
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Shadow
- Wavefront
- ShadowMap
- RayTracing
- forward
- SIMD
- UE5
- vulkan
- DX12
- GPU
- Study
- wave
- scalar
- rendering
- unrealengine
- deferred
- Graphics
- ue4
- VGPR
- optimization
- 번역
- hzb
- DirectX12
- Nanite
- GPU Driven Rendering
- SGPR
- shader
- scattering
- texture
- atmospheric
- Today
- Total
RenderLog
[UE5] Nanite (5/5) 본문
[UE5] Nanite (5/5)
최초 작성 : 2024-03-25
마지막 수정 : 2024-03-25
최재호
목차
1. 환경
2. 목표
3. 내용
3.1. DrawBasePass 전체 레이아웃 확인
3.2. FInitializeMaterialsCS
3.3. FClassifyMaterialsCS
3.4. FFinalizeMaterialsCS
3.5. BuildNaniteMaterialPassCommands
3.6. DrawNaniteMaterialPass
3.7. FNaniteIndirectMaterialVS 쉐이더 코드 확인
4. 부록
4.1. MaterialDepth 값에 생성에 대해서
5. 레퍼런스
1. 환경
Unreal Engine 5.3.2 (release branch 072300df18a94f18077ca20a14224b5d99fee872)
개인적으로 분석한 내용이라 틀린 점이 있을 수 있습니다. 그런 부분은 알려주시면 감사하겠습니다.
이번 글은 한 번에 많은 길이의 코드를 분석하는 부분이 종종 등장합니다. 그래서 글을 2개 띄우고 한쪽은 설명 부분을 한쪽은 코드 이미지를 최대화해서 보는 것을 추천합니다.
2. 목표
Nanite 에 들어간 핵심 기술들을 파악하고 BasePass 렌더링 과정을 코드레벨로 이해해 봅시다.
이번 글에서는 생성된 Visibility Buffer 로부터 G-Buffer 를 생성해 내는 Material Pass 를 확인해 봅시다.

이전 글에서 이야기했던 것처럼 이 글은 총 5개로 구성될 예정입니다.
1. Nanite 1/5 : Nanite 에서 사용하는 주요 기술과 MeshDrawCommand 생성 및 VisibilityBuffer 초기화 과정 리뷰
2. Nanite 2/5 : TwoPassOcclusionCulling 의 전체 레이아웃을 확인하고 MainPass 의 노드 및 클러스터 컬링 리뷰
3. Nanite 3/5 : SW, HW 레스터라이저와 PostPass 리뷰
4. Nanite 4/5 : Visibility Buffer 로 부터 Depth/Stencil 텍스쳐를 생성하는 부분 리뷰
5. Nanite 5/5 : Visibility Buffer 로 부터 G-Buffer 생성하는 MaterialPass 리뷰
3. 내용
3.1. DrawBasePass 전체 레이아웃 확인
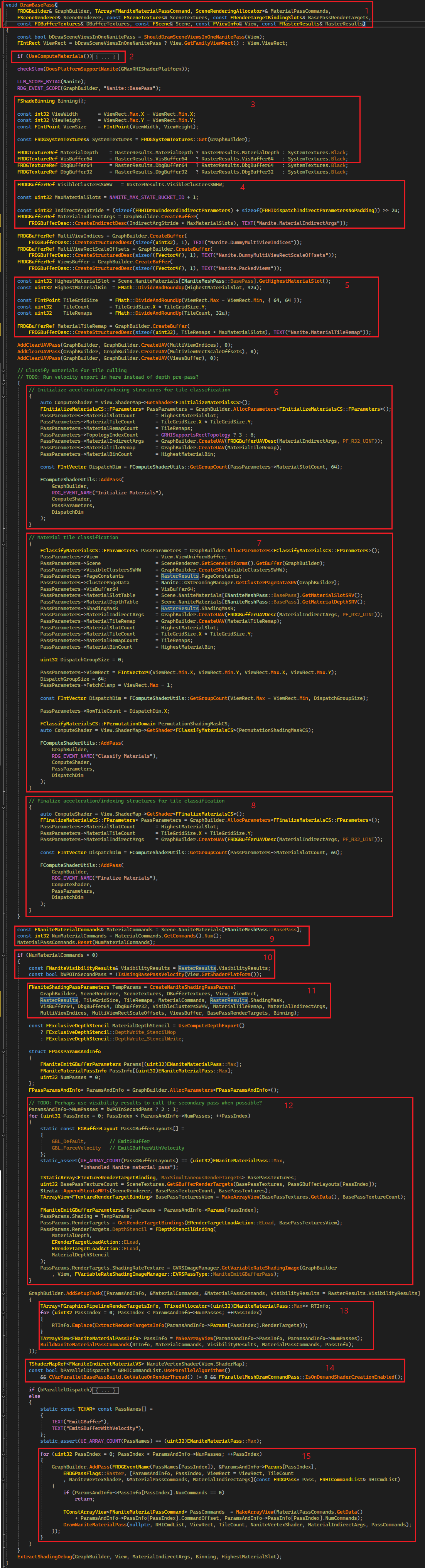
1. NaniteBasePass 에 진입합니다. 여기까지 오면 BasePass 에서 사용할 Depth Texture 와 Visibility Buffer 는 모두 준비되어 있을 것입니다.
2. 우리는 UseComputeMaterials 을 사용하지 않으므로 넘어가겠습니다.
