
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- atmospheric
- UE5
- RayTracing
- DirectX12
- VGPR
- DX12
- ue4
- Shadow
- Nanite
- ShadowMap
- forward
- vulkan
- unrealengine
- GPU Driven Rendering
- shader
- SIMD
- Wavefront
- hzb
- deferred
- GPU
- Study
- Graphics
- SGPR
- texture
- 번역
- rendering
- wave
- optimization
- scalar
- scattering
- Today
- Total
RenderLog
[UE5] Nanite (3/5) 본문
[UE5] Nanite (3/5)
최초 작성 : 2024-03-22
마지막 수정 : 2024-03-22
최재호
목차
1. 환경
2. 목표
3. 내용
3.1. AddPass_Rasterize(MainPass)
3.1.1. FRasterizerPass 준비
3.1.2. AddPass_Binning(MainPass) 전체 레이아웃
3.1.2.1. RasterBinCount
3.1.2.2. RasterBinReserve
3.1.2.3. RasterBinScatter
3.1.3. HW Rasterize
3.1.4. SW Rasterize
3.2. 현재 프레임 기반 HZB 생성
3.3. PostPass 와 MainPass 의 차이점 정리
3.3.1. FInstanceCull_CS 차이점
3.3.2. InstanceCull Shader 차이점
3.3.3. FNodeAndClusterCull_CS 차이점
3.3.4. FNodeAndClusterCull_CS Shader 차이점
4. 레퍼런스
1. 환경
Unreal Engine 5.3.2 (release branch 072300df18a94f18077ca20a14224b5d99fee872)
개인적으로 분석한 내용이라 틀린 점이 있을 수 있습니다. 그런 부분은 알려주시면 감사하겠습니다.
이번 글은 한 번에 많은 길이의 코드를 분석하는 부분이 종종 등장합니다. 그래서 글을 2개 띄우고 한쪽은 설명 부분을 한쪽은 코드 이미지를 최대화해서 보는 것을 추천합니다.
2. 목표
Nanite 에 들어간 핵심 기술들을 파악하고 BasePass 렌더링 과정을 코드레벨로 이해해 봅시다.
이번 글에서는 컬링된 결과로 얻은 Cluster 를 레스터라이즈 하기 위해서 필요한 RasterBinning 작업과 SW, HW 레스터라이즈 하는 부분은 확인해봅시다.
그런 뒤 레스터라이즈 결과로 생성된 Visibility Buffer 로 부터 현재 프레임 기준 HZB 를 생성합니다. 마지막으로 MainPass 와 거의 동일한 PostPass 를 한번 더 진행합니다.

이전 글에서 이야기 했던 것 처럼 이 글은 총 5개로 구성될 예정입니다.
1. Nanite 1/5 : Nanite 에서 사용하는 주요 기술과 MeshDrawCommand 생성 및 VisibilityBuffer 초기화 과정 리뷰
2. Nanite 2/5 : TwoPassOcclusionCulling 의 전체 레이아웃을 확인하고 MainPass 의 노드 및 클러스터 컬링 리뷰
3. Nanite 3/5 : SW, HW 레스터라이저와 PostPass 리뷰
4. Nanite 4/5 : Visibility Buffer 로 부터 Depth/Stencil 텍스쳐를 생성하는 부분 리뷰
5. Nanite 5/5 : Visibility Buffer 로 부터 G-Buffer 생성하는 MaterialPass 리뷰
3. 내용
3.1. AddPass_Rasterize(MainPass)
AddPass_Rasterize 내부의 내용은 크게 3가지가 있습니다.
1. BasePass 가 소유한 모든 머터리얼에 대해서 FRasterizerPass 를 만듭니다.
2. AddPass_Binning 함수를 호출합니다. 여기서는 렌더링하려는 클러스터 내의 삼각형들과 머터리얼을 연결해줍니다.
- RasterBinMeta 와 RasterBinData 버퍼가 채워지는 데 ClusterIndex 가 주어지면 Cluster 와 연관된 RasterBin 정보를 얻
을 수 있게 해줍니다.
3. Hardware, Software Rasterize 를 수행합니다.
- Rasterize 를 마치면, VisibilityBuffer 가 채워지며 64 bit uint 에 Depth | ClusterIndex | TriangleIndex 를 저장합니다.
3.1.1. FRasterizerPass 준비
이제 실제 AddPass_Rasterize 코드를 봅시다. 먼저 FRasterizerPass 를 만드는 과정을 봅시다.
1. ClusterOffsetSWHW 버퍼를 준비합니다. 이전 과정에서 자주 본 것처럼 PostPass 경우 MainPass 가 생성한 Cluster 뒤쪽에 PostPass 의 Cluster 가 배치되기 때문에 PostPass 의 경우만 ClusterOffset 을 사용한다고 플래그를 설정합니다.
2. BasePass 가 소유한 총 RasterBinCount 를 계산합니다. 이것은 BasePass 에서 사용하는 Unique Material 개수입니다.
3. 우리가 만들 FRasterizerPass 객체 입니다. 어떤 Shader 를 사용할지? 어떤 Material 을 사용하는지? RasterBin 인덱스 등등… 레스터라이즈 패스에 필요한 모든 것을 담고 있습니다. 이 내용은 캐싱하여 재사용 가능하게 준비합니다.
4. FPassData 에 레스터라이즈에 필요한 모든 정보를 다 모읍니다.
- RasterizerPasses 는 이번 레스터라이즈에 필요한 모든 FRasterizerPass 를 담고 있습니다.
- MetaBufferData 에는 레스터라이즈에 필요한 정보가 채워지는데 BinSWCount, BinHWCount 에는 각 머터리얼 당 렌더링해야 할 클러스터가 개수(Vertex Shader 를 사용한 경우). 그리고 레스터라이즈에 필요한 데이터를 인덱싱 할 수 있는 ClusterOffset 정보를 가집니다. 이 ClusterOffset 은 추후 제작할 RasterBinData 에 사용됩니다.
- ActiveRasterBins 는 활성화 된 RasterBin(머터리얼) 정보를 가집니다. (현재는 다 활성화 되었다고 가정하고 볼 예정)
- FixedFunctionPassIndex 는 RasterizerPasses 를 인덱싱 하기 위해서 사용합니다. Programmable RasterBin 이 아닌 경우 레스터라이즈 시 WPO 등으로 픽셀이 이동되지 않을 것입니다. 이런 경우 기본 머터리얼로 레스터라이즈 가능할 것입니다. 그래서 기본 머터리얼로 된 FRasterizerPass 하나를 만들어두고 해당 FixedFunctionPassIndex 로 필요 시 참조 가능하게 합니다.
5. 3번에서 얻은 RasterBinCount 개수만큼 MetaBufferData 를 할당합니다.
