠 때 까지 이 반복문을 계속 돕니다.
6. WorkGroup 내의 첫 번째 thread 가 대표로 GroupNumCandidateNodes 와 GroupNodeMask 를 0 으로 초기화 합니다. 그리고 OnPreProcessNodeBatch 함수를 통해 GroupOccludedBitmask[0~63] 을 0으로 초기화 합니다. 이 두가지 변수는 모두 group shared 타입(WorkGroup 내에서 공유) 입니다.
- GroupNumCandidateNodes 는 현재 WorkGroup 에서 노드 순회 중 추가로 순회해야 하는 Child Node 가 있는 경우 해당 Node 의 수를 저장합니다.
- GroupNodeMask 는 현재 WorkGroup 에서 LoadCandidateNodeDataToGroup 함수로 Node 정보를 로드를 성공하여 Node 순회를 진행할 수 있는 thread 정보를 비트 마스크로 마킹합니다. (1 << GroupIndex 방식)
7. 노드 처리를 위해서 조건문 안으로 진입합니다. NodeReadyMask 를 초기화 하는데 바로 전 6 에서 groupshared 변수 GroupNodeMask 를 현재 thread 에 VGPR 에 있는 NodeReadyMask 저장합니다. 아마도 이렇게 하는 것은 이후 Mask 연산에서 각 스레드가 자신의 VGPR 접근하는 것이 groupshared 인 L1 캐시에 접근하는 것보다 더 이득이 되기 때문이 아닐까 생각됩니다.
8. 아마도 처음 진입한다면 이 조건문 안으로 진입할 것입니다. 그리고 16 개의 Node 를 모두 처리하면 두번째 루프에서 또다시 여기에 진입합니다.
9. 조건문 내에서는 QueueState 로 부터 현재 WorkGroup 이 읽을 NodeReadOffset 을 가져와 GroupNodeBatchStartIndex 에 저장합니다. 물론 이 과정은 WorkGroup 당 한번만 실행하면 되기 때문에 WorkGroup 의 첫번째 thread 가 대표로 진행합니다.
10. NodeBatchReadyOffset 을 0으로 초기화 하여 WorkGroup 에서 처리한 노드의 개수를 카운팅 할 수 있게 준비합니다. 그리고 9에서 받아온 GroupNodeBatchStartIndex(현재 WorkGroup 읽어야 하는 NodeReadOffset) 을 VGPR 인 NodeBatchStartIndex 로 옮깁니다. 만약 NodeBatchStartIndex 가 Nanite 가 처리할 수 있는 Node 의 최대 수를 넘어갔다면 노드 처리를 중단하고 Cluster 처리를 시작합니다.
11. NodeIndex 는 현재 thread 가 처리해야 할 NodeReadOffset 입니다. NANITE_MAX_BVH_NODES_PER_GROUP 은 16 입니다. WorkGroup(64) 중 앞쪽 16 개의 경우 bNodeReady 를 true 로 설정합니다.
12. WorkGroup 의 앞쪽 16개에 대해서 LoadCandidateNodeDataToGroup 함수를 호출합니다. 이 함수는 Node 데이터가 정상인지 확인하고 정상인 경우 true 를 리턴합니다. 그리고 groupshared 인 변수 GroupNodeData[NANITE_MAX_BVH_NODES_PER_GROUPS] 에 Node 데이터를 저장해둡니다. 여기서 로드 된 데이터는 바로 InstanceCulling 때 저장한 PackedCandidateNode 입니다. LoadCandidateNodeDataToGroup 상세 내역은 그림14 에서 확인해봅시다.
13. 그리고 WorkGroup 의 앞쪽 16개 중 Node 데이터를 정상적으로 로드 가능했던 GroupIndex 는 GroupNodeMask 에 1 bit 를 마킹해 둡니다. 그리고 해당 마스크를 VGPR 변수인 NodeReadyMask 에 복사해줍니다.
14. NodeReadyMask 에 처리할 것이 있다면? 조건문 내부로 진입합니다. firstbitlow(~NodeReadyMask) 는 총 사용 가능한 Node 의 개수를 얻을 수 있습니다. 이것을 BatchSize 에 넣습니다. 모두 사용 가능하다면 NANITE_MAX_BVH_NODES_PER_GROUPS(16) 일 것 입니다.
15. ProcessNodeBatch 함수에서 Node 의 ChildNode 를 추가로 순회해야 할지 결정합니다. 그림15 에서 상세 내역을 확인해봅시다.
16. ProcessNodeBatch 를 실행한 thread 들은 내부 조건문으로 진입합니다. 그리고 처리 완료한 노드에 대한 정보를 Clear 시켜줍니다. 이전에 그림5 의 4 에서 InitCandidateNodes 함수를 볼 때 봤었기 때문에 넘어가겠습니다.
17. 처리 완료한 BatchSize 를 NodeBatchReadyOffset 에 더한 뒤 continue; 를 실행하여 다시 Node Batch 를 처리하도록
16 개의 노드가 모두 처리되었다면 9번으로 이동하여 QueueState 로 부터 또 다시 새로운 NodeReadOffset 를 얻어올 것입니다.
18. 만약 모든 Node 에 대한 처리가 완료되었다면, 이제 Cluster 를 처리합니다. ClusterBatchStartIndex 는 4 에서 처음에 0xFFFFFFFF 로 초기화되었기 때문에 조건문 내로 진입합니다.
19. WorkGroup 내의 첫 번째 thread 가 대표로 ClusterBatchReadOffset 을 얻어옵니다. 그리고 이것을 VGPR 인 ClusterBatchStartIndex 에 복사합니다.
20. 만약 처리할 Node 도 더 이상 없고, 최대 클러스터 배치 수를 넘어갔다면 더 이상 클러스터를 처리하지 않고 thread 를 종료합니다.
21. WorkGroup 내의 첫 번째 thread 가 대표로 현재 NodeCount 를 얻어옵니다. 그리고 LoadClusterBatch 함수로 ClusterBatch 의 개수를 얻습니다. 그림23 에서 다룰 것입니다.