3. FShaderBinning 은 ShadingBinMeta, ShadingBinArgs, ShadingBinData 와 같은 데이터가 들어있습니다. 이 부분을 앞으로 채울 것 같습니다. 그리고 VisibilityBuffer 와 MaterialDepth 텍스쳐를 바인딩합니다. MaterialDepth 텍스쳐는 Nanite (4/5)의 그림5에서 다뤘습니다.
4. VisibleClusterSWHW 또한 준비하며, MaxMaterialSlots 는 16384 로 설정됩니다. 이걸로 최대 동시에 사용가능한 머터리얼 수가 16384 개라는 것을 알 수 있습니다. MaterialIndirectArgs 를 생성합니다. 이 버퍼 DrawIndexedIndirect, DispatchIndirect 두 가지를 담는 것으로 보입니다만 우리가 리뷰할 ComputeShader 를 사용하지 않는 방식에서는 DrawIndexedIndirect 부분만 사용합니다. IndirectArgsStride 는 각 요소가 4 byte 이므로 4로 나눠주는 것으로 보이네요.
5. MaterialSlot 의 가장 큰 값을 가져와서 32 단위로 묶었을 때 몇 개가 나오는지를 HighestMaterialSlot 에 담습니다. 계속해서 화면의 총 픽셀을 기준으로 타일을 나누는데, 64x64 픽셀 크기의 타일을 만듭니다. 생성된 타일의 총 개수를 32 단위로 묶었을 때 몇개가 나오는지를 TileRemaps 에 담습니다. 마지막으로 MaterialTileRemap 이라는 버퍼를 TileRemaps * MaxMaterialSlots 개의 uint32 를 크기로 할당합니다. MaterialTileRemap 에는 특정 머터리얼이 사용되는 타일의 정보를 기록하는 버퍼입니다. 앞으로 볼 코드는 머터리얼 개수 별로 드로콜이 생성되는데, 이 버퍼를 사용하여 “해당 머터리얼이 전체 타일 중 어떤 타일들을 렌더링 한다”를 알 수 있습니다.
6. FInitializeMaterialsCS 쉐이더를 실행합니다. 여기서는 MaterialIndirectArgs 버퍼를 초기화합니다. 자세한 내용은 그림3 에서 확인해 봅시다.
7. FClassifyMaterialsCS 쉐이더를 실행합니다. 여기서 MaterialTileRemap 버퍼와 MaterialIndirectArgs 가 채워집니다. 자세한 내용은 그림4 에서 확인해 봅시다.
8. FFinalizeMaterialsCS 입니다. 여기서는 Compute Shader 부분을 위해서 64x64 크기의 타일을 8x8 크기로 만들었을 때의 총개수를 만들어줍니다. 하지만 여기서는 사용하지 않습니다. 제한 내용은 그림5 에서 확인해 봅시다.
9. FScene 으로 부터 Base 에서 사용하는 NaniteMaterials 의 총개수를 얻어옵니다. 이 NaniteMaterials 정보는 Nanite (1/5) 의 그림6 에서 SceneProxy 등록 시에 생성했습니다.
10. Nanite 머터리얼이 하나 이상 있다고 가정하고 조건문내로 진입합니다. bWPOInSecondPass 는 “r.VelocityOutputPass” 이 켜져 있는 경우 활성화되는데, 기본 옵션이 활성화되어있기 때문에 활성화되어있다고 가정합니다.
11. Nanite Material Shading 을 위해 필요한 파라메터를 설정합니다. TileGridSize, TileRemaps(타일 XY 각각을 32 개로 묶었을 때 몇 묶음인지), 기타 VisibilityBuffer 와 ShadingMask 등을 바인딩 합니다. 중요한 내용인 것 같지는 않아서 파라메터를 바인딩하는구나? 하고 넘어가겠습니다.
12. ParamsAndInfo 에는 bWPOInSecondPass 가 켜져 있기 때문에 2가 들어갑니다. 실제 렌더링 시에 WPO 가 없는 경우를 모아서 첫 번째 패스에 그리고 두 번째 패스에는 WPO 가 있는 경우 렌더링 하며 이때 Velocity 정보도 같이 기록됩니다. Nanite(4/5) 의 그림2에 7을 보면 WPO 가 켜져 있는 경우 Velocity 를 기록하지 않는데 여기서 켜주는 것을 볼 수 있습니다. 이제 ParamsAndInfo 변수에 PassParams 를 채우는데, 첫 번째 패스는 기본 EmitGBuffer 를 사용하고, 두 번째 패스에는 EmitGBufferWithVelocity 를 사용하여 Velocity 도 같이 출력하도록 설정하는 것을 볼 수 있습니다. 기타 렌더타겟 텍스쳐나 VRS 2.0 을 위한 ShadingRate 텍스쳐 바인딩하는 부분도 있네요.
13. BuildNaniteMaterialPassCommands 에서는 FScene 에 등록된 BasePass 의 NaniteMaterials 들을 FNaniteMaterialPassCommand 로 만들어서 OutNaniteMaterialPassCommands 배열에 담아줍니다. 그리고 12 과정에서 나눈 ParamsAndInfo 의 두 패스를 구분하기 위한 FNaniteMaterialPassInfo 정보를 만드는데, OutNaniteMaterialPassCommands 배열에서 몇 번째 인덱스부터 두 번째 패스를 사용하는지 정보가 담깁니다. 자세한 내용은 그림6 에서 추가로 알아봅시다.