6. 강제로 Programmable 을 끄는 경우는 모두 기본 머터리얼로 레스터라이즈 하면 되기 때문에 RasterBins 가 1개만 있어도 될 것입니다. 그렇지 않은 경우 조건문의 else 로 넘어 갑니다. 여기서는 BasePass 가 가진 모든 RasterPipelines (Unique Material) 수 만큼 루프를 반복하며 실제 활성화된 ActiveRasterBins 를 마킹합니다. 우리는 일단 모두 활성화 되었다고 생각하고 봅니다.
7. ActiveBin 의 수가 8개가 넘어가면 비동기 아니면 동기 방식으로 AddSetupTask 에 전달된 람다 함수가 실행됩니다. 일단 동기로 돈다고 생각하고 코드를 봐도 무방할 것 같습니다.
8. Hardware rasterze 에 필요한 VS, MS, PS, CS Shader 에 Permutation 정보를 기록합니다. 크게 중요한 부분은 없어서 함수 내부는 건너뛰겠습니다.
9. 기본 머터리얼로 구성된 FixedMaterial 을 준비합니다. 그리고 FillFixedMaterialShaders 람다 함수를 정의합니다. 이 람다함수는 FRasterizerPass 를 FixedMaterial 로 채워줍니다. 람다함수 내부 구현을 계속해서 봅시다.
10. 여기서는 코드리뷰의 편의를 위해서 Vertex Shader 로 Rasterize 한다고 가정합니다. FHWRasterizeVS 와 FHWRasterzePS 에 필요한 Permutation 정보를 설정하고 실제 해당 Permutation 에 맞는 Shader 를 생성합니다. 이렇게 FixedMaterial 에 대한 HW 레스터라이즈 Shader 를 준비했습니다.
11. FMicropolyRasterizeCS 는 SW 레스터라이즈를 위한 Compute Shader 입니다. 이렇게 FixedMaterial 에 대한 SW 레스터라이즈 Shader 를 준비했습니다.
12. 각각의 Shader 가 사용하는 Material 정보를 FixedMaterial 로 설정합니다.
13. CacheRasterizerPass 람다 함수도 확인해봅시다. 이 함수는 전달받은 FNaniteRasterEntry 를 기반으로 RasterizerPass 를 채웁니다. 그리고 캐싱하여 재사용 시 빠르게 데이터를 준비할 수 있게 해줍니다. 참고로 FNaniteRasterEntry 는 Nanite (1/5) 의 그림8 에서 NaniteSceneProxy 를 FScene 에 등록할 때 추가한 데이터 입니다.
14. 5번 과정에서 할당해둔 MetaBufferData의 MaterialBitFlags 를 채우기 위해 준비합니다.
15. 캐시 된 것이 있다면 RasterMaterialCache 로 부터 정보를 얻고 그렇지 않으면 RasterPipeline 으로 부터 머터리얼을 얻어와서 MaterialBitFlags 를 만들어서 설정합니다. 그리고 이 때 만들어진 내용은 RasterMaterialCache 에 캐싱해 다음에 재사용 하도록 해줍니다. MaterialFlags 는 WPO, PDO, 등등을 사용하는지 여부가 기록 됩니다. 이렇게 생성한 MaterialFlags 를 기반으로 Vertex, Pixel shader 가 Programmable 인지? Tessellation은 사용하는지? 등에 대한 정보를 기록합니다.
16. RasterizeMaterialCache.bFinalize 가 true 이면, 이미 현재 FNaniteRasterEntry 에 대응되는 FRasterizerPass 객체가 캐싱이 완료되었다는 의미입니다. 그 경우 캐시된 데이터를 복사하고 FRasterizerPass 생성 작업을 마칩니다.
17. 만약 캐싱이 되어있지 않고, Programmable 기능을 사용하는 머터리얼의 경우 사용할 Vertex, Pixel, Compute 를 결정하고 사용하는 Material 정보도 준비합니다. 이 정보는 모두 RasterizerPass 에 담겨집니다.
18. 만약 캐싱이 되어있지 않고, Programmable 기능을 사용하지 않는 머터리얼의 경우라면, FixedMaterial 타입입니다. 그래서 9번 과정에서 봤던 람다함수를 호출하여 FixedMaterial 타입의 FRasterizerPass 를 준비합니다.
19. 방금 전까지는 FRasterizerPass 를 생성할 수 있는 람다함수를 봤습니다. 이제 해당 함수를 실제 사용합니다. 먼저 NANITE_RENDER_FLAG_DISABLE_PROGRAMMABLE 인 경우는 모든 클러스터가 FixedMaterial 타입을 사용할 것입니다. GetFixedFunctionPipeline 은 기본 머터리얼을 사용한 경우 필요한 FNaniteRasterPipeline 리턴합니다. 최종적으로 CacheRasterizerPass 함수를 호출하여 FRasterizerPass 를 채웁니다.
20. 이 경우 각각의 BasePass 가 가진 RasterPipelines(유니크 머터리얼 개수 만큼 있음) 만큼 FRasterizerPass 를 생성합니다. 그리고 RasterizerPasses 컨테이너를 유니크 머터리얼 개수로 예약합니다.
21. RasterPipelines 개수 만큼 루프를 돕니다. ActiveRasterBins 은 현재는 모두 Active 상태라고 가정하고 보기 때문에 항상 통과합니다. RasterBInIndex++ 은 여기서 즉시 실행되지 않고 for loop 문의 Scope 를 벗어나는 경우 증가합니다. (즉, 기존 index 기반 for 와 같은 형태로 작동)
22. 이제 FNaniteRasterEntry 로 부터 FRasterizerPass 를 채워봅니다. 먼저 RasterizerPass 을 하나 준비하고, RasterBin 값을 채웁니다. 이 값은 GPU 에서 사용하는 MaterialId 입니다. 특이한 점은 BinIndexTranslator.Translate 함수를 통해서 BinIndex 를 변환시키는데요. Programmable 타입의 경우 BinIndex 를 뒤에서 부터 증가하도록 합니다. 해당 코드는 Nanite(1/5) 의 그림8 부분에 나와있습니다. 현재는 그냥 GPU 에서 매칭할 수 있는 MaterialId 를 RasterBin 에 넣었다. 라고만 생각해도 충분할 것 같습니다. 계속해서 Material 들은 Fixed 타입으로 기본값을 채워주고, 캐싱 된 데이터를 검색하기 위해서 RasterMaterialCacheKey 를 생성합니다.
23. 방금 전 생성한 RasterMaterialCacheKey 를 사용하여 캐싱 데이터를 얻어옵니다. 만약 캐싱한 적이 없다면, 이번에 값을 채울 것이고 있다면 이 것을 사용할 수 있을 것입니다. 이런 작업은 CacheRasterizerPass 함수를 호출하여 FRasterizerPass 를 채우면서 동시에 수행합니다.