22. VGPR 로 ClusterBatchReadySize 를 옮긴 후, 처리할 클러스터가 없다면 더 이상 클러스터를 처리하지 않고 thread 를 종료합니다.
23. 처리 할 클러스터가 있는 경우 조건문 내로 진입합니다. 그리고 ProcessClusterBatch 를 실행하여 Cluster 의 컬링을 수행합니다. 자세한 내용은 그림23 에서 다룰 것입니다.
24. 더 이상 처리할 Node 가 없다면 노드 처리를 비활성 하여 Cluster 만 처리하도록 합니다.

3.3.2.2.1. LoadCandidateNodeDataToGroup
1. LoadCandidateNodeDataToGroup 내부를 확인해봅시다.
2. LoadCandidateNodeData 함수를 사용하여 MainAndPostNodesAndClusterBatches 로 부터 NodeIndex 에 위치한 Node 데이터를 얻어옵니다.
2.1. GetNodesAndBatchesOffset 와 GetCandidateNodesOffset 을 사용하여 데이터를 로드할 Offset 을 얻어오고, Main/Post Pass 여부에 따라서 노드 데이터를 로드합니다. 이 부분은 그림5 의 11 에서 확인했기 때문에 자세히 다루지 않겠습니다.
3. 로드한 노드 데이터가 유효한지 확인하고 그렇다면 SetGroupNodeData 함수를 통해서 groupshared 변수인 GroupNodeData[0~15] 에 Node 데이터를 저장하며 이후 사용합니다.
3.1. Node 의 유효성 여부는 RawData 가 0xFFFFFFFF 인지 확인하는 것입니다. 이것은 그림5 의 7 에서 MainAndPostNodesAndClusterBatches 의 데이터를 초기화 할 때 ClearCandidateNode 함수를 호출하면 0xFFFFFFFF 로 설정하기 때문입니다. 만약 Node 데이터가 기록되지 않았다면 초기화 데이터가 그대로 남아있었을 겁니다.
3.2. groupshared 변수인 GroupnodeData[0~15] 와 데이터를 읽고/쓰는 인터페이스를 보여줍니다. GROUP_NODE_SIZE 는 Main 의 경우 uint2, Post 의 경우 uint3 입니다.
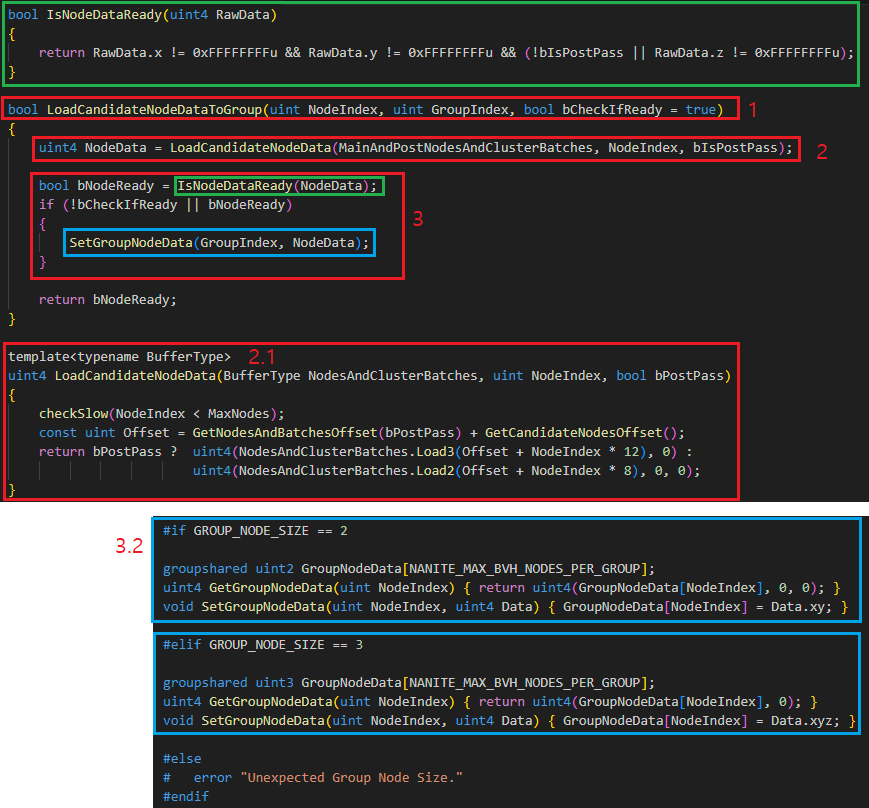
3.3.2.2.2. ProcessNodeBatch
ProcessNodeBatch 는 현재 Node 의 ChildNode 로 순회가 필요한지 확인하고 필요한 경우 순회합니다. 코드를 확인해봅시다.
1. ProcessNodeBatch 함수에 진입합니다. BatchSize 는 현재 WorkGroup 내에서 ProcessNodeBatch 를 수행하는 thread 수(대부분 16), GroupIndex 는 WorkGroup 내에서 현재 thread 의 인덱스(0~15), QueueStateIndex 는 0이면 MainPass, 1 이면 PostPass 의 의미입니다.
2. LocalNodeIndex, ChildIndex, FetchIndex 는 전달 받은 파라메터로 부터 생성됩니다. NANITE_MAX_BVH_NODE_FANOUT_BITS 는 2, NANITE_MAX_BVH_NODE_FANOUT_MASK 는 오른쪽에서 2개 비트를 1로 설정한 것입니다. 이 변수들이 어떤 값을 가질 지 WorkGroup 이 16 개라고 가정(출력 결과를 간단하게 하기 위해)하고 출력해봤습니다. 그림16 를 봐주세요. LocalNodeIndex 00, 01, 10, 11 와, ChildIndex 00, 01, 10, 11 의 조합으로 총 16 개의 조합이 나옵니다. 만약 WorkGroup 64 개라면 LocalNodeIndex 는 16 개, 그리고 4 개의 ChildIndex 조합으로 총 64 개의 thread 를 가득채워 작업을 진행할 수 있을 것입니다.
3. FNaniteTraversalCallback 객체를 생성하고, Init 함수를 호출합니다. 이 함수에서는 바로 전 과정 그림14 의 LoadCandidateNodeDataToGroup 에서 저장했던 groupshared 변수인 GroupNodeData 로 부터 NodeData 를 얻어옵니다. 그리고 NaniteView 와 InstanceData 정보를 준비해둡니다.