14. MaterialPass 에서 사용할 FNaniteIndirectMaterialVS 입니다. 넘겨받은 InstanceIndex 를 MaterialTileRemap 를 사용하여 자신이 그릴 TileIndex 로 변환시킨 뒤 해당 타일을 위한 Vertex 의 위치를 확정해 줍니다. FNaniteIndirectMaterialVS 의 코드는 그림8 에서 자세히 확인해 봅시다.
15. 실제 Material Pass 를 수행합니다. 첫 번째 패스는 EmitGBuffer, 두 번째 패스는 EmitGBufferWithVelocity 입니다. 각 패스는 Material 개수만큼 Indirect draw call 을 만들어냅니다. 자세한 내용은 그림7 에서 확인해 봅시다.
3.2. FInitializeMaterialsCS
FInitializeMaterialsCS 는 MaterialPass 에 사용할 Indirect draw argument 와 MaterialTileRemap 버퍼를 초기화하는 패스입니다. MaterialPass 는 Nanite Material 개수만큼 Indirect draw call 이 발생하며, 각각의 draw call 은 각각의 머터리얼이 렌더링 하는 타일(64x64) 영역을 렌더링 합니다.
1. 그림2 의 6번 코드를 보면 MaterialSlot 개수를 64 개씩 묶었을 때의 개수를 WorkGroup 개수로 사용하여 Compute shader 를 Dispatch 했습니다. 그리고 각 WorkGroup 이 64 개의 thread 를 가지고 있는 것을 볼 수 있습니다. 그렇다면 SV_DispatchThreadID 는 MaterialSlot 의 인덱스일 것입니다.
2. 유효한 MaterialSlot 인지 확인하고 조건문 내로 진입합니다. 그리고 현재 MateriaSlot 이 사용하는 IndirectArgOffset 을 구합니다.
3. Graphics Pipeline 에 사용할 Indirect draw argument 를 만듭니다. 첫 번째는 Vertex 개수인데, Material Pass 는 Tile Quad 로 렌더링 될 거라 삼각형이 2개 사용됩니다. 그래서 Vetex 는 6 개입니다.
4. 인스턴스 개수는 앞으로 채울 것이기 때문에 0으로 초기화합니다.
5. Compute Shader 관련 Indirect draw argument 를 초기화합니다. 하지만 기본 패스에서는 사용되지 않습니다.
6. MaterialTileRemap 버퍼를 모두 0으로 초기화 합니다.

3.3. FClassifyMaterialsCS
FClassifyMaterialsCS 쉐이더입니다. 이 쉐이더는 Dispatch 한 WorkGroup 이 화면 픽셀을 가로세로 각각 64 로 묶었을 때 나오는 개수를 사용했습니다. 예를 들면, 화면 해상도가 (1466, 784) 라면 Dispatch 된 WorkGroup 은 (23, 13, 1) 입니다.
1. Nanite 에서 한 번에 사용할 수 있는 최대 Unique material 수는 NANITE_MAX_MATERIAL_SLOTS 은 (16384) 입니다. 그리고 이 Material 을 BitMask 를 사용하여 관리하도록 합니다. uint 변수는 32 bit 변수이고, 각각의 비트를 1개의 MaterialSlot 의 사용 여부를 표시하는 데 사용한다면 NANITE_MAX_MATERIAL_BINS == (NANITE_MAX_MATERIAL_SLOTS / 32u) 개의 uint 변수가 필요합니다. 그 외에 중요한 변수는 아래와 같습니다.
- MaterialRemapCount : 화면 픽셀 기준으로 나눈 타일(64x64) 개수를 32 개로 묶었을 때 총 몇 묶음이 나오는지 개수
- MaterialTileCount : 화면 픽셀 기준으로 나눈 타일(64x64) 의 총 개수
- MaterialSlotCount 의 최대 개수
- MaterialBinCount 는 MaterialSlotCount 을 32 개로 묶었을 때 총 묶음 개수.
- MaterialIndirectArgs : Material Pass 에 사용될 Indirect draw argument 를 저장할 버퍼
- MaterialTileRemap : MaterialSlot 이 주어질 때, 해당 MaterialSlot 이 그리는 타일 정보를 담고 있음(Bit mask 로 담고 있음).
2. TileMaterialBins[NANITE_MAX_MATERIAL_BINS] 는 총 16384 머터리얼 슬롯을 담당합니다. 여기서 NANITE_MAX_MATERIAL_BINS 가 512 이고, 각각의 uint 가 32 bit 를 다루기 때문에 512 * 32 = 16384 입니다. 그리고 TileMaterialBins 는 group shared 타입의 변수이기 때문에 현재 Tile 이 사용하는 MaterialSlot 위치에 1 bit mask 를 설정하기 위해서 사용되는 배열입니다. 현재 Tile 에 대한 MaterialSlot 의 사용 여부 mask 설정을 마치면 아래의 X 코드에서 MaterialSlot 별 사용하는 Tile 인덱스 정보로 변환해서 MaterialTileRemap 버퍼에 저장합니다. IndirectArgStride 는 Indirect draw argument 의 위치를 찾기 위한 Stride 입니다.