24. 각각의 RasterBin(머터리얼)은 Indirect draw argument 를 별도로 가집니다. 왜냐하면 각 머터리얼이 렌더링 해야할 클러스터의 개수 정보가 다를 것이기 때문입니다. 현재 RasterBin 이 사용한 Indirect draw argument 를 버퍼의 Byte offset 을 얻어옵니다. 그리고 만약 현재 추가한 Material 이 Fixed 타입이고, 처음 추가한 Fixed 타입이라면 해당 FRasterizerPass 의 인덱스를 FixedFunctionPassIndex 에 캐싱합니다. Hidden Material 을 사용하는 경우도 해당 플래그를 남겨줍니다.
25. 준비한 FRasterizerPass 의 루프를 돕니다. 여기서는 실제 사용할 Shader 와 Material 이 빈 경우에 대한 추가 처리를 수행합니다. 그리고 처음 캐싱하는 중이라면 캐싱을 완료해줍니다.
26. 현재는 레스터라이즈에 Vertex Shader 를 사용한다고 가정하고 보기 때문에 이쪽 조건문만 보겠습니다. Shader 나 Material 이 비어있는 경우 적절한 데이터로 채워지는 것을 볼 수 있습니다.
27. 캐싱 완료한 적이 없다면, 캐싱 데이터를 복사하고 bFinalized 를 true 로 설정해서 이후에는 캐싱된 데이터를 사용할 수 있도록 해줍니다.

3.1.2. AddPass_Binning(MainPass) 전체 레이아웃
다음으로 AddPass_Binning 함수를 호출합니다. 이 함수를 통해서 얻는 것은 아래와 같습니다.
- RasterMetaData 와 RasterBinData 에 데이터를 채움
-> RasterBinData : RasterBin(MaterialId) 가 레스터라이즈를 수행하는 클러스터 내의 삼각형 범위. (클러스터내에서 다양한 머터리얼을 사용할 수 있기 때문에 삼각형 범위가 중요함)
-> RasterMetaData : RasterBin(MaterialId) 가 그려야 할 SW/HW Cluster Count (VertexShader 의 경우) 그리고 RasterBin 과 연관된 RasterBinData 를 찾기 위한 위한 Offset 정보
AddPass_Binning 은 RasterBinCount, RasterBinReserve, RasterBinScatter 총 3개의 패스로 구성됩니다. 먼저 C++ 코드 쪽의 전체 레이아웃을 보고 각각의 패스의 Shader 코드를 확인해봅시다.
1. FBinningData 에 이 함수의 실행 결과로 생성되는 모든 데이터가 들어갑니다. BinCount 를 BasePass 가 소유한 Unique Nanite Material 수로 설정하고 FixedFunctionBin 을 설정합니다. 이것은 그림1 의 24 에서 구한 PassData.RasterizerPasses[PassData.FixedFunctionPassIndex].RasterBin 에 해당합니다. 사용하는 Nanite material 이 있으므로 BinCount > 0 이기 때문에 조건문 내로 진입합니다.
2. RasterMetaData 를 위한 버퍼를 생성합니다. 그리고 Raster 과정을 위한 Indirect draw argument 버퍼 또한 생성합니다.
3. RasterBinData 버퍼도 생성합니다.
4. RasterBinBuild 패스에 필요한 버퍼를 바인딩 합니다. 컬링에서 살아남은 VisibleClustersSWHW 와 실제 FCluster 가 가진 삼각형 등의 Raw 정보를 담고 있는 ClusterPage 정보, NaniteSceneProxy 생성 시 준비해둔 MaterialSlot 정보(Nanite(1/5) 의 추가그림1 참고), ClusterCount 와 Offset 정보, IndirectArgs 에는 ClusterClassifyArgs 를 바인딩 하는데 ClusterClassifyArgs[0] 에는 SW와 HW 클러스터 수의 합을 64 개의 묶음으로 만드는 경우 몇 개의 묶음인지? 가 기록되어있습니다. 이 IndirectArgs 버퍼는 RasterBinCount Compute shader 를 Dispatch 할 때 사용하는 WorkGroup 개수로 사용됩니다. 그리고 나머지 필요한 정보들을 설정합니다.
5. 필요한 Shader Permutation 정보를 설정하고, RasterBinBuild shader 를 시작합니다. ClusterClassifyArgs 를 사용하여 WorkGroup 을 설정해주며, Dispatch 정보는 (SW cluster count + HW cluster count) 를 64 개로 배치로 한 경우 총 배치 개수가 들어갑니다. 아마 내부에서 64 개의 thread 가 각각의 clsuter 를 처리하나 봅니다. 자세한 내용은 그림3 에서 봅시다.
6. RasterBinReserve 패스를 수행합니다. 패스 수행 전에 RangeAllocatorBuffer 를 만듭니다. 이 버퍼는 uint32 타입이며 RasterBin 이 RasterBinData 의 어느 부분을 사용할 수 있을지 Memroy Offset 정보를 계산하기 위해서 사용됩니다. 이 Offset 은 RasterMetaData 에 ClusterOffset 에 저장됩니다. 이번 패스 또한 Compute Shader 이고 Dispatch 되는 WorkGroup 은 BinCount(Nanite unique material 수) 를 64 개로 묶은 경우 배치 개수 입니다. 자세한 내용은 그림5 에서 봅시다.
7. RasterBinScatterPass 입니다. 이전 과정에서 RasterBinData 정보를 채울 범위를 할당 받았으므로 최종적으로 해당 내용을 기록하는 패스입니다. RasterBinCount 와 같이 ClusterClassifyArgs 를 사용하여 WorkGroup 을 설정해주며, Dispatch 정보는 (SW cluster count + HW cluster count) 를 64 개로 배치로 한 경우 총 배치 개수가 들어갑니다. 자세한 내용은 그림6 에서 확인해봅시다.

RasterBinBuild 쉐이더 코드를 확인해봅시다.
1. RasterBinBuild 함수 내로 진입합니다. 각 WorkGroup 은 64 개를 스레드를 사용합니다. 그렇게 때문에 SV_DispatchThreadID 는 ClusterIndex 가 됩니다.
2. SW, HW 클러스터 수와 현재 처리하는 클러스터가 SW 방식으로 처리될지 여부를 기록합니다. ClusterCount 는 SW+HW 클러스터 수의 합니다.
3. 현재 thread 가 처리중인 Cluster 가 최대 Cluster 범위 내인지 확인하고 조건문 내부로 진입합니다. HW 의 경우에도 0 에서 부터 인덱스를 가질 수 있도록 준비합니다.