4. FHierarchyNodeSlice 는 현재 Node 의 Child 정보에 대한 Node 정보를 담고 있습니다. FHierarchyNodeSlice 정보는 GetHierarchyNodeSlice 함수를 통해 얻어옵니다. 이 때 전달되는 GetHierarchyNodeIndex() 은 InstanceData.NaniteHierarchyOffset + CandidateNode.NodeIndex 로 구성됩니다. NaniteHierarchyOffset 은 Nanite(1/5) 의 그림4 의 2 에서 본 FResource 에서 부터 얻어오며 Nanite 에셋이 생성될 때 결정됩니다. CandidateNode.NodeIndex 는 현재 thread 가 처리중인 NodeIndex 를 의미합니다. 그리고 두번째로는 ChildIndex 가 전달됩니다. 이제 Child Node 의 Visibility 확인을 위해 필요한 정보를 모두 준비했습니다.
5. 얻어온 HierarchyNode 정보가 유효한지 스트리밍되어 올라와있는지 확인할 수 있는 정보를 bool 변수에 담아둡니다. 그리고 BatchSize 보다 더 큰 LocalNodeIndex 를 위한 범위체크를 수행하여 Visible 상태를 설정합니다.
6. ShouldVisitChild 함수를 사용하여 ChildNode 로 교체할 수 있을지 판정하여 그 결과를 bool 값으로 돌려줍니다. 내부에서는 HZB 컬링 등을 체크하며, 상세한 함수 내부는 사항은 그림17 에서 확인해봅시다.
7. 현재 노드가 Leaf 가 아니면서 ChildNode 를 방문할 수 있고, 현재 노드 데이터가 정상적으로 로드되었다면, 현재 Node 의 ChildNode 를 처리할 수 있도록 해줍니다. WaveInterlockedAddScalar_ 함수를 사용하여 GroupNumCandidateNodes 에 ChildNode 를 방문할 Node 의 개수만큼 증가시켜줍니다. 그리고 각각의 thread 는 CandidateNodesOffset 에 자신이 저장할 CandidateNodesOffset 정보를 얻게 됩니다.
8. WorkGroup 내에 첫번째 thread 가 대표로 QueueState 로 부터 NodeWriteOffset 을 GroupNumCandidateNodes 개수 만큼 할당 받습니다. 그리고 QueueState 에 NodeCount 또한 GroupNumCandidateNodes 개수만큼 증가시켜 줍니다.
9. 현재 thread 가 ChildNode 를 방문할 예정이라면 조건문 내부에 진입합니다. 7번 과정에서 준비한 CandidateNodesOffset 에 8번 과정에서 얻어온 QueueState의 NodeWriteOffset 정보를 더해줘서 실제 ChildNode 정보를 기록할 Offset 을 완성합니다. 이 Offset 은 MainAndPostNodesAndClusterBatches 버퍼에서의 Offset 입니다. 그리고 완성한 Offset 정보가 최대 Node 수를 넘어가지 않는다면, StoreChildNode 함수를 호출하여 추가로 순회할 노드를 등록합니다. StoreChildNode 는 그림18에서 자세히 알아봅시다.
10. 만약 현재 노드가 Leaf 노드라면, 더 이상 등록할 노드가 없을 것입니다. 이때는 현재 노드의 Cluster 를 등록하여 이후 과정에서 Cluster 컬링을 처리할 수 있도록 해줍니다. 조건문 내부로 진입해봅시다.
11. 현재 노드가 가지고 있는 총 클러스터 수를 얻습니다.
12. QueueState 의 TotalClusters 에 현재 노드가 갖고 있는 클러스터 수를 더해주고 Cluster 를 기록할 인덱스를 얻습니다. 만약 저장할 수 있는 최대 클러스터 수를 넘어간다면, 넘지 않도록 clamp 시켜줍니다.
13. QueueState 의 ClusterWriteOffset 으로 부터 클러스터 개수 만큼의 Offset 범위를 얻어오며, 각각의 thread 는 자신만의 ClusterWriteOffset 을 VGPR 변수인 CandidateClustersOffset 에 저장합니다.
14. BaseClusterIndex, StartIndex, EndIndex 를 준비합니다. StartIndex, EndIndex 는 바로 전 과정에서 구한 CandidateClustersOffset 을 기반으로한 Node 정보를 기록할 인덱스 정보입니다. BaseClusterIndex 는 스트리밍된 Page 데이터로부터 FCluster 정보를 읽어올 때 사용하는 인덱스 입니다. 추후 Cluster 컬링 을 처리할때 사용합니다.
15. 현재 노드가 보유하고 있는 Cluster 정보를 기록합니다. StoreCluster 함수를 통해 기록하며 함수 내부는 그림19 에서 확인해봅시다.
16. 클러스터를 배칭해서 처리할 수 있도록 배치 정보를 만들어서 AddToClusterBatch 함수를 호출합니다.
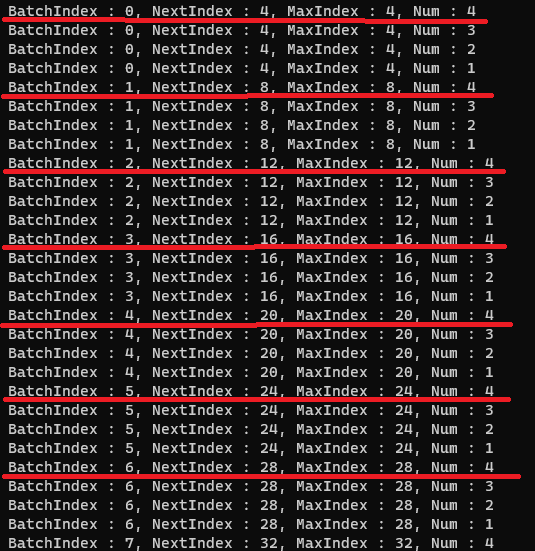
17. NANITE_PERSISTENT_CLUSTER_CULLING_GROUP_SIZE 는 64 입니다. 인덱스 계산의 이해를 빠르게 하기 위해서 직접 인덱스를 출력해봤습니다. 출력 결과가 너무 길어질 것 같아서 NANITE_PERSISTENT_CLUSTER_CULLING_GROUP_SIZE을 4 로 설정하여 출력했습니다. 그림20 를 함께 봐주세요. BatchIndex 가 4 개마다 바뀌지는 실제로는 64 개마다 변경될 것임을 생각하고 봐주셔야 합니다. 직접 출력한 결과에는 NextIndex 를 사용하여 인덱스를 증가 시키지 않았기 때문에 출력 결과에서 빨간 줄을 그은 부분만 실제로 실행된다고 보시면 됩니다.