3. 하나의 WorkGroup 이 16x16 의 thread 를 작동시킵니다. SV_GroupThreadID 는 현재 실행 중인 thread 가 WorkGroup 내에서 몇 번째 인덱스를 가지는지입니다. 즉, ([0~15], [0~15], 0) 범위의 값이 들어옵니다.
4. 기본 변수들을 할당합니다.
- TileSlotOffset : WorkGroup 내에서 Thread 의 인덱스를 선형으로 표시
- TileBin1Offset, TileBin2Offset : 이 쉐이더가 Tile 1 개에 대한 정보를 처리하는 것을 다시 떠올려봅시다. 그리고 각 Tile 은 최대 NANITE_MAX_MATERIAL_SLOTS(16384) 개의 머터리얼을 가질 수 있습니다. WorkGroup 내의 스레드가 16x16=256 개 동작할 것입니다. 256 개의 thread 가 16384 개의 MaterialSlot 을 공평하게 나눠서 64 개씩 책임지게 됩니다. 이 때 책임지게 되는 작업은 MaterialTileRemap 에 현재 작업 중인 Tile 이 특정 MaterialSlot 에 사용된다고 Masking 해주는 것입니다. 각 thread 가 담당하는 64 개의 MaterialSlot 정보는 uint 2개를 사용하여 64 개의 bit mask 를 할당 받을 수 있습니다. 2개의 uint 위치는 각각 TileBin1Offset, TileBin2Offset 를 사용하여 얻게 됩니다. TileBin2Offset 에는 256 을 더해주게 되는데, NANITE_MAX_MATERIAL_SLOTS(16384) 를 32 bit mask 로 표현한 개수는 NANITE_MAX_MATERIAL_BINS(512) 입니다. 여기서 16x16 thread = 256 이기 때문에 512 개의 Bin 을 모두 커버하려면 TileBin2Offset 에 [0~255], TileBin2Offset 에 [256~511] 의 인덱스를 할당해주면 될 것입니다. 그래서 TileBin2Offset 에는 256 을 더해줍니다.
- GroupPixelStart 는 현재 처리 중인 타일이 화면 픽셀 기반해서 Offset XY 어느 위치 인지를 저장합니다. 이 값은 ShadingMask 버퍼를 참조해서 Shading 정보를 얻어오는 데 사용됩니다.
5. group shared 변수인 TileMaterialBins 를 0으로 초기화합니다.
6. Tile 당 64x64 픽셀을 커버하는 것을 떠올린 후 코드를 봅시다. 현재 WorkGroup 이 16x16x1 thread 를 실행하기 때문에 Tile 1개의 픽셀 모두를 방문하려면 16x4 = 64 로 4번 반복문을 수행하면 됩니다. Y 축에 대해서 4 번 for loop 를 stride 16 으로 돌고 있는 것을 볼 수 있습니다.
7. 이제 X 축에 대해서 4 번 for loop 를 돌고 있습니다. 그리고 ShadingMask 버퍼로부터 해당 픽셀의 ShadingMask 정보를 얻습니다.
8. 다시 4 번의 for loop 을 돌면서 7에서 준비한 ShadingMask 에 대한 처리를 시작합니다.
9. 이전 과정에서 준비한 ShadingMask 정보를 Unpack 합니다. 그리고 ShadingMask 에 기록된 ShadingBin 변수를 통해 어떤 머터리얼을 사용하는지 알 수 있습니다.
10. 현재 처리 중인 픽셀이 Nanite 픽셀인지, 어떤 ShadingBin 인덱스를 사용하는지 확인합니다. 이전에 사용한 ShadingBin 과 다른 경우만 조건문 내로 들어가는데, 현재 타일이 사용하는 Material 정보는 한 번만 마스킹하면 되기 때문에 조건 비교를 합니다.
11. 이 코드는 TileMaterialBins 에 “현재 처리 중인 Tile 이 사용하는 MaterialSlot 의 비트를 설정” 해줍니다. 이 코드도 Wave intrinsic 을 사용하여 Atomic operation 을 줄여주는 아주 좋은 코드 예제입니다. 간단히 설명하면 이 코드에는 총 256 개의 thread 가 동시에 진입할 수 있으며 각각의 VGPR 은 서로 다른 ShadingBin 을 가지고 있을 것입니다. 이때 256 thread 중 맨 첫 번째 lane 의 값이 bWrite = true 를 설정합니다. 그리고 while(ShadingBin ≠ ToScalarMemory(ShadingBin)) 에 도달하면 bWrite 를 설정한 thread 와 동일한 ShadingBin 값을 가진 thread 는 모두 비활성화 됩니다. 그리고 다음 loop 에서는 Active thread 중 맨 첫번째 lane 의 bWrite = true 가 설정될 것입니다. 그리고 while(ShadingBin != ToScalarMemory(ShadingBin)) 를 만나면서 과정이 반복됩니다. 예를 들어 256 개의 thread 에 앞쪽 128 개는 ShadingBin 이 3, 뒤쪽 128 개는 ShadingBin 이 8 이라고 합니다. 그리고 VGPR 변수인 bWrite 는 thread 0 번과 thread 128 번만 bWrite 로 변할 것입니다. 그러면 InterlockedOr 연산은 단 2개의 thread 에서만 일어납니다.