4. PrevData 내용은 현재 확인하지 않고 있기 때문에 무시합니다.
5. PostPass 의 경우 기존 MainCluster 의 Cluster 뒤에 기록되기 때문에 그만큼 Offset 을 더합니다.
6. VisibleClusterIndex 를 만드는데, 우리는 PrevData 가 없다고 가정하기 때문에 기존 그대로 RelativeClusterIndex 가 됩니다. 그리고 HW 의 경우 인덱스가 뒤에서 부터 자라나기 때문에 그것을 고려하여 최종 VisibleClusterIndex 를 구해냅니다. 이 것을 사용하여 FVisibleCluster, FInstanceSceneData, FCluster 를 얻어냅니다. FCluster 는 실제 Cluster 가 사용하는 머터리얼 정보와 삼각형 정보들이 포함되어 있습니다. WPO 가 있지만 비활성 된 경우는 bSecondaryBin 을 사용하기 때문에 해당 플래그도 준비합니다(해당 내용은 Nanite(1/5) 6번에 있음).
7. FCluster 가 사용하는 머터리얼이 3개 이하면 FastPath 를 통해 바로 FCluster 의 데이터로 부터 정보를 얻습니다.
7.1. FCluster 는 내부적으로 최대 버택스 수 256, 최대 삼각형 수 128 개를 가집니다. 그리고 Vertices 나 삼각형의 수가 32개 넘어갈 때마다 Batch 하나를 생성합니다. 그림4 에 관련 코드를 모아뒀으니 참고해주세요. GetMaterialRasterBinFromIndex 는 FCluster 의 MaterialIndex 를 사용하여 MaterialSlot 으로 부터 RasterBin 의 인덱스를 얻습니다.
7.2. 만약 Cluster 내에 생성된 삼각현 배치 중 동일한 머터리얼을 사용한다면 해당 배치를 합치는 것이 좋을 것입니다. 그 부분을 수행합니다.
7.3. ExportRasterBin 을 호출하여 RasterBin 과 클러스터내에서 RasterBin 을 사용하는 삼각형의 범위를 저장합니다.
7.4. ExportRasterBin 의 내부를 확인해봅시다.
7.5. RasterBin 의 BinMaterialFlag 를 얻어옵니다. bUseBatch 정보를 설정하는데, HW 방식이고, Mesh나 Primitive Shader 를 사용하며, VertexProgrammable 방식이라면 bUseBatch 가 활성화됩니다. 현재는 VertexShader 쪽으로 분석중이기 때문에 이 값은 항상 0입니다. Tessellation 기능이 켜져서 bDisplacement 가 true 인 경우는 레스터라이즈를 항상 Software 방식으로 동작하도록 하며 bUseBatch 도 사용하도록 설정합니다.
7.6. bUseBatch 를 사용하지 않기 때문에 BatchCount 는 1입니다.
7.7. 현재 RasterBinBuild 과정이기 때문에, #if RASTER_BIN_COUNT 조건 내로 들어가 IncrementRasterBinCount 를 실행합니다.
7.8. IncrementRasterBinCount 내에서는 RasterBinMeta[RasterBin] 의 BinSWCount, BinHWCount 를 BatchCount 개수만큼 증가시켜줍니다. 이 때 bUseBatch 가 false 이므로 BatchCount 는 1 이며 클러스터 당 1 개의 배치로 해당 RasterBin 을 모두 렌더링하는 것을 알 수 있습니다.
8. 이쪽 조건문으로 들어온 경우 머터리얼의 수가 3개 이상이 된 경우입니다. 이 경우 FCluster 에서 데이터를 바로 로드할 수 없고 Cluster 의 Page 로 부터 데이터를 로드합니다. 그리고 머터리얼 테이블 개수만큼 루프를 돕니다.
9. GetMaterialRasterBinFromIndex 로 RasterBin 정보를 얻은 후 Raster 정보를 머지 할 수 있다면 하고 그렇지 않다면 ExportRasterBin 을 호출하여 7.4 에서 한 것과 같은 방식으로 IncrementRasterBinCount 를 호출합니다.


3.1.2.2. RasterBinReserve
RasterBinBuild 과정을 마치면, RasterBinMeta 에는 SW / HW Cluster 의 개수(Vertex Shader 사용 경우), 또는 Vertex Batch 의 개수가 기록되어 있을 것입니다. 여기서는 Vertex Shader 를 보고 있다고 가정하고 코드를 계속 보겠습니다.
1. RasterBinReserve 함수 내부로 진입합니다. 각각의 WorkGroup 은 RasterBin 개수를 64 개로 묶은 경우 묶음의 수고, WorkGroup 내의 thread 는 64 개이기 때문에 SV_DispatchThreadID 는 RasterBinIndex 입니다.
2. RasterBinIndex 가 최대 범위를 넘어가는지 여부를 확인하고 내부 조건문으로 진입합니다.
3. RasterBinIndex 를 GetRasterBinCapacity 에 전달하여 바로 전 과정에서 계산한 SW, HW 의 Cluster 개수의 합을 얻습니다.
3.1. GetRasterBinCapacity 내부 코드를 봅시다. 내부에서는 GetRasterBinCount 를 호출하여 해당 RasterBinMeta[BinIndex] 로 부터 BinSWCount + BinHWCount 를 리턴합니다.
4. 두번째로 AllocateRasterBinRange 함수를 호출합니다. 이 때 SW, HW 클러스터 총합(Vertex shader 의 경우) 도 같이 전달 합니다. 이것으로 얻게 되는 것은 Offset 입니다. 이 Offset 은 RasterBinData 에서 어느 위치에 현재 RasterBin 이 렌더링 할 Cluster 와 Cluster 의 삼각형 범위 정보가 있는지 여부입니다.
4.1. AllocateRasterBinRange 함수에 진입합니다.
4.2. RangeAllocator[0] 은 uint32 변수이며, 현재 RasterBin 이 렌더링 할 데이터를 저장할 메모리 위치를 계산하는데 사용됩니다.
5. 위의 과정에서 구해진 RasterBinOffset 을 SetRasterBinOffset 을 사해 RasterBinMeta[RasterBinIndex].ClusterOffset 에 저장합니다.
5.1. 위의 내용을 SetRasterBinOffset 의 내부를 통해 확인할 수 있습니다.
6. 마지막으로 WriteRasterizerArgsSWHW 를 사용하여 RasterBinArgsSWHW 의 현재 RasterBin 에 해당하는 Indirect draw argument 버퍼를 초기화 합니다.
6.1. WriteRasterizerArgsSWHW 함수 내부도 한번 확인해봅시다. Indirect draw argument 는 총 8개의 uint 로 구성됩니다. 그 중 앞의 4개에는 SW 렌더링을 위한 argument 가 기록됩니다.
6.2. 앞의 4개에 [0] 인덱스에는 NumClustersSW 를 기록합니다. ThreadGroupCountX 라고 된 것을 보면 SW 는 Compute Shader 로 Rasterize 될 것임을 알 수 있습니다.