- BatchIndex : 64 개를 1개의 배치로 한 경우 현재 클러스터가 포함된 Batch 의 Index 입니다.
- NextIndex : 다음 배치의 Cluster Index 에 대한 정보입니다. for loop 에서 Index 증가 분을 NextIndex 를 사용하여 계산합니다.
- MaxIndex : 현재 배치에서 최대 Cluster Index 를 의미합니다. 64 의 배수로 증가할 것입니다.
- Num : 현재 배치가 저장할 수 있는 Cluster 수를 의미하며 특별한 경우가 아니라면 64 일 것입니다.
18. 17 에서 생성한 BatchIndex 와 Num 정보를 갖고 AddToClusterBatch 를 호출합니다. 함수 내부는 그림21 에서 확인해 봅시다.
19. WorkGroup 내의 첫번째 thread 가 대표로 QueueState 의 NodeCount 를 감소시킵니다. 현재 WorkGroup 에서 처리한 Node 개수 만큼 노드 개수를 줄여줍니다.
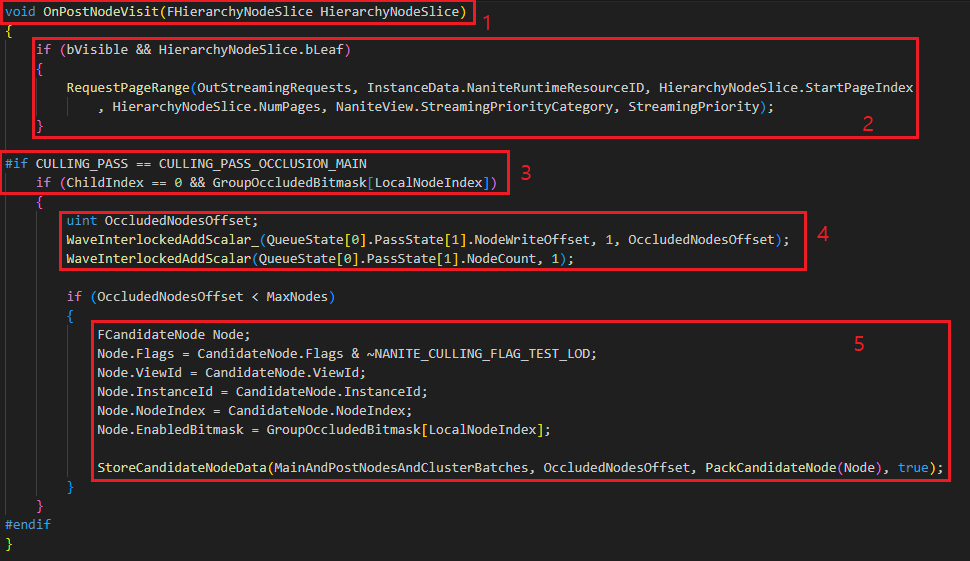
20. OnPostNodeVisit 에서는 현재 노드에 대한 처리를 마무리합니다. 만약 현재 노드가 Leaf 고 데이터를 스트리밍 해야한다면 RequestPageRange 로 스트리밍 데이터를 CPU 측에 요청합니다. 그리고 현재 노드의 자식 노드들 중 Occluded 된 노드가 있다면 현재 노드를 PostPass 에서 다시 컬링을 수행할 수 있도록 FCandidateNode 로 등록해줍니다. 함수 내부 구현은 그림22 에서 봅시다.


ShouldVisitChild 함수는 현재 처리중인 노드의 Child 노드에 대한 FHierarchyNodeSlice 정보를 받고 해당 노드의 Occluded 여부를 처리합니다.
1. 전달 받은 현재 노드의 Visible 정보를 설정해줍니다.
2. EnabledBitmask 는 자식 노드 중 Occluded 된 것이 있는지 여부를 확인하는 비트 마스크 입니다. ChildNode 중 Occluded 된 노드가 있다면 Visible 플래그를 false 로 설정해줍니다. 이 값은 아래의 8번 과정에서 설정해주게 됩니다.
3. 현재 노드가 Visible 이면, 조건문 내부로 진입합니다.
4. 컬링을 위해 필요한 Node 의 바운드 정보와 Primitive 정보들을 준비합니다. 이미 앞에 본 부분도 있고 중요하지 않은 부분인 것 같아서 세부사항은 넘어가겠습니다.
5. 현재 노드에 대해서 InstanceCulling 때와 마찬가지로 Distance, GlobalClipPlane 컬링을 차례로 수행합니다.
6. 5의 컬링 테스트 후에도 여전히 Visible 상태라면 ShouldVisitChildInternal 함수로 진입합니다.
6.1. 여기서 실제 화면에 프로젝션 된 크기를 기반으로 해당 노드를 컬링할지 여부를 결정합니다. 현재는 GetProjectedEdgeScales 함수가 하는 정확한 동작 방식을 이해하지 못한 상태입니다. 해당 부분을 알게 된다면 추후 여기에 내용을 추가하겠습니다.
7. MainPass 의 경우 이전 프레임의 HZB, PostPass 의 경우 현재 프레임의 경우 HZB 를 기반으로 컬링을 수행합니다.
8. 이전 프레임에는 없다가 현재 프레임에 새로 등장한 인스턴스를 처리하기 위해서, MainPass 에서는 컬링된 경우 PostPass 에서 한번 더 컬링 테스트를 수행합니다. 그래서 Visible && Loaded && Occluded 된 경우 PostPass 를 위해서 GroupOccludedBitmask 에 현재 ChildIndex 를 기록해둡니다. 이 정보는 그림22 에서 OnPostNodeVisit 함수에서 Child Node 를 추가로 순회할 수 있도록 FCandidateNode 를 저장할지 여부를 판단하는데 사용됩니다.