12. 현재 처리 중인 Tile 이 리니어 인덱스 기준으로 어느 위치인지 알아내 TileLinearOffset 에 저장합니다. 그리고 >> 5 는 32 로 나누는 연산이기 때문에 TileRemapBinIndex 는 TileLinearOffset / 32 입니다. 아마도 TileLinearOffset 정보를 bit masking 처리하려는 것처럼 보입니다.
13. MaterialSlot 의 범위를 비교하고 조건문 내로 진입합니다. 현재 thread 가 담당하는 MaterialSlot 의 비트를 얻어옵니다. TileMaterialBins 는 group shared 변수로 11 과정에서 현재 Tile 이 사용되는 MaterialSlot 의 Index 정보를 bit mask 로 기록했었습니다.
14. TileBin1Offset * 32 를 곱하면 MaterialSlot1Base 에 저장합니다. bit mask 기반 인덱스가 아닌 실제 인덱스 정보를 만들 준비를 합니다. 여기에 32 개의 bit mask 에 대한 정보를 더 해야만 최종 Index 가 구성될 것입니다. 1로 Bit masking 된 것이 있는 경우 while loop 내로 진입합니다. 그리고 1 로 bit mask 된 인덱스를 가져오고, 해당 bit 를 0 으로 설정해 줍니다.
15. 14 번에서 준비한 MaterialSlot1Base + Bin1Index(32 bit mask 를 참조해 얻어온 인덱스) 를 사용하여 현재 처리 중인 Tile 이 사용 중인 MaterialSlot 의 인덱스를 얻어왔습니다. MaterialSlot 인덱스를 알 수 있으니 해당 MaterialSlot 이 렌더링 할 Tile 개수가 1 증가해야 할 것입니다. 그 부분을 해줍니다
16. MaterialTileRemap 은 MaterialSlot 이 주어졌을 때, 화면의 어떤 Tile 을 그릴 것인지 정보를 bit mask 로 저장합니다. MaterialRemapCount 는 화면을 64x64 Tile 로 묶었을 때 나오는 총 Tile 수를 32 개 기준으로 묶었을 때 묶인 개수입니다(이것도 bit mask 로 표현하기 위해서임). MaterialRemapCount * MaterialSlot1 을 보면, 각 MaterialSlot 은 Tile 개수만큼의 비트를 할당받고 있음을 알 수 있습니다. 이 코드를 실행하고 나면 MaterialTileRemap 를 사용하여 MaterialSlot 을 알고 있으면 어떤 Tile 에 MaterialSlot 이 영향을 주는지 알 수 있게 됩니다.
17~20 번 과정은 13~16 번 과정과 동일합니다. WorkGroup 당 512 개의 MaterialSlotBin(각 bin 은 32개의 MaterialSlot 저장) 을 담당하기 위해서 13~16 번 과정에서는 [0, 255], 17~20 번 과정에서는 [256, 511] 범위를 담당합니다.

3.4. FFinalizeMaterialsCS
FFinalizeMaterialsCS 는 MaterialSlot 개수를 64 개로 묶은 묶음 수만큼 WorkGroup 을 Dispatch 합니다. 쉐이더 내부에서는 Material Pass 를 위한 Indirect draw argument 중 Compute shader 쪽을 위한 micro tile(8x8) 로 groups 의 Dispatch 수를 결정합니다. 하지만 우리가 리뷰하는 기본설정에서는 해당 Indirect draw arguments 를 사용하지 않습니다.
1. FinalizeMaterials 쉐이더 코드에 진입합니다. 각 WorkGroup 당 64 개의 thread 를 실행합니다. 그래서 SV_DispatchThreadID 는 MaterialSlot 개수가 됩니다.
2. MaterialSlot 이 범위를 넘어서는지 확인하고 조건문 안으로 진입합니다.
3. IndirectArgOffset 은 MaterialSlot * IndirectArgsStride 로 구합니다. 그리고 Graphics Pipeline Indirect draw argument 에 기록한 MaterialSlot 이 렌더링 해야 할 Tile 개수를 얻습니다.
4. 총 타일 수에 Tile 당 렌더링하는 픽셀 수를 곱하여 8x8 크기 타일로 나누는 경우 몇 개가 나오는지를 DispatchGroup.X 에 저장합니다. (8x8 = 64 이기 때문에 DivideAndRoundUp 을 수행)

3.5. BuildNaniteMaterialPassCommands
이 코드는 CPU 측에 있는 코드로 이제 Material Pass 를 위한 MeshDrawCommand 를 준비합니다. WPO 사용 여부에 따라서 2개의 패스로 나누게 되는데, WPO 를 사용하면 두 번째 패스에서 렌더링 되며 Velocity Buffer 에 Velocity 를 출력합니다.
1. BuildNaniteMaterialPassCommands 함수에 진입합니다. 이 함수를 수행하고 나면OutNaniteMaterialPassCommands(FNaniteMaterialPassCommand 배열)이 채워지고, WPO 에 따라 나뉘는 2개의 패스 각각이 사용한 FNaniteMaterialPassCommand 의 범위를 OutNaniteMaterialPassCommands 에서 찾을 수 있도록 Offset 과 Command 수를 기록하는 OutMaterialPassInfo(FNaniteMAterialPassInfo)의 값을 설정해 줍니다.