6.3. HW 이고 Vertex Shader 를 사용하는 경우 [4] 인덱스에는 인스턴스 당 사용하는 버택스 개수, [5] 인덱스에는 인스턴스 개수, [6] 인덱스 에는 시작 버택스 위치인데 항상 처음부터 시작하도록 0 입니다. arguemnt 를 보면 HW 의 경우는 일반 레스터라이즈 파이프라인으로 실행되는 것임을 알 수 있습니다.

3.1.2.3. RasterBinScatter
RasterBinReserve 까지 수행하고 나면 RasterBinData 를 채울 준비를 마치게 됩니다. 이제 RasterBinScatter 를 사용하여 RasterBinData 를 채워봅시다. 이 과정에서는 RasterBin 을 사용하는 Cluster 와 해당 클러스터 내에서도 어떤 삼각형만 레스터라이즈 하는지에 대한 정보를 기록합니다.
RasterBinBuild 패스와 동일하게 RasterBinBuild 함수를 수행합니다. 이 때 다른 점은 ExportRasterBin 을 호출한 경우 #elif RASTER_BIN_SCATTER 조건문 내로 진입한다는 것입니다. 그림3 의 RasterBinBuild 내용에서 RASTER_BIN_SCATTER 나오기 전까지 봐주세요. 그리고 아래는 RASTER_BIN_SCATTER 부분만 확인해봅시다.
1. AllocateRasterBinCluster 는 실제 RasterBinReserve 과정에서 초기화 해둔 RasterBinArgsSWHW 의 정보를 채웁니다. 그리고 RasterBinData 에 기록할 Offset 정보를 계산합니다. 내부로 들어가봅시다.
1.1. 우리는 bUseBatch 가 1이기 때문에 전달 받은 BatchCount 는 1입니다. 먼저 Offset 에 해당 RasterBin 이 사용할 Indirect draw argument 버퍼의 Offset 을 구합니다.
1.2. OutRasterBinArgsSWHW[Offset] 이 Cluster 개수를 기록하는 곳이 되도록 하기 위해서 추가 연산을 합니다. SW 의 경우 [0] 위치이기 때문에 더 이상 해줄 것이 없고, HW 이고 Vertex shader 의 경우 [5] 였습니다.
1.3. 현재 RasterBin 에 대한 Indirect draw argument 에 Cluster 개수를 1 더해줍니다. 이때 Offset 은 SW or HW 에 맞게 이미 설정되어 있을 것입니다. WaveIntrinsic 을 사용하여 Atomic Lock 횟수를 최소화한 아주 좋은 코드 예제 입니다. 이 부분을 분석하는 것도 좋지만 현재는 Nanite 코드 이해에 집중하기 위해서 자세한 내용을 다루진 않겠습니다.
1.4. HW 의 경우 Cluster 의 Offset 이 거꾸로 자라납니다. 그래서 GetRasterBinCapacity 를 통해 현재 RasterBin 이 렌더링할 최대 클러스터 개수를 사용하여 HW 용 ClusterOffset 을 완성합니다. 이번에 구한 ClusterOffset 은 현재 RasterBin 이 사용하는 Cluster 를 기준으로 하는 LocalClusterOffset 입니다.
1.5. GetRasterBinOffset 함수로 RasterReserve 과정에 구한 RasterBinData 의 전역 ClusterOffset 을 구합니다. 여기에 1.4 과정에서 구한 LocalClusterOffset 을 더하여 현재 Cluster 의 정보를 저장할 Offset 을 최종적으로 구합니다.
2. 이제 BatchCount 수 만큼 루프를 도는데, 우리는 bUseBatch 를 사용하지 않는 코드를 보기 때문에 1회 만 실행할 것입니다.
3. 1.5 과정에서 얻은 BinClusterMapping 인덱스를 사용하여 RasterBinData 에 ClusterIndex 과 Cluster 내에서 현재 RasterBin 을 사용하는 삼각형의 범위를 기록합니다.

3.1.3. HW Rasterize
CPU 측의 AddPass_Rasterize 함수내에서 HW Rasterize 를 실행하는 코드를 먼저 확인해보고 VS, PS Shader 를 차례로 확인해봅시다.
1. 레스터라이즈에 필요한 FRasterizePassParameter 를 만듭니다. 이전 과정에서 구한 RasterMetaData 와 RasterBinData 와 Cluster 개수를 기반으로 생성한 Indirect draw argument, Cluster 관련 데이터 등등을 모두 바인딩 합니다. 이 데이터는 SW 레스터라이즈 때에도 재사용 됩니다.
2. HW Rasterize 패스를 RDG 에 추가합니다.
3. RasterizerPasses 개수 만큼(Unique material 개수) 레스터라이즈를 실행할 것인데 없다면 Early exit 합니다.
4. 모든 RasterizerPasses 에 대해서 반복문을 수행합니다.
5. Hidden 이거나 Tessellation 의 경우는 HW 를 사용하지 않습니다.
6. Parameters.ActiveRasterBin 에는 현재 RasterizerPass.RasterBin 을 담아줍니다. 여기서 Parameters 는 1번 과정에서 생성한 FRasterzePassParameter 입니다.
7. 그런 뒤 HW 레스터라이즈를 위해 필요한 파이프라인을 설정하고 Indirect draw argument buffer 를 사용하여 드로콜을 실행합니다. 이때 IndirectOffset 에 16 을 더해주는 부분은 (uint 4 개 * 4 byte) 로 HW Rasterize indirect argument 를 사용하기 위해 추가된 것입니다.

이제 HW Rasterize 의 VertexShader 를 봅시다.
1. HWRasterizeVS 로 진입합니다. SV_VertexID 와 SV_InstanceID 가 들어옵니다. 이 값은 Indirect draw argument 로 부터 자동으로 생성되는 변수입니다. 드로콜이 만들어질 때 HW Indirect draw arguments 는 2가지 정보가 있었습니다. 하나는 인스턴스 당 버택스 개수, 두번째는 인스턴스 개수입니다. 여기서 인스턴스는 Cluster 입니다. 그림 4 의 상단 부분을 봐주세요. 클러스터 당 가질 수 있는 최대 삼각형 숫자는 NANITE_MAX_CLUSTER_TRIANGLES(128) 입니다. 그렇기 때문에 Vertex 수는 128 * 3 = 384 가 됩니다. 그렇다면 Cluster 가 384 개의 버택스를 모두 사용하지 않는다면 어떻게 되나요? 그냥 버려집니다. 계속해서 코드를 봅시다.
2. FTriRange 는 삼각형의 시작 지점과 개수를 멤버변수로 갖고 있습니다. GetIndexAndTriRangeHW 를 호출하여 해당 정보를 얻습니다.
2.1. GetIndexAndTriRangeHW 함수 내부로 들어가면 FetchHWRasterBin 함수를 호출합니다.
2.2. FetchHWRasterBin 함수 내부로 들어가면 RasterBinData[ActiveRasterBin] 로 부터 클러스터 내에서 그려야 할 삼각형의 범위 정보를 추출합니다. 이때 ActiveRasterBin 변수는 그림6 의 6 에서 설정한 값입니다.