9. Occluded 되지 않았다면, 최종적으로 Visible 을 설정합니다.
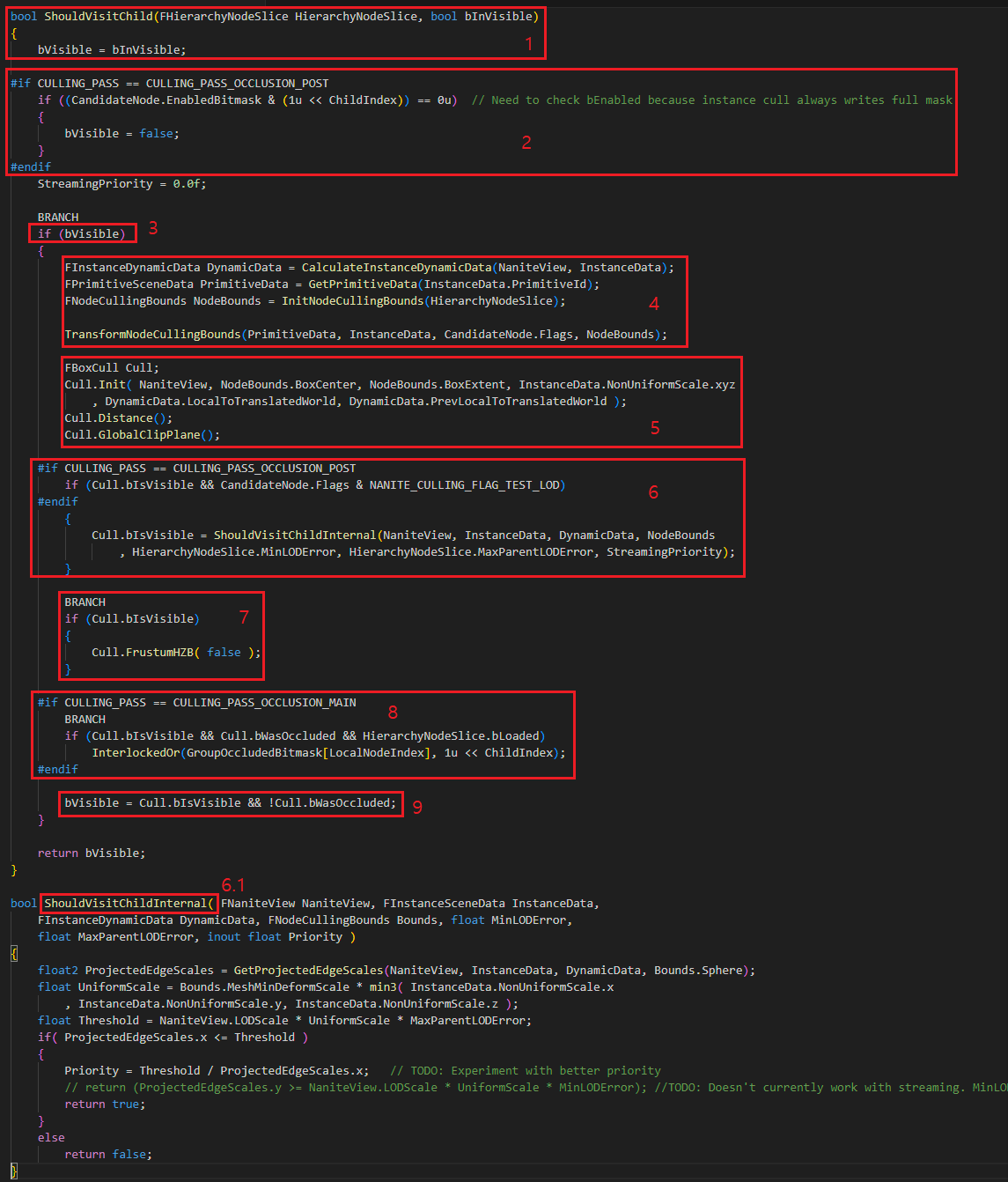
StoreChildNode 내부 구현을 확인해봅시다.
1. StoreChildNode 내부 진입합니다. 저장할 NodeOffset 와 ChildNode 에 대한 HierarchyNodeSlice 정보를 전달 받습니다.
2. 전달 받은 정보를 기반으로 FCandidateNode 객체를 만들고 StoreCandidateNode 함수를 호출합니다.
3. StoreCandidateNode 함수는 NodeAndClusterBatches 버퍼와 저장할 NodeIndex, FCandidateNode, 그리고 Main/Post Pass 에 대한 정보를 전달 받습니다.
4. FCandidateNode 를 패킹하여 StoreCandidateNodeData 함수를 한번 더 호출합니다.
5. StoreCandidateNodeData 내부로 진입합니다.
6. 그림5 의 11 에서 확인했던 MainAndPostNodesAndClusterBatches 의 기록할 Node 계산 부분입니다.
7. Offset 계산을 위해 필요한 함수들입니다. 참고 차 추가했습니다.

HierarchyNodeSlice 가 Leaf 노드의 경우 Cluster 를 저장하는 StoreCluster 함수를 확인해봅시다.
1. StoreCluster 함수가 호출됩니다. Cluster 가 저장될 MainAndPostCandidateClusters 에서 Offset 과 HierarchyNodeSlice, 이후 과정에서 실제 Cluster 데이터를 Load 하는데 사용 할 ClusterIndex 정보를 전달 받습니다.
2. 전달 받은 파라메터로 FVisibleCluster 를 만듭니다.
3. FVisibleCluster 를 패킹합니다. 그리고 MainAndPostCandidateClusters 버퍼에 저장합니다.

이 함수는 Cluster 를 64 개 단위로 묶었을 때 각 배치가 몇개의 Cluster 를 가지고 있는지를 MainAndPostCandidateClusters 에 저장합니다.
1. 전달 받은 BatchIndex 는 Cluster 를 64 개 단으로 묶었을 때의 인덱스입니다. MainAndPostCandidateClusters 에서 Cluster 를 저장하는 Offset 을 구하고 index 는 uint 타입이기 때문에 * 4 해줍니다. 그리고 Add 변수는 추가할 Cluster 의 개수 입니다.