2. OutMaterialPassInfo 의 Offset, Num 값을 0 초기화해줍니다.
3. GetMaterialPass 람다함수는 Material 이 WPO 를 사용하는 경우 EmitGBufferWithVelocity 그렇지 않은 경우 EmitGBuffer 를 리턴해줍니다. EmitGBufferWithVelocity 면 두 번째 패스에서 렌더링 됩니다.
4. InserPassCommand 람다함수는 생성된 FNaniteMaterialPassCommand 를 OutNaniteMaterialPassCommands 에 넣어줍니다. 이 때 전달되는 PassIndex 를 기반으로 첫번째 or 두번째 패스에 Command 를 추가해 주며, OutMaterialPassInfo 에 Offset 과 Num 값을 경신해 줍니다.
5. BucketMaps 개수만큼 반복문을 수행합니다. 이때 BucketMap 을 가져온 MaterialCommands 는 Scene.NaniteMaterials[ENaniteMeshPass::BasePass] 입니다. BucketMap 은 FNaniteMaterialEntry 항목을 갖고 있는데 Nanite BasePass 에서 소유하고 있는 모든 머터리얼로 보면 됩니다.
6. FNaniteMaterialEntry 가 사용할 MeshDrawCommand 를 가져옵니다. 이 MeshDrawCommand 는 SceneProxy 가 FScene 에 등록될 때 준비해 뒀으며, Nanite (1/5) 의 그림5 에서 확인할 수 있습니다. Visibility 여부를 확인하는데 현재는 항상 그린다고 하고 계속해서 코드를 보겠습니다.
7. FNaniteMaterialEntry 로 부터 필요한 Material 정보를 얻습니다. 중요한 정보는 MaterialDepth 정보입니다. 이 값은 현재 Material 을 대표하는 Unique 값으로 Nanite (4/5) 의 그림5 에서 생성한 MaterialDepth 버퍼를 Depth Buffer 로 바인딩하고 이 MaterialDepth 값을 Vertex Shader 에서 사용하도록 합니다. Material Pass 에서는 Depth Test 를 Equal 로 설정하여 현재 렌더링 하는 MaterialSlot 정보와 동일한 픽셀을 가진 DepthBuffer 의 픽셀만 Depth Test 에 통과하게 하는 방식으로 쉐이딩 합니다.
8. MeshDrawCommand SortKey 를 설정합니다. 우리는 bVelocityPassEnabled 조건문 내로 진입하게 되며, PassIndex 0 이 먼저 그려지고, 그 다음 Velocity 를 저장하는 PassIndex 1 이 렌더링 되어야 하기 때문에 거기에 맞게 SortKey 를 변경해 주는 부분을 볼 수 있습니다.
9. 현재 처리 중인 Material 에 대한 FNaniteMaterialPassCommand 가 모두 준비되었기 때문에 4 에서 만든 InsertPassCommand 를 통해서 추가해 줍니다.
10. 생성한 FNaniteMaterialPassCommand 를 정렬합니다.

3.6. DrawNaniteMaterialPass
이제 준비한 FNaniteMaterialPassCommand 를 렌더링 합니다.
1. DrawNaniteMaterialPass 함수로 진입합니다. WPO 여부에 따라서 2개의 패스로 나뉘어 실행되는데 각 패스별로 실행해야 할 FNaniteMaterialPassCommand 의 범위는 TArrayView 를 통해서 건네받습니다.
2. 렌더링 할 FNaniteMaterialPassCommand 가 없다면 early exit 합니다.
3. 코드 리뷰를 간결하게 하기 위해서 Parallel 이 아닌 패스로 보도록 하겠습니다.
4. Viewport 를 설정하고, SubmitNaniteIndirectMaterial 을 각각의 FNaniteMaterialPassCommand 별로 호출합니다.
5. SubmitNaniteIndirectMaterial 로 진입합니다.
6. FNaniteMaterialPassCommand 에 설정했던 MaterialDepth 정보를 가져옵니다. 이 값을 8 번 과정에서 VertexShader PassParameter 에 넣어줍니다.
7. SubmitDrawIndirectBegin 함수 내부에는 SubmitDrawBegin 함수가 있습니다. 이 부분은 렌더링에 필요한 사전 작업을 수행합니다. 자세한 내용은 MeshDrawCommand 를 다루는 [UE5] MeshDrawCommand (2/2) 의 그림20 에서 확인해 볼 수 있습니다.
8. VertexShader 에 필요한 데이터를 바인딩합니다. MaterialDepth 와 MaterialSlot, 그리고 InstanceFactor 는 현재 Material 이 렌더링 하는 타일의 개수입니다. 이것을 32 개로 묶은 경우 묶음의 개수를 TileRemapCount 에 담습니다.
9. MaterialIndirectArgs 버퍼는 MaterialSlot 개수만큼 Indirect draw argument 가 있기 때문에 거기에 맞게 사용할 퍼 Offset 을 구한 다음 SubmitDrawIndirectEnd 를 호출합니다. 이 함수에서는 실제 DrawIndexed 와 같은 렌더링 드로콜을 호출합니다.

3.7. FNaniteIndirectMaterialVS 쉐이더 코드 확인
마지막으로 FNaniteIndirectMaterialVS 입니다. 이 Vertex Shader 는 순차적으로 증가하는 InstanceID 로부터 MaterialSlot 내에 그려야 할 Tile 의 인덱스(비 순차) 를 얻어내고, Depth 값이 MaterialDepth 값을 설정한 다음 Verte shader 를 마칩니다. 이때 바인딩 된 MaterialDepth Buffer 와 Vertex shader 에서 전달한 MaterialDepth 이 같은 픽셀만 Shading 이 수행됩니다.