3. LocalTriIndex 와 VertexID 를 구합니다.
- LocalTriIndex : 현재 처리 중인 Vertex 가 포함된 삼각형의 인덱스로 Cluster 내부를 기준으로 하기 때문에 LocalTriIndex 로 부름
- VertexID : 현재 처리 중인 삼각형을 기준으로 이 Vertex 가 몇 번째 버택스 인지 여부를 나타내며 0~2 값 중 하나임.
4. VSOut 을 초기화 합니다. 이 때 Out.Position = float4(0, 0, 0, 1); 으로 초기화 하는데 사용하지 않는 Vertex 는 이렇게 처리하여 레스터라이즈 되지 못하도록 퇴화(Degenerate) 시킵니다. 그리고 Cluster, InstanceSceneData, PrimitiveSceneData, NaniteView 등등 필요한 정보들을 준비합니다.
5. 실제 삼각형의 정보를 가져올 수 있는 FCluster 를 준비합니다. 만약 그릴 삼각형의 수가 비어있으면 Clsuter 가 가진 삼각형 수로 설정합니다.
6. 현재 처리중인 버택스가 클러스터가 소유한 삼각형의 범위 내라면 조건문 내로 진입합니다.
7. TriIndex 에 클러스터의 전체 삼각형 기준 삼각형 인덱스를 구합니다. 그리고 DecodeTriangleIndices 를 호출하여 이 삼각형의 Vertex Index 정보를 얻습니다.
8. PixelValue 에 ClusterIndex + 1 값과 삼각형 인덱스 값을 넣어줍니다. 이 값은 추후에 VisibilityBuffer 에 들어가는 값의 일부 입니다.
9. CommonRasterizerVS 를 호출하여 나머지 과정을 수행합니다. 그림9 에서 계속해서 봅시다.

계속해서 CommonRasterizerVS 입니다.
1. FetchAndDeformLocalNaniteVertex 함수를 통해서 FCluster 로 부터 Local space vertex 를 얻어옵니다. 함수 내부 코드는 중요하지 않을 것 같아서 더 추적하지는 않겠습니다.
2. Programmable Vertex Shader 의 경우 머터리얼 쉐이더로 부터 적용할 WorldPositionOffset 정보를 얻어옵니다.
3. Local space vertex 를 World space 로 변환한 후에 바로 전 과정에서 구한 WorldPositionOffset 을 적용합니다. 그리고 Clip space 로 변환합니다. 변환 후에 Clip space 에서 offset, scale 을 적용하는 것 같습니다만 기본 설정은 이 값이 Clip space 공간을 변환시키지 않기 때문에 무시합니다. 그리고 ViewRect 를 설정합니다.
4. PointClipPixel 값을 준비합니다. 이 값은 Pixel Shader 에서 Screen space 좌표 + float2(0.5, 0.5) 위치로 얻을 수 있게 하기 위해서 준비한 값입니다. 마지막으로 PixelValue 와 ViewId 를 설정합니다. PixelValue 에는 ClusterIndex + 1 과 TriangleIndex 가 기록되어 있습니다.
5. Clip space 로 변환한 결과를 Position 변수에 넣어서 하드웨어 레스터라이즈가 실행 될 수 있도록 합니다.
6. Vertex shader 위해 채워진 값을 리턴 합니다.

계속해서 HW Rasterize 의 픽셀 쉐이더 부분입니다.
1. 그림9 의 3 에서 구한 PointClipPixel 을 사용하여 SvPosition 을 구합니다.
2. VisibilityBuffer 에 저장할 PixelValue 를 추출합니다.
3. VERTEX_TO_TRIANGLE_MASKS 는 사용하지 않으므로 건너뜁니다.
4. 레스터라이즈 결과가 ViewRect 범위 내에 들어온다면 조건문 내로 진입 합니다.
5. SvPosition.z 로 부터 DeviceZ 를 얻습니다. 이 값 또한 VisibilityBuffer 에 기록됩니다.
6. FVisBufferPixel 객체에 PixelPos, PixelValue, DeviceZ 정보를 넘겨 VisibilityBuffer 에 값을 기록할 준비를 합니다.
7. Pixel.WriteOverdraw() 는 오버드로우를 체크하기 위한 함수로 Visualize 활성 시에만 의미가 있습니다.
8. 기존 기록된 Depth 값과 현재 Depth 값을 비교하여 기록해야 하는지 확인하고 필요 없다면 더 이상 진행하지 않습니다.
9. Mesh or Prim Shader 를 사용하지 않는다면 BARYCENTRIC_MODE_EXPORT 로 들어오게 됩니다. Baricentrics.UVW 를 구합니다. 여기서 구한 Baricentrics 정보를 기반으로 현재 처리중인 Pixel 에 대한 FMaterialPixelParameters 를 구합니다. FetchNaniteMaterialPixelParameters 내부에서는 TexCoord, VertexColor, WorldPosition 등등의 정보를 Baricentrics 를 사용하여 보간하여 구합니다. 이 부분도 크게 중요하지 않은 것 같아서 자세한 내용을 다루진 않을 것입니다.
10. 이제 FMaterialPixelParameters 를 얻었습니다. 이 정보를 기반으로 머터리얼 에디터에서 만든 쉐이더를 실행하기 위해서 CalcMaterialParameters 함수에 전달하여 필요한 연산을 수행합니다. 그리고 PixelDepthOffset 도 적용합니다.
11. 마지막으로 Write 함수를 호출해서 해당 부분을 따라가면 결국 WritePixel 함수를 호출합니다. 여기서 VisibilityBuffer 에 데이터를 기록합니다. 기록할 때 InterlockedMax 로 기록하는 것을 볼 수 있습니다. 이것은 Depth 테스트를 위한 기능입니다. Visibility Buffer 는 Depth | ClusterIndex + 1 | TriangleIndex 로 구성되기 때문에 Depth 가 가장 상위 비트를 차지합니다. 상위 비트의 Depth 를 기준으로 Depth 가 더 큰 값을 가진 픽셀이(더 카메라에 근접한 픽셀이) 살아남을 수 있도록 하는 것이 이 코드의 목적입니다.

이제 SW Raterize 코드를 확인해봅시다. 먼저 CPU 측에서 렌더커맨드를 생성하는 부분입니다.
1. HW Rasterize 와 동일하게 모든 RasterizePass 가 있는지 비교하고 Early exit 을 수행합니다.
2. 그리고 모든 RasterizerPasses 에 대해서 순회합니다. 이 때 Hidden 이거나 Shader 가 빈 경우 스킵합니다.
3. HW Rasterize 와 같이 Parameters.ActiveRasterBin 을 설정해줍니다.
4. Indirect draw argument 버퍼를 사용하여 Dispatch 함수를 호출합니다.

이제 Software Rasterizer 의 Compute shader 쪽을 보겠습니다.