ProcessNodeBatch 함수의 가장 마지막에 호출되는 함수인 OnPostNodeVisit 함수입니다. 내부 구현을 확인해봅시다.
1. OnPostNodeVisit 함수 내부에 진입합니다. FHierarchyNodeSlice 는 현재 노드의 자식 노드의 정보가 담겨있습니다.
2. 전달 받은 자식 노드가 Leaf 노드인 경우 클러스터 정보를 GPU 에서 읽을 수 있어야 합니다. 만약 현재 GPU 에서 사용할 수 없다면 RequestPageRange 함수를 호출해서 해당 데이터를 스트리밍 해달라고 CPU 에 요청합니다. Nanite 는 이런 방식으로 현재 렌더링에 필요한 페이지만 로드하여 런타임 메모리를 절약합니다.
3. MainPass 이고 첫번째 자식인 경우 대표로 해당 코드를 실행합니다. 현재 노드의 자식노드들 중 Occluded 된 노드가 있다면 조건문 내부로 진입합니다.
4. Occluded 된 자식이 있는 경우 현재 노드를 PostPass 에서 다시 수행할 수 있도록 하기 위해서 QueueState 에 NodeWriteOffset 과 NodeCount 를 갱신하고 FCandidateNode 를 저장할 Offset 을 얻습니다.
5. 최대 노드의 범위를 넘어가지 않는다면 현재 Node 에 대한 FCandidateNode 정보를 MainAndPostNodesAndClusterBatches 에 기록합니다.
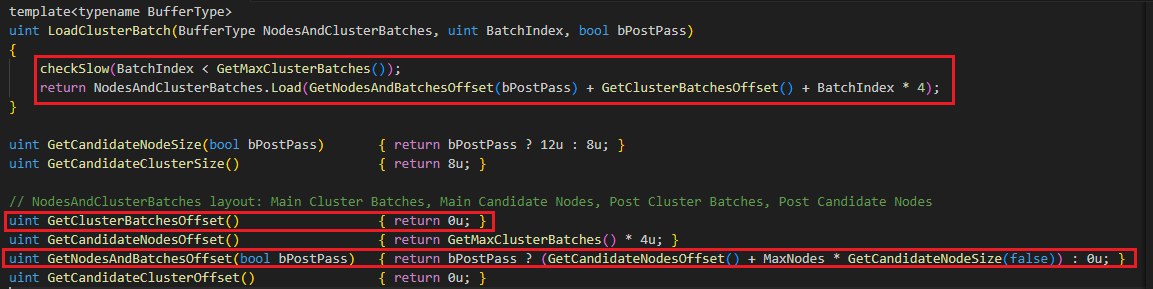
LoadClusterBatch 코드입니다.
전달받은 ClusterBatchIndex 에 있는 정보를 로드합니다. 사용된 GetCluserBatchesOffset() 는 0 입니다. 그리고 GetNodesAndBatchesOffset(bPostPass) 은 그림5의 11에서 확인했기 때문에 자세한 내용은 생략합니다.
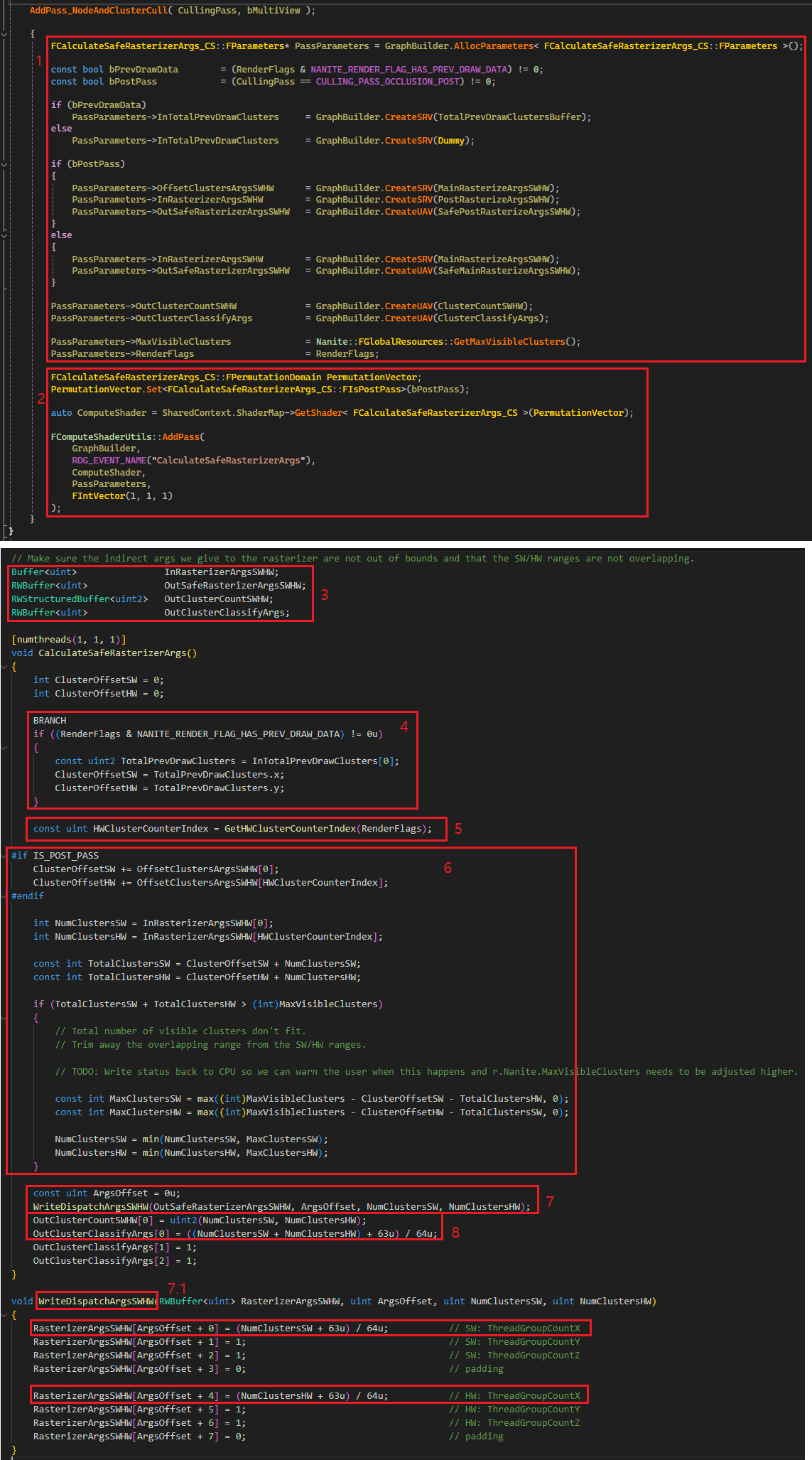
3.3.2.2.3. ProcessClusterBatch
Node Hierarchy 순회를 마친 후 Cluster 컬링을 수행합니다. ProcessClusterBatch 함수 내부를 확인해봅시다.