1. 그림7의 6 번 코드에서 바인딩한 MaterialDepth, MaterialSlot, TileRemapCount 변수들과 VertexShader 의 진입점인 FullScreenVS 입니다. 이름은 Fullscreen 이지만 실제로는 64x64 의 타일 1개를 만듭니다. 여기서 SV_InstanceID 는 [0~MaterialSlot 이 그릴 타일 수] 중 하나가 들어옵니다.
2. GridSize 는 Tile 의 총 X, Y 별 개수입니다.
3. TileIndex 를 InstanceIndex 로 설정합니다. 현재 렌더링 중인 MaterialSlot 를 사용하는 Tile 의 인덱스가 0, 1, 2 일지? 0, 5, 20 일지는 모르기 때문에 이 TileIndex 값을 실제 현재 MaterialSlot 이 사용하는 값을 변환시킬 것입니다.
4. MaterialTileRemap 에는 MaterialSlot 을 알면 어떤 Tile Index 를 렌더링 해야 할지 정보가 들어 있다고 했었습니다. 그리고 InstanceIndex 는 [0, MaterialSlot 이 그릴 타일 수] 가 들어온다고 하였습니다. 이 선형적으로 증가하는 InstanceIndex 숫자를 실제 사용하는 Tile Index 에 매핑하기 위해서 아주 간단한 방법을 사용합니다. 바로 [0, MaterialSlot 이 그릴 타일 수] 범위의 bit 앞에서 부터 차례로 세면서 (InstanceIndex + 1) 개수와 일치하는 Tile Index 를 찾아서 그립니다. 계속해서 코드를 봅시다. 그전에 MaterialTileRemap 에서 현재 MaterialSlot 까지의 Offset 을 구합니다. 그 값을 RemapBaseOffset 에 저장합니다. 그리고 TargetTileCount = TileIndex + 1 로 설정합니다. (1 로 설정된 비트 개수가 TargetTileCount 와 같아지면 해당 Tile Index 를 찾은 것임!)
5. TileRemapCount 는 타일의 총개수를 32 개로 묶었을 때 묶음 수입니다. 각 uint 값은 32 개의 bit masking 이 가능하기 때문에 모든 Tile 을 순회하는데 TileRemapCount 횟수만큼 수행하면 됩니다. MaterialTileRemap 에서 설정된 bit 를 가져와서 설정된 bit 의 수만큼 ValidTiles 를 증가시켜줍니다. 그리고 ValidTiles > TargetCount 가 된다면 현재 RemapData(MaterialTileRemap 에서 가져온 32 개의 bit) 중 하나에 현재 Instance 가 그려야 할 Tile Index 가 있다는 것입니다. 그럼 여기서 멈추고 계속해서 RemapData 내의 32 bit mask 를 읽어봐야겠죠?
6. RemapData 를 앞에서부터 하나씩 읽어가면서 ValidTiles == TargetTileCount 인 경우까지 진행합니다. 반복문을 마치고 나면, RemapBinBit 는 현재 비트가 32 비트 중 몇 번째 index 인지를 담고 있기 때문에 TileIndex = (RemapBin * 32) + RemapBinBit 로 구할 수 있을 것입니다.
7. 이 값은 “Tile (64x64) 가 NxM 개 있을 때 해상도 / 실제 해상도” 의 비율을 갖고 있습니다. 64x64 타일 단위로 쪼개게 되면, 실제 해상도가 정확한 크기의 64 사이즈로 잘리지 않기 때문에 남는 부분이 생깁니다. 이 부분에 대한 비율을 구하는 것입니다.
8. 6에서 구한 TileIndex 를 PixelShader 로 보내기 위해서 설정해 줍니다. GridStep 은 Tile 한 개가 UV(0~1 사이값) 을 기준으로 했을 때 얼마의 크기인지에 대한 값입니다. GridPos 는 현재 TileIndex 가 선형인덱스 기반인 x, y 기반으로 변경해 줍니다.
9. 현재 Tile 의 Vertex 가 UV 좌표를 기반으로 어떤 값을 가지는지 계산합니다. Tile 을 위한 4 개의 Vertex 가 이제 UV 값으로 변환되었습니다.
10. 이제 최종 Position 값을 확정합니다. 위에서 구한 Tile 의 UV 좌표를 NDC 공간으로 변환하고, Depth 값을 Material Depth 로 설정합니다. 이제 나머지는 MaterialDepth Buffer 의 Depth 값과 Vertex shader 에서 설정한 Material Depth 값이 일치하는 픽셀에 대해서 Shading 한 결과를 각각의 G-Buffer RT 에 저장합니다. Pixel Shader 의 경우 기존의 BasePassPixelShader.usf 와 동일하기 때문에 따로 다루지 않아도 될 것 같습니다.

Material Pass 에서 Tile 을 렌더링을 디버깅해보면 아래와 같이 머터리얼이 영향을 주는 Tile 영역만 렌더링 된 것을 볼 수 있습니다.