1. MicropolyRasterize 함수에 진입 합니다. 이 때 THREADGROUP_SIZE 는 NANITE_VERT_REUSE_BATCH 사용 여부에 따라 결정됩니다. NANITE_VERT_REUSE_BATCH 사용하는 경우 32, 그렇지 않은 경우 64 가 됩니다. SW Raterize 는 Programmable 타입을 사용하는 경우 NANITE_VERT_REUSE_BATCH 를 활성화 합니다. 활성화 되었다고 가정하고 코드를 봅시다.
2. ClusterRasterize 함수를 호출합니다. 전달되는 GroupID 는 WrokGroup 의 인덱스로 ClusterIndex 입니다. GroupIndex 는 WorkGroup 내의 thread 인덱스로 NANITE_VERT_REUSE_BATCH 를 사용하기 때문에 [0, 31] 중 하나의 값이 될 것입니다.
3. ClusterRasterize 함수로 진입합니다. HW Raterize 때와 마찬가지로 GetIndexAndTriRangeSW 함수를 사용하여 현재 RasterBin 이 VisibleIndex 의 Cluster 내에서 렌더링 해야 하는 삼각형의 범위를 구합니다.
4. FVisibleCluster, FInstanceSceneData, FPrimitiveSceneData, FNaniteView 등등 필요한 정보들을 로드합니다. 그리고 HW 때와 마찬가지로 FCluster 정보를 얻어오고 삼각형 개수가 없다면 Clsuter 전체 삼각형 수로 설정해줍니다.
5. FMaterialShader 에 필요한 정보들을 채웁니다. CalculateNaniteVertexTransforms 는 Nanite Vertex 를 변환하기 위해서 필요한 각종 Matrix 정보들이 있습니다.
6. Raster 에 필요한 Viewport 정보를 담습니다. ViewportScale, ViewBias, ScissorRect 정보를 만듭니다.
7. 우리는 테셀레이션은 없다고 가정하고 코드를 보기 때문에 NANITE_PIXEL_PROGRAMMABLE 쪽으로 넘어옵니다. 이 부분은 그림13 에서 다루겠습니다. 만약 PROGRAMMABLE 이 아닌 경우라면 NANITE_VERT_REUSE_BATCH 를 사용하지 않을 것이고 THREADGROUP_SIZE 도 64 일 것입니다.

1. NANITE_PIXEL_PROGRAMMABLE 를 사용하는 경우 TSlidingWindowVertexCache 를 사용합니다. 이 객체는 32개의 Thread 가 각각의 1개의 Vertex 를 변환 시킨 다음, 이웃 Thread 에서 Transform 한 Vertex 가 있다면 가져다 쓰는 방식으로 구현되어 있습니다. 한 가지 가정이 있는데 이웃 인덱스에서 변환 된 Vertex 를 가져올 때 현재 인데스와 이웃 인덱스의 차이가 WindowSize(32) 이상 나지 않는다는 가정을 하고 구현되어 있습니다. 그림14 의 주석과 PullExisting 함수 내부 구현중 초록색 네모를 참고해주세요.
2. 각각의 Thread 는 삼각형 한 개를 담당하는 것을 알 수 있습니다. TriIndex 에 현재 클러스터 기준 삼각형 인덱스와 bTriValid 에 현재 처리중인 삼각형이 범위를 넘어섰는지 여부를 기록합니다.
3. 처리 가능한 삼각형이라면, 삼각형의 VertexIndex 정보를 얻습니다.
4. VertexCache.PullExisting 에서는 이전에 변환된 Vertex 정보 중 내가 쓸 수 있는 것이 있다면 가져다 씁니다. 2번에서 각 Thread 는 삼각형 1개를 담당하고 있다고 했습니다. 하지만 VertexCache 를 사용할 때는 각 Thread 가 Vertex 1 개를 담당합니다.
5. 이제 각각의 32개 Thread 가 VertexCache.CacheVert 에 자신이 맡은 삼각형을 변환 시킵니다.
6. PullRemaining 에서는 이웃이 변환한 Vertex 중 내가 사용하는 것이 있으면 가져옵니다. 그림14의 PullRemaining 함수 내에 초록색 네모 영역이 바로 그 부분입니다.
7. 이제 삼각형을 구성하는데 필요한 변환된 Vertex 3 개를 모두 구했습니다. MaterialShader 에 넣어줍니다.