1. 전달 받은 파라메터 중 BatchStartIndex 는 QueueState 의 ClusterBatchReadOffset 입니다. 그리고 BatchSize 는 보통은 64 일 것이고, GroupIndex 의 경우 WorkGroup 내의 0~63 인덱스 중 하나 입니다. 이 정보들로 CandidateIndex 를 생성하는데, Cluster 가 64 개로 묶여 있기 때문에 NANITE_PERSISTENT_CLUSTER_CULLING_GROUP_SIZE(64) 를 BatchStartIndex 에 곱한 뒤 WorkGroup 의 인덱스(0~63)을 더하여 현재 thread 가 처리해야 할 Cluster 의 ReadOffset Index 를 최종적으로 얻을 수 있습니다. 이 인덱스를 LoadPackedCluster 에 전달해 패킹된 FVisibleCluster 를 얻습니다.
1.1. LoadPackedCluster 는 그림19 의 3 에서 MainAndPostCandidateClusters 에서 저장한 데이터입니다. MainPass 의 경우 0 인덱스 부터 저장되며, PostPass 의 경우 인덱스가 거꾸로 자라납니다.
2. ProcessCluster 함수를 호출하여 클러스터 컬링을 수행합니다.
2.1. FVisibleCluster, InstanceSceneData, PrimitiveData, View, FCluster 그리고 컬링에 필요한 정보들을 준비합니다.
2.2. FBoxCull 객체를 만들어 현재 Cluster 에 대한 Distance, GlobalClip 컬링을 수행합니다.
2.3. SmallEnoughToDraw 는 SW or HW Raterize 중 어떤 것을 할지 결정하는 함수입니다. 그림25 에서 함수 내부를 볼 수 있습니다만 이 함수도 GetProjectedEdgeScales 함수를 사용합니다. 현재는 해당 함수가 하는 일을 정확히 이해하지 못해서 내부는 분석하지 않았습니다. 그 외에 코드를 보면 SW 레스터라이즈의 경우 일정 크기 이상이 되면 효율이 더 나빠지기 때문에 HW 레스터라이즈를 사용할 수 있도록 bUseHWRaster 플래그를 갱신해주는 부분을 볼 수 있습니다.
2.4. PostPass 라면 FVisibleCluster 에 설정된 NANITE_CULLING_FLAG_USE_HW 여부로 HW 레스터라이즈를 사용할지 결정합니다. 이 부분은 PostPass 는 이미 MainPass 에서 SmallEnoughToDraw 함수를 수행하여 결과를 가지고 있기 때문에 해당 내용을 Flag 로 저장하여 로드하여 사용하는 것을 알 수 있습니다.
2.5. HZB 컬링을 수행합니다. 그리고 GlobalClip 컬링이 된 경우 bNeedsClipping 이 true 가 되어 HW 레스터라이즈를 수행하게 됩니다.
2.6. PostPass 라면 Occlued 된 경우 더 이상 재차 컬링 테스트를 하지 않을 것이므로 Occluded 된 경우 Visible 을 꺼줍니다.
2.7. 현재 thread 가 처리할 HW, SW 를 위한 ClusterOffset 을 위한 변수 초기화를 수행합니다.
2.8. Visible 이고 Occluded 되지 않은 Cluster 는 그려질 것이므로 VisibleClusterArgs 의 SW, HW 레스터라이즈 항목중 Cluster 개수를 기록하는 위치에 Cluster 를 증가 시켜줍니다.
2.9. 컬링 결과 Visible 인 경우 조건문 내로 진입합니다.
2.10. Occluded 되지 않았다면 레스터라이즈를 수행하면 되기 때문에 첫 번째 조건문으로 진입합니다.
2.11. HW Raster 를 사용하는 경우 ClusterOffsetHW 를 사용합니다. 추가로 PostPass 의 경우 OffsetClustersArgsSWHW[5] 을 Offset 에 더해줍니다. 이 것은 MainPass 에서 저장한 VisibleCluster 뒤에 PostPass 추가할 Cluster 를 넣어줘야 하기 때문에 들어간 부분입니다. 최대 클러스터 개수를 넘지 않는다면 StoreVisibleCluster 함수를 호출하여 FVisibleCluster 를 VisibleClustersSWHW 에 저장합니다. 이 때 HW 의 경우 버퍼의 마지막 부분에서 부터 기록하는 것을 볼 수 있습니다.
2.12. SW Raster 사용하는 경우 ClusterOffsetSW 를 사용합니다. 마찬가지로 PostPass 의 경우 MainPass 에서 추가한 부분 뒤에 VisibleCluster 를 기록하기 위해서 OffsetClustersArgsSWHW[0] 을 부터 Offset 에 더합니다. 최대 클러스터 개수를 넘지 않는다면 StoreVisibleCluster 함수를 호출하여 FVisibleCluster 를 VisibleClustersSWHW 에 저장합니다. SW 의 경우 버퍼의 첫 부분 부터 기록하는 것을 볼 수 있습니다.
2.13. MainPass 에서 Occluded 된 경우입니다. 이 경우는 PostPass 를 위해서 컬링 검사를 한번 더하기 위해서 준비합니다. QueueState 의 TotalClusters 를 ( 현재 WorkGroup 내에 이 코드를 수행하는) Active thread 수 만큼 증가 시켜줍니다(즉, Occluded 된 클러스터 수 만큼 증가).