4. 부록
4.1. MaterialDepth 값에 생성에 대해서
Nanite (4/5) 의 그림5 에서 만든 MaterialDepth Buffer 는 MaterialDepthId 값을 사용하여 MaterialDepth 값을 구성합니다. 이 값은 MaterialDepthTable 이라는 버퍼에서 가져온 데이터를 통해서 구성되는데요. 이 버퍼는 어떻게 구성되는지? BuildNaniteMaterialPassCommands (그림6 의 7번 코드)의 과정에서 FNaniteCommandInfo::GetDepthId(MaterialId) 와 정말 같은 값을 사용하여 만들어졌는지 확인해 보면 좋을 것 같아서 부록으로 해당 내용을 추가했습니다.
먼저 BuildNaniteMaterialPassCommands 에서는 아래와 같은 코드를 통해서 FNaniteIndirectMaterialVS 가 MaterialDepth 를 사용할 수 있도록 값을 전달해 줍니다.
BuildNaniteMaterialPassCommands 과정에서...
const int32 MaterialId = Iter.GetElementId().GetIndex();
PassCommand.MaterialDepth = FNaniteCommandInfo::GetDepthId(MaterialId);
static float GetDepthId(int32 StateBucketId)
{
return float(StateBucketId + 1) / float(NANITE_MAX_STATE_BUCKET_ID);
}
Nanite (4/5) 의 그림5 의 4번 코드를 보면 MaterailDepthTable 에서 Material 값을 로드합니다.
MaterialDepthTable 은 GPUScene 에 MaterialSlot 값이 업데이트될 때 같이 업데이트됩니다. 아래 코드를 봐주세요.
아래 코드를 보면 MaterialDepthUploader 를 통해 MaterialSlot 위치에 MaterialEntry.MaterialId 를 저장하는 것을 볼 수 있습니다.
void FNaniteMaterialCommands::FUploader::Lock(FRHICommandListBase& RHICmdList)
{
...
for (const FMaterialUploadEntry& MaterialEntry : DirtyMaterialEntries)
{
*static_cast<uint32*>(MaterialDepthUploader->Add_GetRef(MaterialEntry.MaterialSlot))
= MaterialEntry.MaterialId;
...
}
DirtyMaterialEntries.Empty();
}
그럼 MaterialEntry.MaterialId 는 어떻게 만들어지는 걸까요? 아래코드를 봐주세요. 아래 코드에서 MaterialEntry.MaterialId 를 생성할 때 사용한 함수와 PassCommand.MaterialDepth = FNanitecommandInfo::GetDepthId(MaterialId) 가 동일한 함수와 아규먼트를 통해 MaterialDepth 를 생성한 것을 알 수 있습니다.
FNaniteCommandInfo FNaniteMaterialCommands::Register(FMeshDrawCommand& Command, FCommandHash CommandHash, uint32 InstructionCount, bool bWPOEnabled)
{
FNaniteCommandInfo CommandInfo;
FCommandId CommandId = FindOrAddIdByHash(CommandHash, Command);
CommandInfo.SetStateBucketId(CommandId.GetIndex()); // ** 여기서 설정한 StateBucketId 를 사용하여 MaterialId 를 만듬.
FNaniteMaterialEntry& MaterialEntry = GetPayload(CommandId);
if (MaterialEntry.ReferenceCount == 0)
{
check(MaterialEntry.MaterialSlot == INDEX_NONE);
MaterialEntry.MaterialSlot = MaterialSlotAllocator.Allocate(1);
MaterialEntry.MaterialId = CommandInfo.GetMaterialId(); // ** GetMaterialId 함수를 호출하여 최종적으로 MaterialId 를 만들어냄
...
// 아래는 FNaniteCommandInfo 의 멤버 함수들...
inline void SetStateBucketId(int32 InStateBucketId)
{
check(InStateBucketId < NANITE_MAX_STATE_BUCKET_ID);
StateBucketId = InStateBucketId;
}
inline int32 GetStateBucketId() const
{
check(StateBucketId < NANITE_MAX_STATE_BUCKET_ID);
return StateBucketId;
}
inline uint32 GetMaterialId() const
{
return GetMaterialId(GetStateBucketId());
}
static uint32 GetMaterialId(int32 StateBucketId)
{
float DepthId = GetDepthId(StateBucketId);
return *reinterpret_cast<uint32*>(&DepthId);
}
static float GetDepthId(int32 StateBucketId)
{
return float(StateBucketId + 1) / float(NANITE_MAX_STATE_BUCKET_ID);
}
5. 레퍼런스
1. https://github.com/EpicGames/UnrealEngine/commit/072300df18a94f18077ca20a14224b5d99fee872
2. https://www.youtube.com/watch?v=eviSykqSUUw (Slide link)
3. https://docs.unrealengine.com/5.0/en-US/nanite-virtualized-geometry-in-unreal-engine/
4. https://scahp.tistory.com/129
5. https://scahp.tistory.com/126
'UE4 & UE5 > Rendering' 카테고리의 다른 글
| [UE5] Nanite (4/5) (1) | 2024.03.23 |
|---|---|
| [UE5] Nanite (3/5) (1) | 2024.03.22 |
| [UE5] Nanite (2/5) (0) | 2024.03.21 |
| [UE5] Nanite (1/5) (3) | 2024.03.14 |
| [UE5] D3D12 ResourceAllocation 리뷰(2/2) (0) | 2023.08.24 |