8. FRasterTri 객체를 만들어서 삼각형이 커버하는 영역을 Rasterize 할 수 있도록 준비합니다. SetupTriangle 내부를 자세히 다루지는 않겠습니다.
9. HW 때와 마찬가지로 VisibilityBuffer 에 저장할 데이터를 준비합니다. PixelValue 는 ClusterIndex + 1 과 TriIndex 를 저장합니다.
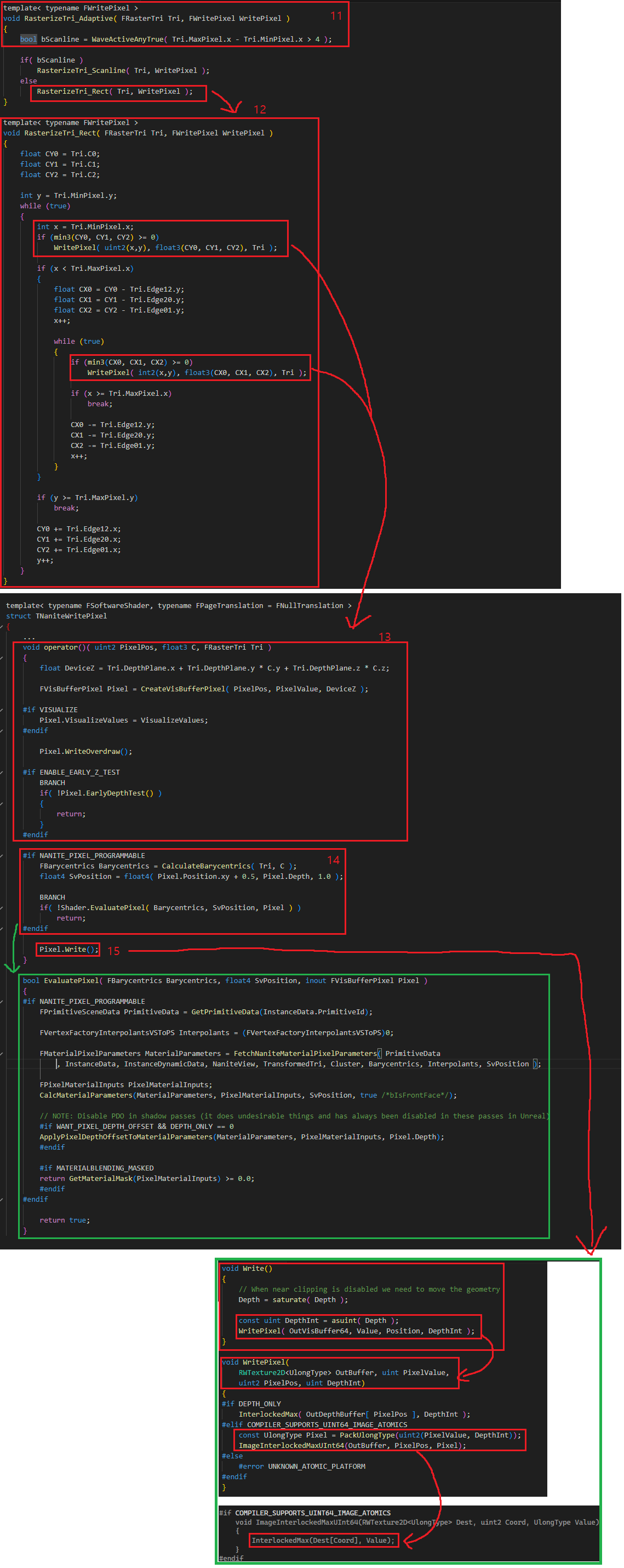
10. RasterizeTri_Adaptive 함수를 호출하여 레스터라이즈를 수행합니다. 그림15 에서 계속 추적해봅시다.


11. 삼각형의 크기가 일정 크기보다 크다면 Scanline 방식, 그렇지 않은 경우 Rect 방식으로 레스터라이즈를 수행합니다.
12. 간단할 것 같은 Rect 방식으로 들어가봅시다. x, y 를 MinPixel 부터 MaxPixel 까지 증가시키면서 WritePixel 함수를 호출하는 것을 볼 수 있습니다.
13. WritePixel 함수를 타고 들어가면 TNaniteWritePixel 의 operator() 내부로 들어옵니다. Tri.DepthPlane 으로 부터 Depth 값을 얻고, FVisBufferPixel 에 PixelPos, PixelValue, DeviceZ 를 전달합니다. HW 와 같이 WriteOverdraw(), EarlyDepthTest() 를 호출합니다.
14. 마지막으로 EvaluatePixel 함수에서 FetNaniteMaterialPixelParameters 함수를 호출하여 FMaterialPixelParameters 를 구합니다. CalcMaterialParameters 와 PixelDepthOffset 을 적용하고 Masked Material 의 경우 discard 를 처리할지 여부를 확인합니다.
15. 모든 과정을 통과하면 Write 함수를 호출하여 WritePixel 함수를 통해 VisibilityBuffer 에 평가된 데이터를 기록합니다. 여기서도 HW 와 마찬가지로 VisibilityBuffer 에 저장할 데이터의 상위 비트에 Depth 값을 넣고 InterlockedMax 함수를 사용하여 데이터를 저장해 Depth Buffer 를 사용하여 기록하는 것과 같은 효과를 내도록 합니다.
3.2. 현재 프레임 기반 HZB 생성
HZB 생성 과정은 쉐이더 코드까지 자세히 다루진 않고 CPU 측에서 어떻게 호출되는지만 확인해봅시다.
1. BuildPreviousOccluderHZB 패스에서는 MainPass 에서 생성된 Visibility Buffer 로 부터 HZB 를 생성합니다.
2. 생성한 HZB 를 CullingParameters 에 바인딩하는 것을 볼 수 있습니다.
3. 이제 PostPass 를 진행하며, MainPass 와 비슷한 과정을 반복합니다.

3.3. PostPass 와 MainPass 의 차이점 정리
PostPass 는 MainPass 와 대부분의 코드를 공유합니다. 그래서 차이점을 정리한 뒤 다시 Nanite(1/2) 의 MainPass 를 리뷰해보는 것으로 충분할 것 같습니다. InstanceCulling 과 NodeAndClusterCulling 부분이 다르기 때문에 해당 부분을 집중적으로 확인해봅시다.
3.3.1. FInstanceCull_CS 차이
- FInstanceCull_CS::FParameter 설정할 때, OutOccludedInstances 와 OutOccludedInstancesArgs 설정하지 않음.
- FInstanceCull_CS→IndirectArgs = OccludedInstancesArgs 를 설정하여 Indirect draw 를 사용함. Occluded 된 인스턴스만 다시 체크하기 위해서 임.
3.3.2. InstanceCull Shader 차이
- MainAndPostNodesAndClusterBatches 등을 저장할때 PostPass 에 맞는 인덱스에 저장하도록 함.
- QueueState 사용 시에도 PostPass 에서 사용하는 인덱스에 Offset 정보를 저장하도록 함.
3.3.3. FNodeAndClusterCull_CS 차이
VisibleClustersArgsSWHW 에 PostRasterizeArgsSWHW 를 바인딩하며, OffsetClustersArgsSWHW 에 MainRasterizeArgsSWHW 를 바인딩 함.
3.3.4. FNodeAndClusterCull_CS Shader 차이
- ProcessCluster 수행 중 bUseHWRaster 여부 파악 할 때 SmallEnoughToDraw 함수 사용하지 않고 MainPass 에서 전달해준 Flag 그대로 사용함.
- VisibleClustersSWHW 에 VisibleCluster 정보를 저장할 때, 기존 MainPass 에서 기록한 내용이 있기 때문 OffsetClustersArgsSWHW(MainRasterizeArgsSWHW) 를 사용해 Offset 을 더해줌.
- Occlued 된 Cluster 를 MAinAndPostCandidiateClusters 에 기록하지 않음. 더 이상 재차 확인할 패스가 없기 때문임.
- GroupOccludedBitmask 를 사용하지 않음. 자식 노드 중 Occluded 된 경우가 있는 경우 PostPass 에서 다시 체크해보기 위해 사용하지만 더이상 재차 확인할 패스가 없기 때문에 사용안함.
이전글 [UE5] Nanite (2/5)
다음글 [UE5] Nanite (4/5)
4. 레퍼런스
1. https://github.com/EpicGames/UnrealEngine/commit/072300df18a94f18077ca20a14224b5d99fee872
2. https://www.youtube.com/watch?v=eviSykqSUUw (Slide link)
3. https://docs.unrealengine.com/5.0/en-US/nanite-virtualized-geometry-in-unreal-engine/
4. https://scahp.tistory.com/126
5. https://scahp.tistory.com/127
'UE4 & UE5 > Rendering' 카테고리의 다른 글
| [UE5] Nanite (5/5) (5) | 2024.03.25 |
|---|---|
| [UE5] Nanite (4/5) (1) | 2024.03.23 |
| [UE5] Nanite (2/5) (0) | 2024.03.21 |
| [UE5] Nanite (1/5) (3) | 2024.03.14 |
| [UE5] D3D12 ResourceAllocation 리뷰(2/2) (0) | 2023.08.24 |