2.14. PostPass 의 QueueState 로 부터 현재 thread 기록할 ClusterWriteOffset 을 얻어옵니다. 그리고 MainPass 에서 HW Raster 를 사용하는 경우 NANITE_CULLING_FLAG_USE_HW 를 설정하여 PostPass 에서 활용할 수 있도록 합니다.
2.15. StoreCandidateCluster 함수를 호출하여 Cluster 를 저장합니다. PostPass 에서 사용할 것이기 때문에 인덱스를 뒤쪽에서 부터 저장하도록 합니다.
2.16. AddToClusterBatch 함수를 사용하여 지금 추가한 Cluster 의 배치(64개 묶음)의 총 개수를 증가 시켜줍니다.


3.3.2.3. CalculateSafeRasterizerArgs
이제 Instance와 Cluster 컬링을 모두 마치고 Visible Cluster 에 대해서 레스터라이즈를 진행할 차례입니다. FRenderer::AddPass_InstanceHierarchyAndClusterCull 에서 AddPass_NodeAndClusterCull 호출 직후에 있는 코드입니다. 내용은 레스터라이즈를 위해서 필요한 Indirect draw argument 를 생성하는 과정이며 코드를 확인해봅시다.
1. 레스터라이즈에 필요한 Indirect draw argument 생성은 Compute shader 에서 수행합니다. 쉐이더를 실행하기 위해서 필요한 파라메터를 설정합니다. MainPass 의 경우 MainRasterizeArgsSWHW 를 InRasterizerArgsSWHW 에 바인딩하고 PostPass 에서는 PostRasterizeArgsSWHW 를 InRasterizerArgsSWHW 에 바인딩합니다. PostPass 는 추가로 OffsetClustersArgsSWHW 에 MainRasterizeArgsSWHW 를 바인딩합니다. 이것은 MainPass 에 있는 Cluster 정보 뒤에 PostPass 의 Cluster 정보가 있기 때문에 필요합니다. 레스터라이즈를 위한 최종 Indirect draw arguments 는 MainPass 는 SafeMainRasterizeArgsSWHW, PostPass 는 SafePostRasterizeArgsSWHW 에 기록 됩니다. ClusterCountSWHW 는 uint2 버퍼이며 SW/HW Cluster 개수가 각각 담깁니다.
2. CalculateSafeRasterizerArgs Compute Shader 를 실행합니다.
3. ComputeShader 쪽으로 넘어왔습니다. 1 에서 CPU 측에서 설정한 버퍼들 입니다.
4. CalculateSafeRasterizerArgs 함수 내부로 들어왔습니다. 기본 설정에서는 PREV_DRAW_DATA 가 없기 때문에 이 부분은 건너뜁니다.
5. HWClusterCountIndex 를 얻어오는데, Primitive, Mesh Shader 를 사용하지 않기 때문에 여기서는 5 가 리턴됩니다.
6. PostPass 에서는 MainPass 에서 사용한 SW/HW Cluster 가 있기 때문에 그 부분 만큼 Offset 을 증가 시켜줍니다. 그리고 이번 Pass 에서 처리할 SW, HW Cluster 의 개수를 NumClustersSW, NumClustersHW 에 각각 저장합니다. 모든 Pass 의 클러스터 개수를 합산하여 TotalClustersSW, TotalClustersHW 에 저장합니다. 그리고 이 값이 MaxVisibleClusters 를 넘어가지 않도록 NumClusterSW, HW 를 적절히 Clamp 시켜줍니다.
7. WriteDispatchArgsSWHW 함수를 사용하여 Rasterize 를 위한 SW, HW Indirect draw argument 를 SafeRasterizerArgsSWHW 버퍼에 기록 합니다. 어떤 데이터가 argument 로 기록될지 계속해서 봅시다.
7.1. WriteDispatchArgsSWHW 함수 내부를 보면, SW, HW 모두 ThreadGroup 의 X 에만 정보가 설정되는 것을 볼 수 있습니다. 그리고 총 Cluster 수를 64 개 단위로 묶었을 때, 총 배치 개수를 ThreadGroup 의 X 에 저장합니다. 아마도 Rasterize 단계에서도 WorkGroup 당 64 개의 thread 씩 작업을 배칭 하도록 Compute Shader 가 구현되어있지 않을까? 예상됩니다.
8. ClusterCountSWHW 는 uint2 타입으로 NumClustersSW, NumClustersHW 를 각각 저장합니다.
9. ClusterClassifyArgs[0] 에는 SW, HW Cluster 총 개수를 64 개 단위로 묶었을 때 총 배치 개수를 저장합니다.
이번 글은 굉장히 호흡이 길었습니다. 또한 GPU 아키텍쳐에 대한 이해도 있어야 해서 개인적으로는 이 부분이 Nanite 코드 중 시간을 가장 많이 쓴 부분 같습니다.
이전글 [UE5] Nanite (1/5)
다음글 [UE5] Nanite (3/5)
4. 레퍼런스
1. https://github.com/EpicGames/UnrealEngine/commit/072300df18a94f18077ca20a14224b5d99fee872
2. https://www.youtube.com/watch?v=eviSykqSUUw (Slide link)
3. https://docs.unrealengine.com/5.0/en-US/nanite-virtualized-geometry-in-unreal-engine/
4. https://scahp.tistory.com/126
5. https://scahp.tistory.com/85
6. https://scahp.tistory.com/84
7. https://github.com/Microsoft/DirectXShaderCompiler/wiki/Wave-Intrinsics
'UE4 & UE5 > Rendering' 카테고리의 다른 글
| [UE5] Nanite (4/5) (1) | 2024.03.23 |
|---|---|
| [UE5] Nanite (3/5) (1) | 2024.03.22 |
| [UE5] Nanite (1/5) (3) | 2024.03.14 |
| [UE5] D3D12 ResourceAllocation 리뷰(2/2) (0) | 2023.08.24 |
| [UE5] D3D12 ResourceAllocation 리뷰 (1/2) (0) | 2023.08.23 |



